

바이너리 또는 데이터 파일 내의 텍스트를 보고 싶으십니까? Linux 문자열 명령은 “문자열”이라고 하는 이러한 텍스트 비트를 가져옵니다.
Linux는 문제를 찾는 솔루션처럼 보일 수 있는 명령으로 가득 차 있습니다. strings 명령은 확실히 그 진영에 속합니다. 그것의 목적은 무엇입니까? 바이너리 파일 내에서 인쇄 가능한 문자열을 나열하는 명령에 대한 포인트가 있습니까?
한 발 뒤로 물러나자. 프로그램 파일과 같은 이진 파일에는 사람이 읽을 수 있는 텍스트 문자열이 포함될 수 있습니다. 그러나 어떻게 그들을 볼 수 있습니까? cat 이하를 사용하는 경우 중단된 터미널 창이 나타날 수 있습니다. 텍스트 파일과 함께 작동하도록 설계된 프로그램은 인쇄할 수 없는 문자가 입력되면 잘 대처하지 못합니다.
바이너리 파일 내의 대부분의 바이트는 사람이 읽을 수 없으며 의미가 있는 방식으로 터미널 창에 인쇄할 수 없습니다. 영숫자, 구두점 또는 공백에 해당하지 않는 이진 값을 나타내는 문자나 표준 기호는 없습니다. 통칭하여 “인쇄 가능한” 문자라고 합니다. 나머지는 “인쇄할 수 없는” 문자입니다.
따라서 텍스트 문자열에 대한 바이너리 또는 데이터 파일을 보거나 검색하는 것은 문제입니다. 그리고 그것이 문자열이 들어오는 곳입니다. 파일에서 인쇄 가능한 문자열 다른 명령이 인쇄할 수 없는 문자와 경합하지 않고 문자열을 사용할 수 있도록 합니다.
목차
문자열 명령 사용
strings 명령에는 복잡한 것이 없으며 기본 사용법은 매우 간단합니다. 문자열이 명령줄에서 검색할 파일의 이름을 제공합니다.
여기에서는 “jibber”라고 하는 실행 파일인 바이너리 파일에 문자열을 사용할 것입니다. 문자열, 공백, “jibber”를 입력한 다음 Enter 키를 누릅니다.
strings jibber

문자열은 파일에서 추출되어 터미널 창에 나열됩니다.

최소 문자열 길이 설정
기본적으로 문자열은 4자 이상의 문자열을 검색합니다. 더 길거나 더 짧은 최소 길이를 설정하려면 -n(최소 길이) 옵션을 사용하십시오.
최소 길이가 짧을수록 더 많은 쓰레기를 볼 가능성이 높아집니다.
일부 이진 값은 인쇄 가능한 문자를 나타내는 값과 동일한 숫자 값을 갖습니다. 이러한 숫자 값 중 두 개가 파일에서 나란히 발생하고 최소 길이를 2로 지정하면 해당 바이트는 마치 문자열인 것처럼 보고됩니다.
최소 길이로 2를 사용하도록 문자열에 요청하려면 다음 명령을 사용하십시오.
strings -n 2 jibber
이제 결과에 두 글자 문자열이 포함됩니다. 공백은 인쇄 가능한 문자로 계산됩니다.

줄을 통해 배관하기
문자열의 출력 길이 때문에 더 적게 파이프할 것입니다. 그런 다음 파일을 스크롤하여 관심 있는 텍스트를 찾을 수 있습니다.
strings jibber | less

이제 목록의 맨 위가 먼저 표시되도록 목록이 간략하게 표시됩니다.

개체 파일과 함께 문자열 사용
일반적으로 프로그램 소스 코드 파일은 개체 파일로 컴파일됩니다. 이들은 라이브러리 파일과 연결되어 바이너리 실행 파일을 생성합니다. 지버 개체 파일이 있으므로 해당 파일 내부를 살펴보겠습니다. “.o” 파일 확장자에 유의하십시오.
jibber.o | less

문자열의 첫 번째 세트는 모두 8자보다 긴 경우 8열에서 래핑됩니다. 래핑된 경우 “H” 문자는 9열에 있습니다. 이러한 문자열을 SQL 문으로 인식할 수 있습니다.

출력을 스크롤하면 이 형식이 파일 전체에서 사용되지 않는다는 것을 알 수 있습니다.

목적 파일과 완성된 실행 파일 사이의 텍스트 문자열의 차이를 보는 것은 흥미롭습니다.
파일의 특정 영역에서 검색
컴파일된 프로그램에는 텍스트를 저장하는 데 사용되는 서로 다른 영역이 있습니다. 기본적으로 문자열은 텍스트를 찾기 위해 전체 파일을 검색합니다. 이것은 -a(all) 옵션을 사용한 것과 같습니다. 문자열이 파일에서 초기화되고 로드된 데이터 섹션에서만 검색되도록 하려면 -d(데이터) 옵션을 사용합니다.
strings -d jibber | less

합당한 이유가 없는 한 기본 설정을 사용하고 전체 파일을 검색할 수도 있습니다.
문자열 오프셋 인쇄
문자열이 각 문자열이 있는 파일의 시작 부분에서 오프셋을 인쇄하도록 할 수 있습니다. 이렇게 하려면 -o(오프셋) 옵션을 사용합니다.
strings -o parse_phrases | less

오프셋은 8진수.
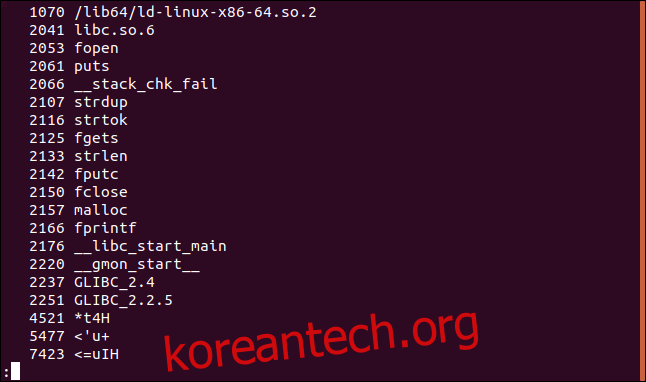
오프셋을 10진수 또는 16진수와 같은 다른 숫자 기반으로 표시하려면 -t(기수) 옵션을 사용합니다. 기수 옵션 다음에 d(소수), x(16진수) 또는 o(8진수). -to를 사용하는 것은 -o를 사용하는 것과 동일합니다.
strings -t d parse_phrases | less

오프셋은 이제 십진수로 인쇄됩니다.
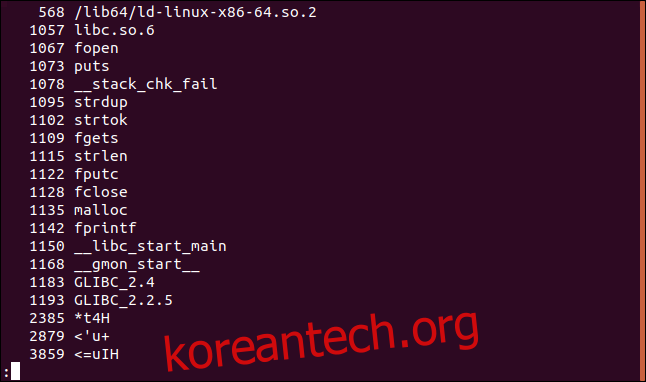
strings -t x parse_phrases | less

오프셋은 이제 16진수로 인쇄됩니다.

공백 포함
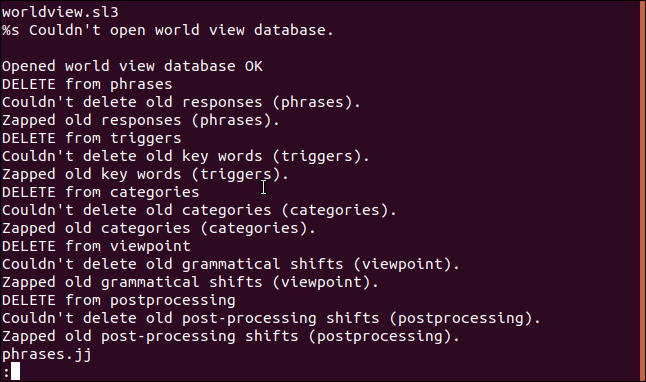
문자열은 탭 및 공백 문자를 찾은 문자열의 일부로 간주합니다. 줄 바꿈 및 캐리지 리턴과 같은 기타 공백 문자는 문자열의 일부인 것처럼 처리되지 않습니다. -w(공백) 옵션은 문자열이 모든 공백 문자를 문자열의 일부인 것처럼 처리하도록 합니다.
strings -w add_data | less

출력에서 빈 줄을 볼 수 있습니다. 이는 (보이지 않는) 캐리지 리턴과 두 번째 줄 끝에 줄 바꿈 문자의 결과입니다.
우리는 파일에 국한되지 않습니다
바이트 스트림이거나 생성할 수 있는 모든 것과 함께 문자열을 사용할 수 있습니다.
이 명령으로 우리는 랜덤 액세스 메모리 (RAM) 우리 컴퓨터.
/dev/mem에 액세스하기 때문에 sudo를 사용해야 합니다. 컴퓨터의 메인 메모리 이미지를 담고 있는 캐릭터 디바이스 파일입니다.
sudo strings /dev/mem | less

목록은 RAM의 전체 내용이 아닙니다. 추출할 수 있는 것은 문자열일 뿐입니다.

한 번에 많은 파일 검색
와일드카드를 사용하여 검색할 파일 그룹을 선택할 수 있습니다. * 문자는 여러 문자를 나타내고 ? 문자는 단일 문자를 나타냅니다. 명령줄에 많은 파일 이름을 제공하도록 선택할 수도 있습니다.
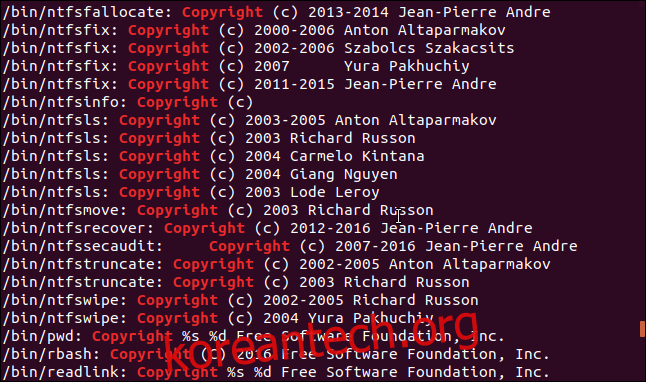
와일드카드를 사용하고 /bin 디렉토리에 있는 모든 실행 파일을 검색할 것입니다. 목록에는 많은 파일의 결과가 포함되므로 -f(파일 이름) 옵션을 사용합니다. 이렇게 하면 각 줄의 시작 부분에 파일 이름이 인쇄됩니다. 그런 다음 각 문자열이 어떤 파일에서 발견되었는지 확인할 수 있습니다.
우리는 결과를 파이핑하고 있습니다. 그렙, “저작권”이라는 단어가 포함된 문자열을 찾습니다.
strings -f /bin/* | grep Copyright

/bin 디렉토리의 각 파일에 대한 저작권 설명의 깔끔한 목록을 얻습니다. 각 줄의 시작 부분에 파일 이름이 있습니다.
끈이 풀리다
문자열에는 미스터리가 없습니다. 이것은 일반적인 Linux 명령입니다. 그것은 매우 구체적인 일을 하고 아주 잘 합니다.
이것은 Linux의 톱니바퀴 중 하나이며 다른 명령과 함께 작동할 때 실제로 살아납니다. 바이너리 파일과 grep과 같은 다른 도구 사이에 위치하는 방법을 보면 이 약간 모호한 명령의 기능에 감사하기 시작합니다.