
cat 및 tac 명령은 텍스트 파일의 내용을 표시하지만 눈에 보이는 것보다 더 많은 것이 있습니다. 조금 더 깊이 파고들어 생산적인 Linux 명령줄 트릭을 배우십시오.
이것들은 두 개의 간단한 작은 명령으로, 실제 사용하기에는 너무 단순하여 그냥 그런 것으로 치부되는 경우가 많습니다. 그러나 파일을 사용할 수 있는 다양한 방법을 알게 되면 파일 작업과 관련하여 무거운 작업을 충분히 수행할 수 있다는 것을 알게 될 것입니다.
목차
고양이 명령
고양이는 익숙하다 텍스트 파일의 내용을 검사, 파일의 일부를 결합하여 더 큰 파일을 형성합니다.
한때 – 전화접속 시대로 돌아가 모뎀—이진 파일은 다운로드를 쉽게 하기 위해 종종 여러 개의 작은 파일로 나뉩니다. 하나의 큰 파일을 다운로드하는 대신 각 작은 파일을 다시 가져옵니다. 단일 파일을 올바르게 다운로드하지 못한 경우 해당 파일을 다시 검색하면 됩니다.
물론, 작은 파일 모음을 다시 단일 작동 바이너리 파일로 재구성하는 방법이 필요했습니다. 그 과정을 연결이라고 했습니다. 그리고 그것이 고양이가 등장한 곳이며 그 이름을 얻은 곳입니다.
광대역 및 광섬유 연결로 인해 삐걱 거리는 전화 접속 소리와 마찬가지로 특정 요구 사항이 사라지므로 오늘 고양이가해야 할 일은 무엇입니까? 꽤 많습니다.
텍스트 파일 표시
cat이 터미널 창에 텍스트 파일의 내용을 나열하도록 하려면 다음 명령을 사용합니다.
파일이 텍스트 파일인지 확인하십시오. 바이너리 파일의 내용을 터미널 창에 나열하려고 하면 결과를 예측할 수 없습니다. 잠긴 터미널 세션 또는 더 나쁜 상태로 끝날 수 있습니다.
cat poem1.txt

터미널 창에 시1.txt 파일의 내용이 표시됩니다.
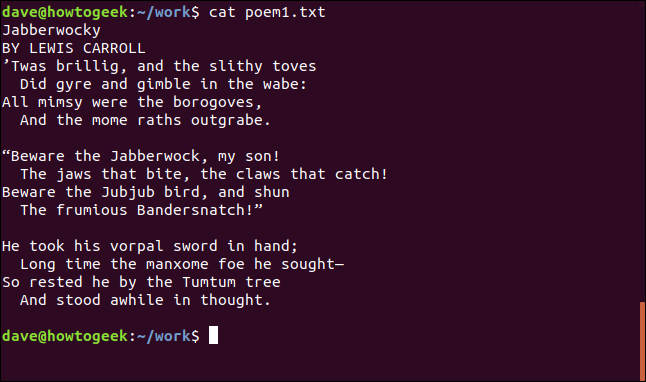
그것은 유명한 시의 절반에 불과합니다. 나머지는 어디에 있습니까? 여기에poem2.txt라는 또 다른 파일이 있습니다. 하나의 명령으로 여러 파일의 내용을 고양이 목록으로 만들 수 있습니다. 명령줄에 파일을 순서대로 나열하기만 하면 됩니다.
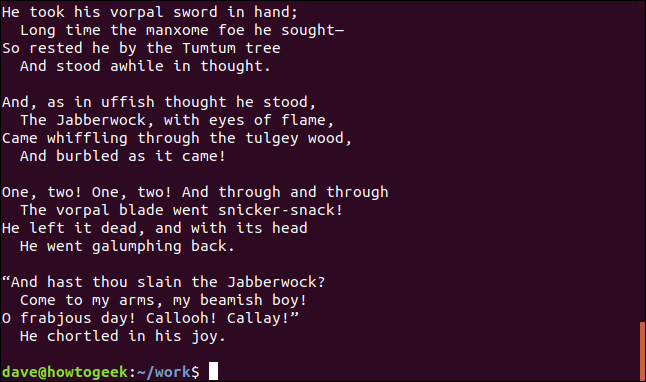
cat poem1.txt poem2.txt

그게 더 좋아 보입니다. 우리는 지금 전체 시를 가지고 있습니다.
고양이 사용하기
시는 모든 것이 있지만 처음 몇 구절을 읽기에는 너무 빨리 창 너머로 날아갔습니다. cat의 출력을 less로 파이프하고 원하는 속도로 텍스트를 스크롤할 수 있습니다.
cat poem1.txt poem2.txt | less

이제 두 개의 개별 텍스트 파일에 저장되어 있어도 하나의 스트림에서 텍스트를 앞뒤로 이동할 수 있습니다.

파일의 줄 번호 매기기
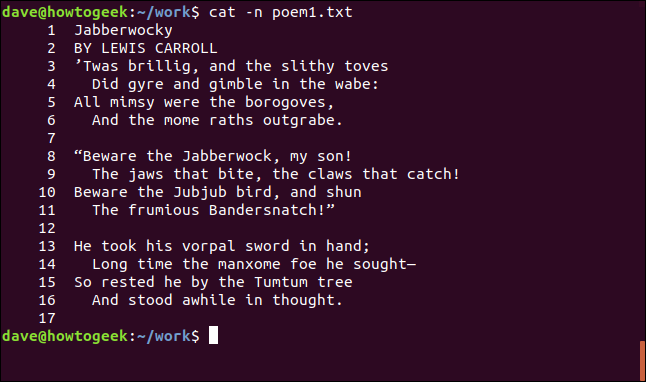
파일에 표시된 대로 고양이 번호 행을 가질 수 있습니다. 이를 위해 -n(숫자) 옵션을 사용합니다.
cat -n poem1.txt

라인은 터미널 창에 표시되는 대로 번호가 매겨집니다.
빈 줄에 번호를 매기지 마십시오
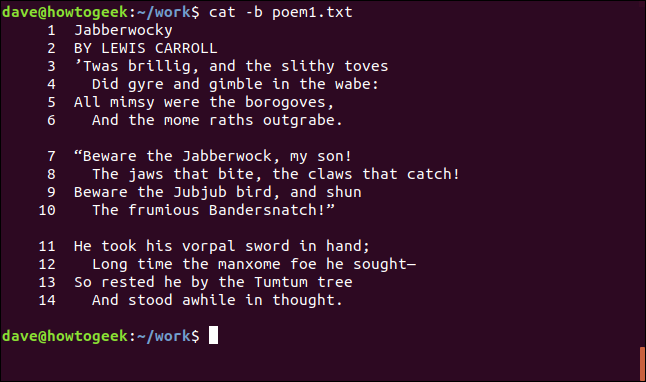
우리는 고양이로 줄 번호를 매길 수 있었지만 구절 사이의 빈 줄도 계산됩니다. 텍스트 줄에 번호가 매겨지지만 빈 줄을 무시하려면 -b(공백이 아닌 숫자) 옵션을 사용합니다.
cat -b poem1.txt

이제 텍스트 줄에 번호가 매겨지고 공백 줄은 건너뜁니다.
여러 개의 빈 줄을 표시하지 않음
파일에 연속적인 빈 줄 섹션이 있는 경우 cat에게 하나의 빈 줄을 제외한 모든 것을 무시하도록 요청할 수 있습니다. 이 파일을 보세요.
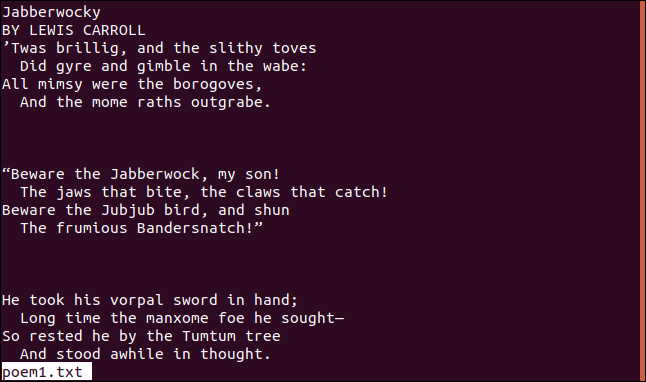
다음 명령은 cat이 빈 줄의 각 묶음에서 하나의 빈 줄만 표시하도록 합니다. 이를 달성하기 위해 필요한 옵션은 -s(squeeze-blank) 옵션입니다.
cat -s poem1.txt

이것은 어떤 식으로든 파일의 내용에 영향을 미치지 않습니다. 고양이가 파일을 표시하는 방식만 변경합니다.
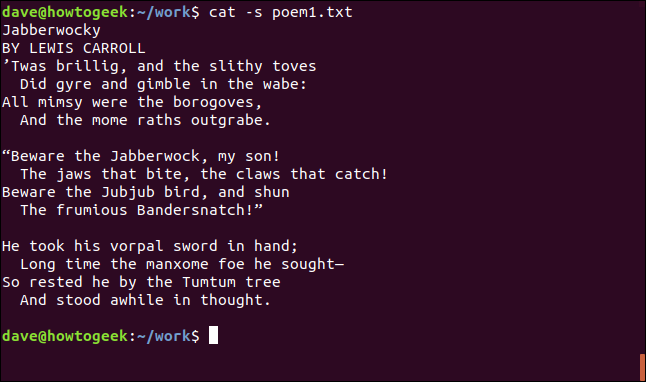
디스플레이 탭
공백이 공백으로 인해 발생하는지 탭으로 인해 발생하는지 알고 싶다면 -T(show-tabs) 옵션을 사용하여 알 수 있습니다.
cat -T poem1.txt

탭은 “^I” 문자로 표시됩니다.
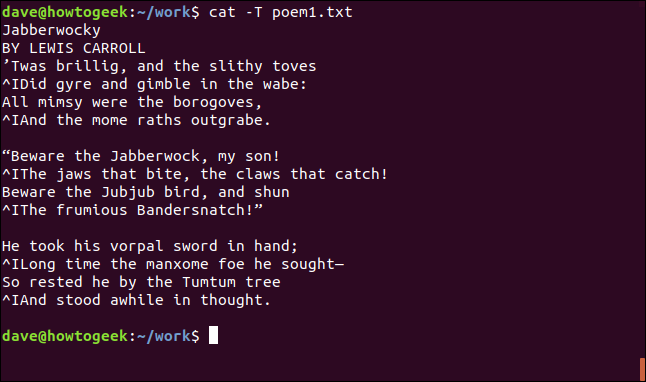
줄 끝 표시
-E(show-ends) 옵션을 사용하여 후행 공백을 확인할 수 있습니다.
cat -E poem1.txt

줄의 끝은 “$” 문자로 표시됩니다.
파일 연결
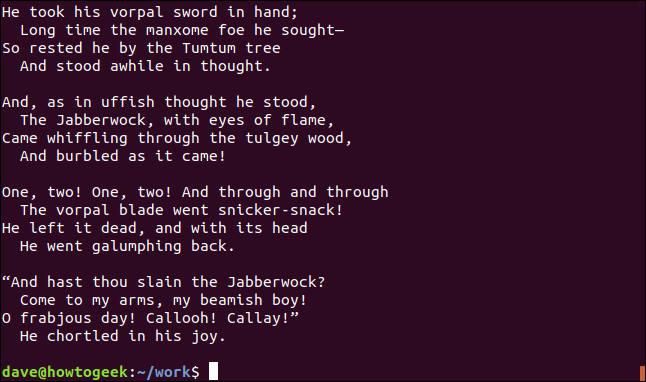
시를 두 개의 파일에 저장하고 각 파일에 절반씩 저장하는 것은 이치에 맞지 않습니다. 그것들을 함께 결합하여 전체 시가 포함된 새 파일을 만들어 봅시다.
cat poem1.txt poem2.txt > jabberwocky.txt

새 파일에는 다른 두 파일의 내용이 포함되어 있습니다.
기존 파일에 텍스트 추가
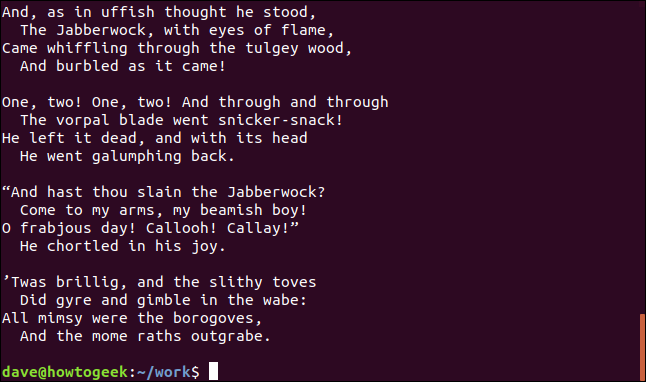
그게 더 좋긴 한데, 사실 그게 시 전체가 아니에요. 마지막 구절이 없습니다. Jabberwocky의 마지막 구절은 첫 구절과 동일합니다.
파일에 첫 번째 구절이 있는 경우 이를 jabberwocky.txt 파일의 맨 아래에 추가하면 완전한 시를 갖게 됩니다.
이 다음 명령에서는 >가 아니라 >>를 사용해야 합니다. 단일 >를 사용하는 경우 jabberwocky.txt를 덮어씁니다. 우리는 그렇게 하고 싶지 않습니다. 맨 아래에 텍스트를 추가하고 싶습니다.
cat first_verse.txt >> jabberwocky.txt

그리고 마지막으로 시의 모든 부분이 함께 있습니다.
표준 입력 리디렉션
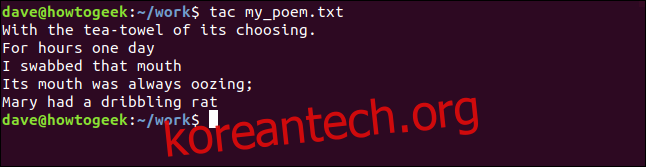
cat을 사용하여 키보드의 입력을 파일로 리디렉션할 수 있습니다. 입력한 모든 내용은 Ctrl+D를 누를 때까지 파일로 리디렉션됩니다. 파일을 생성(또는 파일이 있는 경우 덮어쓰기)하고 싶기 때문에 단일 >를 사용한다는 점에 유의하십시오.
cat > my_poem.txt

멀리 떨어진 터빈 같은 소리는 아마도 루이스 캐롤이 무덤에서 고속으로 회전하는 소리일 것입니다.
전술 명령
tac는 cat과 비슷하지만 파일의 내용을 나열합니다. 역순으로.
다음을 살펴보겠습니다.
tac my_poem.txt

그리고 파일은 터미널 창에 역순으로 나열됩니다. 이 경우 문학적 가치에는 영향을 미치지 않습니다.
stdin과 함께 tac 사용
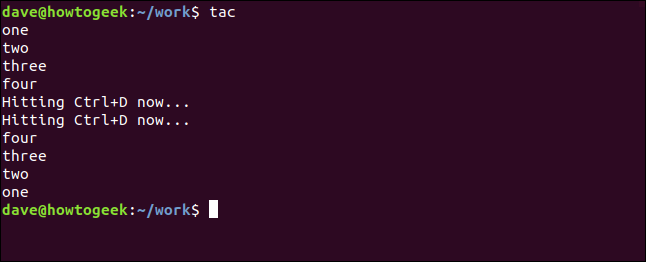
파일 이름 없이 tac를 사용하면 키보드 입력에서 작동합니다. Ctrl+D를 누르면 입력 단계가 중지되고 tac은 입력한 내용을 역순으로 나열합니다.
tac

Ctrl+D를 누르면 입력이 반전되어 터미널 창에 나열됩니다.
로그 파일과 함께 tac 사용
낮은 등급의 응접실 트릭 외에도 tac이 유용한 작업을 수행할 수 있습니까? 예, 그럴 수 있습니다. 많은 로그 파일은 파일 맨 아래에 최신 항목을 추가합니다. tac(그리고 반직관적으로 head)를 사용하여 터미널 창에 마지막 항목을 표시할 수 있습니다.
우리는 tac를 사용하여 syslog 파일을 역순으로 나열하고 헤드에 파이프합니다. head에게 받은 첫 번째 줄만 인쇄하도록 지시함으로써(tac 덕분에 파일의 마지막 줄임) syslog 파일의 최신 항목을 볼 수 있습니다.
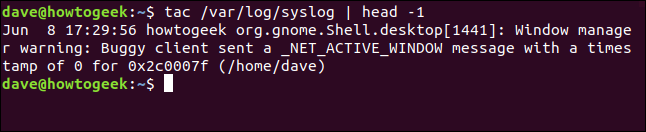
tac /var/log/syslog | head -1

head는 syslog 파일의 최신 항목을 인쇄한 다음 종료합니다.
head는 우리가 요청한 대로 한 줄만 인쇄하지만 줄이 너무 길어서 두 번 감쌉니다. 그렇기 때문에 터미널 창에서 3줄의 출력처럼 보입니다.
텍스트 레코드와 함께 tac 사용
tac의 마지막 트릭은 아름다움입니다.
일반적으로 tac은 텍스트 파일에 대해 아래에서 위로 한 줄씩 작업하여 작동합니다. 줄은 줄 바꿈 문자로 끝나는 일련의 문자입니다. 그러나 우리는 tac이 다른 구분 기호와 함께 작동하도록 지시할 수 있습니다. 이를 통해 텍스트 파일 내의 데이터 "덩어리"를 데이터 레코드로 취급할 수 있습니다.
검토하거나 분석해야 하는 일부 프로그램의 로그 파일이 있다고 가정해 보겠습니다. 더 적은 형식으로 살펴보겠습니다.
less logfile.dat

보시다시피 파일에 반복되는 형식이 있습니다. 3줄의 순서가 있다. 16진수 가치. 16진수 세 줄의 각 세트에는 "=SEQ"로 시작하는 레이블 줄이 있고 그 뒤에 일련의 숫자가 옵니다.
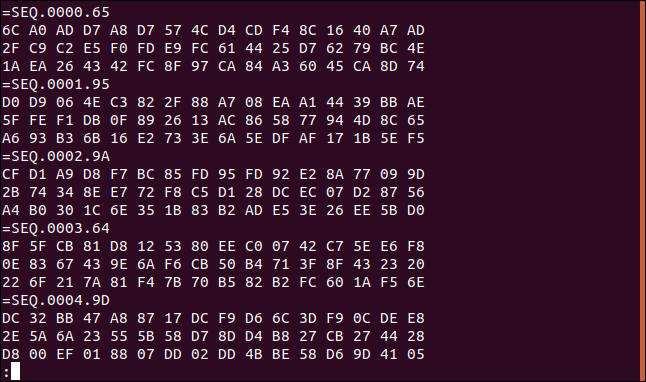
파일의 맨 아래로 스크롤하면 이러한 레코드가 많이 있음을 알 수 있습니다. 마지막 번호는 865입니다.
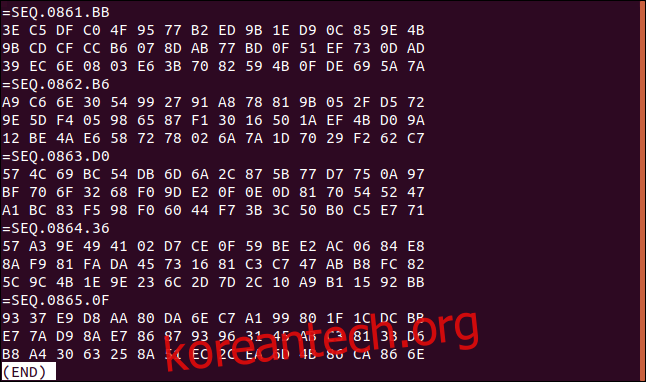
어떤 이유로든 이 파일을 데이터 레코드별로 역순으로 처리해야 한다고 가정해 봅시다. 각 데이터 레코드에 있는 3개의 16진수 행의 행 순서는 유지되어야 합니다.
파일의 마지막 세 줄은 16진수 값 93, E7, B8로 시작하는 순서대로 작성합니다.
tac를 사용하여 파일을 뒤집습니다. 파일이 너무 길기 때문에 파이프로 줄여보겠습니다.
tac logfile.dat | less

그러면 파일이 반전되지만 우리가 원하는 결과는 아닙니다. 파일이 반전되기를 원하지만 각 데이터 레코드의 행은 원래 순서대로 있어야 합니다.
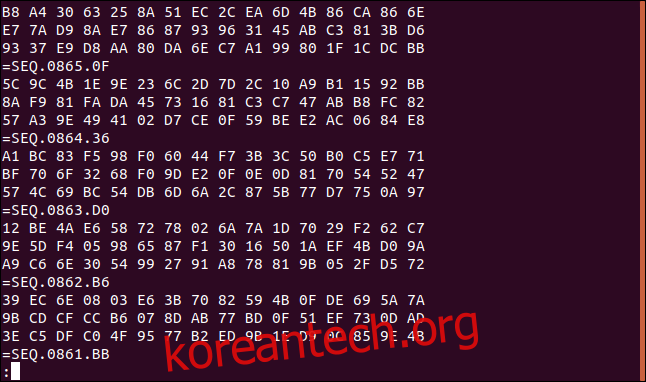
파일의 마지막 세 줄은 16진법 값 93, E7, B8로 시작하는 순서대로 시작한다고 앞서 기록했습니다. 해당 라인의 순서가 역전되었습니다. 또한 "=SEQ" 행은 이제 3개의 16진수 행의 각 세트 아래에 있습니다.
구조에 전술.
tac -b -r -s ^=SEQ.+[0-9]+*$ logfile.dat | less

분해해 봅시다.
-s(구분자) 옵션은 tac에게 레코드 사이의 구분 기호로 사용하려는 것을 알려줍니다. 이것은 tac에게 일반적인 개행 문자를 사용하지 않고 대신 구분 기호를 사용하도록 지시합니다.
-r(regex) 옵션은 tac에게 구분자 문자열을 정규식.
-b(이전) 옵션을 사용하면 tac가 각 레코드 뒤(기본 구분 기호, 줄 바꿈 문자의 일반적인 위치) 대신 구분 기호를 나열합니다.
-s(구분자) 문자열 ^=SEQ.+[0-9]++$는 다음과 같이 해독됩니다.
^ 문자는 줄의 시작을 나타냅니다. 뒤에 =SEQ.+가 옵니다.[0-9]+*$. 이것은 tac가 "=SEQ"가 나타날 때마다 찾도록 지시합니다. 행의 시작 부분에 숫자 시퀀스가 옵니다(로 표시됨). [0-9]) 및 그 뒤에 다른 문자 집합(*$로 표시됨)이 옵니다.
우리는 평소와 같이 전체를 더 적게 파이핑하고 있습니다.
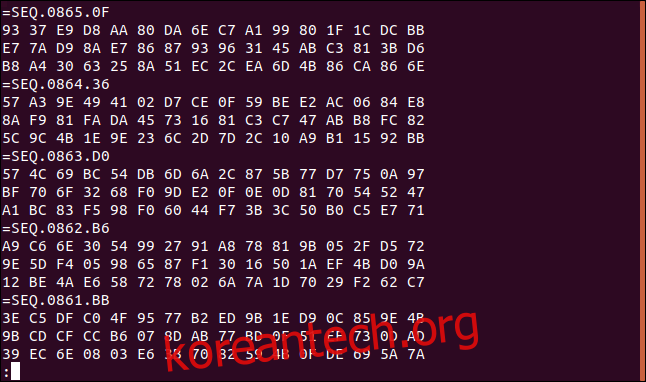
이제 파일은 16진수 데이터의 세 줄 앞에 나열된 각 "=SEQ" 레이블 줄과 함께 역순으로 표시됩니다. 16진수 값의 세 줄은 각 데이터 레코드 내에서 원래 순서대로 있습니다.
우리는 이것을 간단하게 확인할 수 있습니다. 16진수의 처음 세 줄(파일이 반전되기 전 마지막 세 줄)의 첫 번째 값은 이전에 기록했던 93, E7, B8의 순서대로 값과 일치합니다.
그것은 터미널 창 한 줄짜리에 대한 꽤 트릭입니다.
모든 것에는 목적이 있다
Linux 세계에서는 겉보기에 가장 단순한 명령과 유틸리티라도 놀랍고 강력한 속성을 가질 수 있습니다.
단순한 유틸리티의 디자인 철학 한 가지를 잘하는 것, 그리고 다른 유틸리티와 쉽게 상호 작용하는 tac와 같은 이상한 작은 명령이 발생했습니다. 얼핏 보기에는 좀 이상해 보입니다. 그러나 표면 아래를 들여다보면 자신에게 유리하게 활용할 수 있는 예상치 못한 힘이 있습니다.
또는 다른 철학에 따르면 “뱀이 뿔이 없다고 멸시하지 말라 누가 그것이 용이 되지 아니하리라 하겠느냐”