Apache Kafka 다운로드 및 설치 방법 [Windows and Linux]
아파치 카프카(Apache Kafka)는 여러 분산 시스템 내 애플리케이션들이 메시지를 통해 상호 작용하고 데이터를 공유할 수 있도록 지원하는 메시지 스트리밍 플랫폼입니다.
이는 발행/구독 시스템으로 작동하여, 데이터를 생성하는 애플리케이션(생산자)이 메시지를 발행하고, 데이터를 필요로 하는 시스템(소비자)이 해당 메시지를 구독합니다.
아파치 카프카를 활용하면 데이터 생성 및 소비 시스템 간에 느슨하게 연결된 아키텍처를 구성할 수 있습니다. 이는 시스템 설계 및 유지 관리를 더욱 간소화해줍니다. 카프카는 클러스터 내 여러 구성 요소의 메타데이터 관리와 동기화를 위해 주키퍼(Zookeeper)를 사용합니다.
아파치 카프카의 주요 특징
아파치 카프카는 다음과 같은 다양한 이유로 널리 사용됩니다:
- 클러스터 및 파티션 구성을 통한 높은 확장성
- 초당 2백만 건의 쓰기를 처리할 수 있는 뛰어난 성능
- 메시지 전송 순서 보장
- 복제 메커니즘을 통한 높은 신뢰성
- 시스템 중단 없이 가능한 업그레이드
이제 카프카가 일반적으로 사용되는 몇 가지 사례를 살펴보겠습니다.
아파치 카프카의 일반적인 사용 사례
카프카는 빅데이터 처리, 클릭 이벤트와 같은 이벤트 로그 기록 및 집계, 여러 시스템으로부터의 로그를 한 곳으로 통합하는 데 주로 사용됩니다.
또한 시스템 내 다양한 애플리케이션 간의 통신을 지원하고, IoT 기기에서 생성되는 데이터를 실시간으로 처리하는 데에도 유용합니다.
이제 윈도우(Windows)와 리눅스(Linux) 환경에서 카프카를 설치하는 세부 단계를 알아보겠습니다.
윈도우에 카프카 설치하기
윈도우에 아파치 카프카를 설치하기 전에, 먼저 컴퓨터에 자바(Java)가 설치되어 있는지 확인해야 합니다. 관리자 권한으로 명령 프롬프트를 실행하고 다음 명령어를 입력합니다:
java --version
자바가 설치되어 있다면, 현재 설치된 JDK 버전 정보가 출력되어야 합니다.
만약 명령어를 인식할 수 없다는 오류 메시지가 표시된다면, 자바가 설치되어 있지 않은 것이므로 먼저 자바를 설치해야 합니다. Adoptium.net 웹사이트에서 자바를 다운로드하여 설치할 수 있습니다.
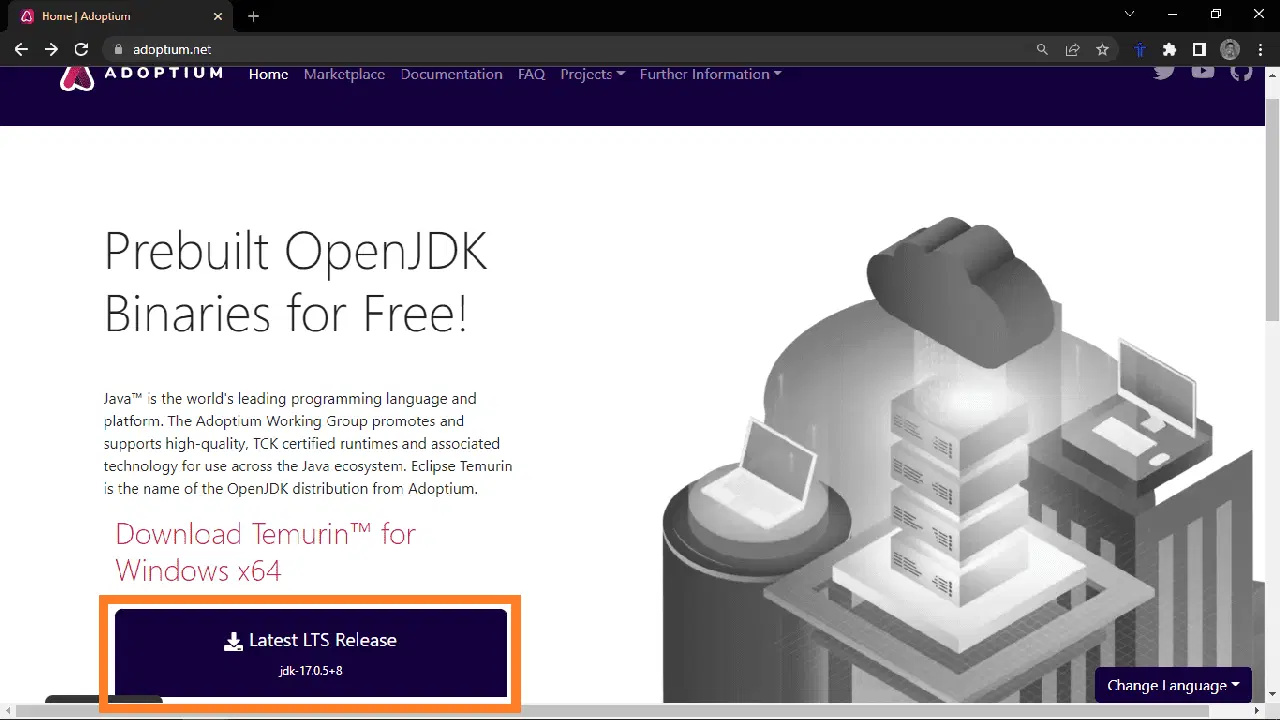
자바 설치 파일이 다운로드되면 실행하여 설치를 진행합니다. 설치 프로그램에서 기본 옵션을 선택하고 '다음'을 눌러 설치를 완료합니다.
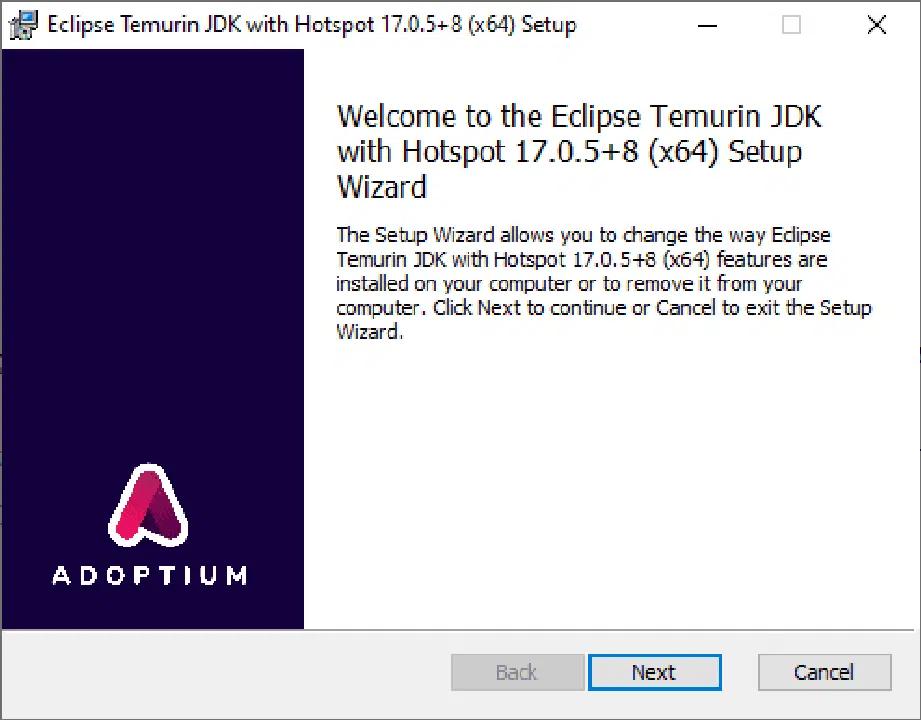
설치가 완료되면 명령 프롬프트를 닫고 다시 관리자 권한으로 실행한 후 다음 명령어를 입력하여 자바 설치를 확인합니다.
java --version
이번에는 방금 설치한 JDK 버전 정보가 출력되어야 합니다. 자바 설치가 완료되었으면 이제 카프카 설치를 시작할 수 있습니다.
카프카를 설치하려면 먼저 공식 카프카 웹사이트에 접속합니다.

웹사이트에서 다운로드 페이지로 이동하여, 최신 버전의 바이너리 파일을 다운로드합니다.
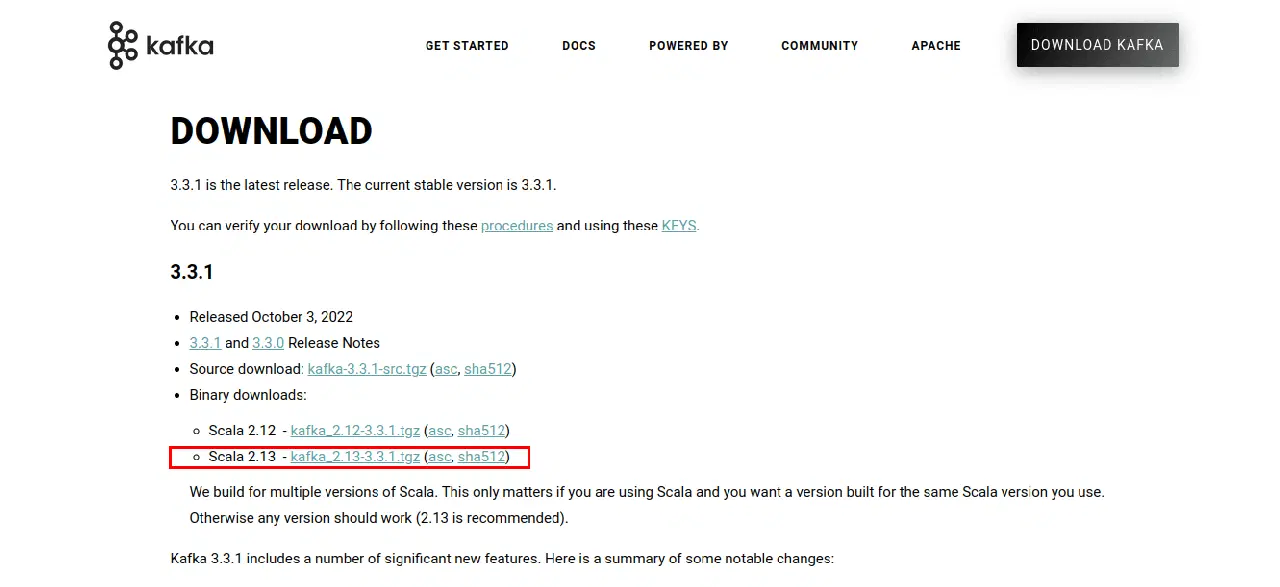
다운로드한 파일은 .tgz 형식으로 압축되어 있으며, 카프카 실행 스크립트와 바이너리 파일들을 포함하고 있습니다. 압축을 풀기 위해 WinZip과 같은 도구를 사용합니다.
압축을 푼 파일들을 C:kafka 경로에 복사합니다.
이제 관리자 권한으로 명령 프롬프트를 실행하고, 카프카 디렉토리로 이동하여 주키퍼를 시작합니다. zookeeper.properties 파일을 구성 파일로 사용하여 zookeeper-server-start.bat 파일을 실행합니다.
cd C:kafka binwindowszookeeper-server-start.bat configzookeeper.properties
주키퍼를 실행하는 동안, 카프카가 시스템 PATH에 사용하는 wmic 실행 파일을 추가해야 합니다.
set PATH=C:WindowsSystem32wbem;%PATH%;
이후, 새로운 명령 프롬프트 창을 관리자 권한으로 실행하고, C:kafka 폴더로 이동하여 아파치 카프카 서버를 시작합니다.
cd C:kafka
다음 명령어를 입력하여 카프카를 시작합니다:
binwindowskafka-server-start.bat configserver.properties
카프카가 성공적으로 실행되었을 것입니다. server.properties 파일에서 로그 기록 위치와 같은 서버 설정을 변경할 수 있습니다.
리눅스에 카프카 설치하기
먼저 다음 명령어를 사용하여 시스템 패키지를 최신 상태로 업데이트합니다:
sudo apt update && sudo apt upgrade
자바가 설치되어 있는지 확인하기 위해 다음 명령어를 실행합니다:
java --version
자바가 설치되어 있다면, 버전 정보가 표시됩니다. 만약 자바가 설치되어 있지 않다면 다음 명령어를 사용하여 설치할 수 있습니다.
sudo apt install default-jdk
이제 카프카 웹사이트에서 바이너리 파일을 다운로드하여 아파치 카프카를 설치할 수 있습니다.
터미널을 열고 다운로드한 파일이 저장된 폴더로 이동합니다. 예시에서는 다운로드 폴더로 이동합니다.
cd Downloads
다운로드 폴더로 이동한 후, tar 명령어를 사용하여 다운로드한 파일의 압축을 해제합니다.
tar -xvzf kafka_2.13-3.3.1.tgz
압축 해제된 폴더로 이동합니다.
cd kafka_2.13-3.3.1
폴더 내용을 확인합니다.
이제 해당 폴더의 bin 디렉토리에 있는 zookeeper-server-start.sh 스크립트를 실행하여 주키퍼 서버를 시작합니다.
스크립트는 주키퍼 구성 파일이 필요합니다. 기본 구성 파일은 config 하위 디렉토리에 있는 zookeeper.properties 파일입니다.
따라서 다음 명령어를 사용하여 서버를 시작합니다:
bin/zookeeper-server-start.sh config/zookeeper.properties
주키퍼를 실행한 후에는, 아파치 카프카 서버를 시작할 수 있습니다. bin 디렉토리에는 kafka-server-start.sh 스크립트도 있습니다. 이 스크립트 역시 구성 파일이 필요하며, 기본적으로 server.properties 파일이 사용됩니다.
bin/kafka-server-start.sh config/server.properties
이렇게 하면 아파치 카프카가 실행됩니다. bin 디렉토리 내에는 토픽 생성, 생산자 관리, 소비자 관리 등 다양한 작업을 수행하는 스크립트들이 있습니다. server.properties 파일에서 서버 설정을 사용자 정의할 수도 있습니다.
마지막으로
이 가이드에서는 자바와 아파치 카프카를 설치하는 방법을 살펴보았습니다. 카프카 클러스터를 직접 설치하고 관리할 수도 있지만, Amazon Web Services 및 Confluent와 같은 관리형 서비스를 이용할 수도 있습니다.
다음 단계로는 카프카와 스파크(Spark)를 활용하여 데이터 처리를 배우는 것을 추천합니다.