2부 – 벡터화 기술 유형
본 글에서는 자연어 처리(NLP) 기술 중 하나인 벡터화에 대해 알아보고, 다양한 벡터화 기법을 자세히 살펴보며 그 중요성을 이해하는 시간을 갖겠습니다.
이전에 NLP의 기본 개념과 텍스트 전처리 과정을 다룬 적이 있습니다. 토큰화, 정규화, 표준화와 같은 기술들을 통해 텍스트를 정리하는 방법을 살펴보았습니다.

벡터화에 대해 자세히 알아보기 전에, 토큰화가 무엇인지, 그리고 벡터화와 어떻게 다른지를 간단히 짚고 넘어가겠습니다.
토큰화란 무엇인가?
토큰화는 문장을 더 작은 단위인 토큰으로 분해하는 과정입니다. 토큰은 컴퓨터가 텍스트를 더 쉽게 이해하고 처리할 수 있도록 도와줍니다.
예를 들어, '이 글은 유익합니다'라는 문장은 다음과 같이 토큰화될 수 있습니다.
토큰: ['이', '글은', '유익합니다']
벡터화란 무엇인가?
우리가 알고 있듯이, 기계 학습 모델과 알고리즘은 숫자 형태의 데이터를 이해합니다. 따라서 벡터화는 텍스트나 범주형 데이터를 컴퓨터가 이해할 수 있는 숫자 벡터로 변환하는 과정입니다. 이러한 변환을 통해 모델을 더욱 정확하게 학습시킬 수 있습니다.
벡터화가 필요한 이유는 무엇인가?
❇️ 자연어 처리(NPL)에서 토큰화와 벡터화는 서로 다른 역할을 합니다. 토큰화는 문장을 작은 토큰으로 나누는 반면, 벡터화는 이러한 토큰을 컴퓨터/머신러닝 모델이 이해할 수 있는 숫자 형식으로 변환합니다.
❇️ 벡터화는 단순히 데이터를 숫자 형태로 바꾸는 것뿐 아니라 텍스트의 의미론적 의미를 포착하는 데에도 중요합니다.
❇️ 데이터의 차원을 줄여 계산 효율성을 높일 수 있습니다. 이는 대규모 데이터 세트를 처리할 때 특히 유용합니다.
❇️ 신경망과 같은 많은 기계 학습 알고리즘은 수치 입력을 필요로 하므로, 벡터화는 필수적인 과정입니다.
본 글을 통해 다양한 벡터화 기술들을 이해하게 될 것입니다.
단어 가방 (Bag of Words)
여러 문서나 문장을 분석하고자 할 때, 단어 가방(Bag of Words, BoW) 기법은 문서를 단순히 단어들이 담긴 가방처럼 취급하여 분석 과정을 단순화합니다.
BoW 접근 방식은 텍스트 분류, 감정 분석, 문서 검색 등 다양한 분야에서 유용하게 활용될 수 있습니다.
만약 우리가 방대한 양의 텍스트 데이터를 다루고 있다고 가정해 봅시다. BoW는 텍스트 데이터에서 고유한 단어 목록을 생성하여 텍스트를 표현하는 데 도움을 줍니다. 단어 목록(어휘)이 생성되면 각 단어가 해당 텍스트에 나타나는 빈도를 기반으로 각 단어를 벡터 형태로 인코딩합니다.
이러한 벡터는 해당 문서에서 각 단어가 나타나는 빈도수를 나타내는 0 또는 양의 정수로 구성됩니다.
BoW 기법은 다음과 같은 세 단계로 이루어집니다.
1단계: 토큰화
문서를 토큰으로 분해합니다.
예시 - (문장: “저는 피자를 좋아하고 햄버거를 좋아합니다”)
2단계: 고유 단어 추출/어휘 생성
문장에 나타나는 모든 고유한 단어의 목록을 만듭니다.
[“저는”, “좋아하고”, “피자를”, “햄버거를”]
3단계: 단어 빈도 계산/벡터 생성
이 단계에서는 어휘 내 각 단어가 반복되는 횟수를 계산하여 희소 행렬에 저장합니다. 여기서 행렬의 각 행은 문장 벡터를 나타내며, 열의 길이는 어휘의 크기와 동일합니다.
CountVectorizer 가져오기
BoW 모델을 학습시키기 위해 scikit-learn 라이브러리의 CountVectorizer를 사용할 것입니다.
from sklearn.feature_extraction.text import CountVectorizer
벡터라이저 생성
이제 CountVectorizer를 사용하여 모델을 생성하고, 샘플 텍스트 문서를 이용하여 모델을 학습시키겠습니다.
# 샘플 텍스트 문서
documents = [
"이것은 첫 번째 문서입니다.",
"이 문서는 두 번째 문서입니다.",
"그리고 이것은 세 번째 문서입니다.",
"이것은 첫 번째 문서입니까?",
]
# CountVectorizer 생성
cv = CountVectorizer()
# 학습 및 변환 X = cv.fit_transform(documents)
밀집 배열로 변환
이제 표현을 밀집된 배열 형태로 변환합니다. 또한, 각 특성(단어)의 이름도 얻을 수 있습니다.
# 특성 이름/단어 얻기 feature_names = cv.get_feature_names_out() # 밀집 배열로 변환 X_dense = X.toarray()
문서-단어 행렬과 특성 단어를 출력해 보겠습니다.
# DTM 및 특성 이름 출력
print("문서-단어 행렬 (DTM):")
print(X_dense)
print("\n특성 이름:")
print(feature_names)
문서-단어 행렬(DTM):
 행렬
행렬
특성 이름:
 특성 단어
특성 단어
보시다시피, 벡터는 문서 내 단어 빈도를 나타내는 0 또는 양의 정수로 구성됩니다.
우리는 4개의 샘플 텍스트 문서를 가지고 있으며, 이 문서들에서 9개의 고유한 단어를 식별했습니다. 이 고유한 단어들에 '특성 이름'을 부여하여 어휘에 저장했습니다.
BoW 모델은 첫 번째 고유 단어가 첫 번째 문서에 존재하는지 확인합니다. 존재하면 값 1을 할당하고, 그렇지 않으면 0을 할당합니다.
단어가 여러 번 (예: 2회) 나타나면 그 빈도수에 따라 값이 할당됩니다.
예를 들어 두 번째 문서에서 '문서'라는 단어가 두 번 반복되므로 행렬에서 해당 값은 2가 됩니다.
어휘 키의 특성으로 단일 단어를 원한다면 – 유니그램 표현입니다.
n-그램 = 유니그램, 바이그램 ...
단어 가방을 구현하는 scikit-learn과 같은 라이브러리는 Keras, Gensim 등 다양하게 있습니다. BoW는 단순하면서도 다양한 상황에 유용하게 사용될 수 있습니다.
그러나 BoW는 빠르지만 몇 가지 한계점을 가지고 있습니다.
- 중요도와 관계없이 모든 단어에 동일한 가중치를 부여합니다. 실제로는 어떤 단어는 다른 단어보다 더 중요할 수 있습니다.
- BoW는 단순히 단어의 빈도, 즉 문서에 단어가 나타나는 횟수만 계산합니다. 이는 '는', '그리고', '이다' 등과 같은 흔한 단어에 대한 편향으로 이어질 수 있으며, 이 단어들은 많은 의미를 전달하지 못할 수 있습니다.
- 문서가 길수록 단어 수도 늘어나고 더 큰 벡터가 생성됩니다. 이로 인해 비교가 어려워질 수 있으며, 복잡한 NLP 프로젝트에 적합하지 않은 희소 행렬을 생성할 수 있습니다.
이러한 문제를 해결하기 위해 더 나은 접근 방식이 필요하며, 그 중 하나가 TF-IDF입니다. 이제 TF-IDF에 대해 자세히 알아보겠습니다.
TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency, 단어 빈도-역 문서 빈도)는 문서에서 단어의 중요도를 결정하는 데 사용되는 수치적 표현 방식입니다.
BoW 대신 TF-IDF가 필요한 이유는 무엇인가?
단어 가방(BoW)은 모든 단어를 동등하게 취급하며, 문장에서 고유한 단어의 빈도에만 관심을 갖습니다. 반면, TF-IDF는 빈도와 고유성을 모두 고려하여 문서 내 단어의 중요도를 평가합니다.
너무 자주 반복되는 단어가 덜 빈번하고 더 중요한 단어를 압도하지 않도록 해줍니다.
TF: 단어 빈도(Term Frequency)는 한 문서 내에서 특정 단어가 얼마나 중요한지를 측정합니다.
IDF: 역 문서 빈도(Inverse Document Frequency)는 전체 문서 모음에서 특정 단어가 얼마나 중요한지를 측정합니다.
TF = 문서 내 단어 빈도 / 해당 문서의 총 단어 수
DF = 특정 단어가 포함된 문서 수 / 총 문서 수
IDF = log(총 문서 수 / 특정 단어가 포함된 문서 수)
IDF는 DF의 역수입니다. 이는 특정 단어가 전체 문서에서 더 흔하게 나타날수록 현재 문서에서의 중요도가 낮아지기 때문입니다.
최종 TF-IDF 점수: TF-IDF = TF * IDF
TF-IDF는 단일 문서 내에서 자주 사용되는 단어와 모든 문서에서 고유한 단어를 찾는 방법입니다. 이 방법은 문서의 주요 주제를 파악하는 데 유용하게 활용될 수 있습니다.
예를 들어,
Doc1 = “저는 머신러닝을 좋아합니다”
Doc2 = "저는 koreantech.org를 좋아합니다"
이 문서들에 대한 TF-IDF 행렬을 찾아보겠습니다.
먼저, 고유한 단어들로 구성된 어휘를 만들어 보겠습니다.
어휘 = ["저는", "좋아합니다", "머신러닝을", "koreantech.org를"]
총 4개의 고유 단어가 있습니다. 각 단어에 대한 TF와 IDF를 계산해 보겠습니다.
TF = 문서 내 단어 빈도 / 해당 문서의 총 단어 수
TF:
- Doc1에서 “저는”의 TF: 1/4 = 0.25, Doc2에서: 1/4 = 0.25
- “좋아합니다”의 TF: Doc1에서 1/4 = 0.25, Doc2에서 1/4 = 0.25
- “머신러닝을”의 TF: Doc1에서 1/4 = 0.25, Doc2에서: 0/4 = 0
- “koreantech.org를”의 TF: Doc1에서: 0/4 = 0, Doc2에서: 1/4 = 0.25
이제 IDF를 계산해 보겠습니다.
IDF = log(총 문서 수 / 특정 단어가 포함된 문서 수)
IDF:
- "저는"의 IDF: log(2/2) = 0
- "좋아합니다"의 IDF: log(2/2) = 0
- "머신러닝을"의 IDF: log(2/1) = log(2) ≈ 0.69
- "koreantech.org를"의 IDF: log(2/1) = log(2) ≈ 0.69
이제 최종 TF-IDF 점수를 계산해 보겠습니다.
- "저는"의 경우: Doc1에서 TF-IDF: 0.25 * 0 = 0, Doc2에서 TF-IDF: 0.25 * 0 = 0
- "좋아합니다"의 경우: Doc1에서 TF-IDF: 0.25 * 0 = 0, Doc2에서 TF-IDF: 0.25 * 0 = 0
- "머신러닝을"의 경우: Doc1에서 TF-IDF: 0.25 * 0.69 ≈ 0.17, Doc2에서 TF-IDF: 0 * 0.69 = 0
- "koreantech.org를"의 경우: Doc1에서 TF-IDF: 0 * 0.69 = 0, Doc2에서 TF-IDF: 0.25 * 0.69 ≈ 0.17
따라서 TF-IDF 행렬은 다음과 같습니다.
저는 좋아합니다 머신러닝을 koreantech.org를 Doc1 0.0 0.0 0.17 0.0 Doc2 0.0 0.0 0.0 0.17
TF-IDF 행렬 값은 각 문서 내에서 각 단어가 얼마나 중요한지를 나타냅니다. 높은 값은 해당 단어가 특정 문서에서 중요함을 의미하고, 낮은 값은 해당 단어가 해당 문맥에서 덜 중요하거나 일반적임을 나타냅니다.
TF-IDF는 주로 텍스트 분류, 챗봇 정보 검색, 텍스트 요약 등의 분야에서 활용됩니다.
TfidfVectorizer 가져오기
scikit-learn에서 TfidfVectorizer를 가져옵니다.
from sklearn.feature_extraction.text import TfidfVectorizer
벡터라이저 생성
TfidfVectorizer를 사용하여 TF-IDF 모델을 생성합니다.
# 샘플 텍스트 문서
text = [
"이것은 첫 번째 문서입니다.",
"이 문서는 두 번째 문서입니다.",
"그리고 이것은 세 번째 문서입니다.",
"이것은 첫 번째 문서입니까?",
]
# TfidfVectorizer 생성
cv = TfidfVectorizer()
TF-IDF 행렬 생성
텍스트를 제공하여 모델을 학습시키고, 생성된 행렬을 밀집 배열로 변환합니다.
# 학습 및 변환을 통해 TF-IDF 행렬 생성 X = cv.fit_transform(text)
# 특성 이름/단어 얻기 feature_names = cv.get_feature_names_out() # TF-IDF 행렬을 쉽게 다루기 위해 밀집 배열로 변환 (선택 사항) X_dense = X.toarray()
TF-IDF 행렬 및 특성 단어 출력
# TF-IDF 행렬 및 특성 단어 출력
print("TF-IDF 행렬:")
print(X_dense)
print("\n특성 이름:")
print(feature_names)
TF-IDF 행렬:
 특성 단어
특성 단어
보시다시피, 이러한 소수점 값은 특정 문서에서 단어의 중요도를 나타냅니다.
또한, n-그램을 사용하여 단어를 2개, 3개, 4개 등의 그룹으로 결합할 수도 있습니다.
min_df, max_feature, subliner_tf 등 다양한 매개변수를 사용할 수도 있습니다.
지금까지는 기본적인 빈도 기반 기술을 살펴보았습니다.
그러나 TF-IDF는 텍스트의 의미론적 의미와 문맥적 이해를 제공하지 못합니다.
이제 단어 임베딩이라는 새로운 개념을 통해 의미론적 의미와 문맥 이해를 향상시키는 고급 기술을 알아보겠습니다.
Word2Vec
Word2vec은 인기 있는 단어 임베딩 기술입니다. 단어를 다차원 공간의 연속 벡터로 표현하여 단어 간의 의미 및 구문적 유사성을 파악하는 데 유용합니다. Word2vec은 2013년 Google의 Tomas Mikolov와 그의 연구팀에 의해 개발되었습니다.
Word2vec은 단어의 의미를 포착하는 방식으로 단어를 표현하는 것을 목표로 합니다. Word2vec에 의해 생성된 단어 벡터는 연속적인 벡터 공간에 위치합니다.
예를 들어, '고양이'와 '강아지' 벡터는 '고양이'와 '소녀' 벡터보다 더 가깝게 위치합니다.
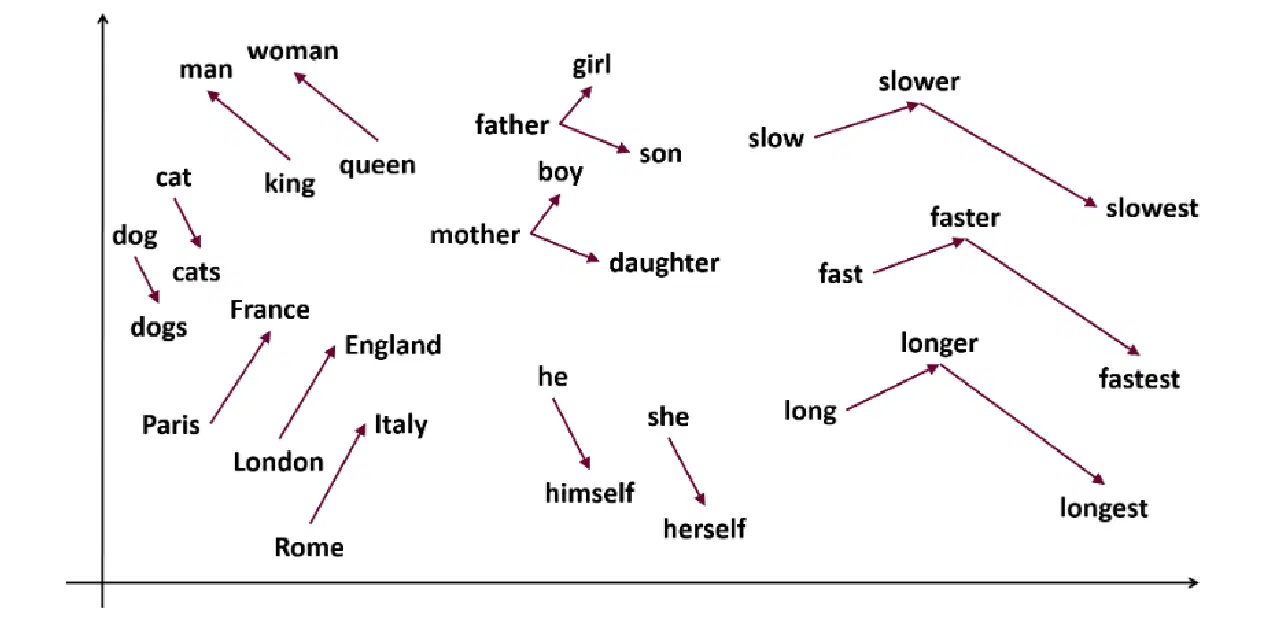 출처: usna.edu
출처: usna.edu
Word2vec에서는 단어 임베딩을 생성하기 위해 두 가지 모델 구조를 사용할 수 있습니다.
CBOW: Continuous Bag of Words(연속 단어 가방)는 주변 단어들의 의미를 평균하여 타겟 단어를 예측하려고 시도합니다. 타겟 단어 주변의 고정된 크기의 단어 창을 설정하고, 이 창에 포함된 단어들을 수치 형식(임베딩)으로 변환한 후, 모든 임베딩의 평균값을 사용하여 신경망을 통해 타겟 단어를 예측합니다.
예시 - 예측 대상: '여우'
문장 단어: '그', '빠른', '갈색', '점프', '넘어', '그'
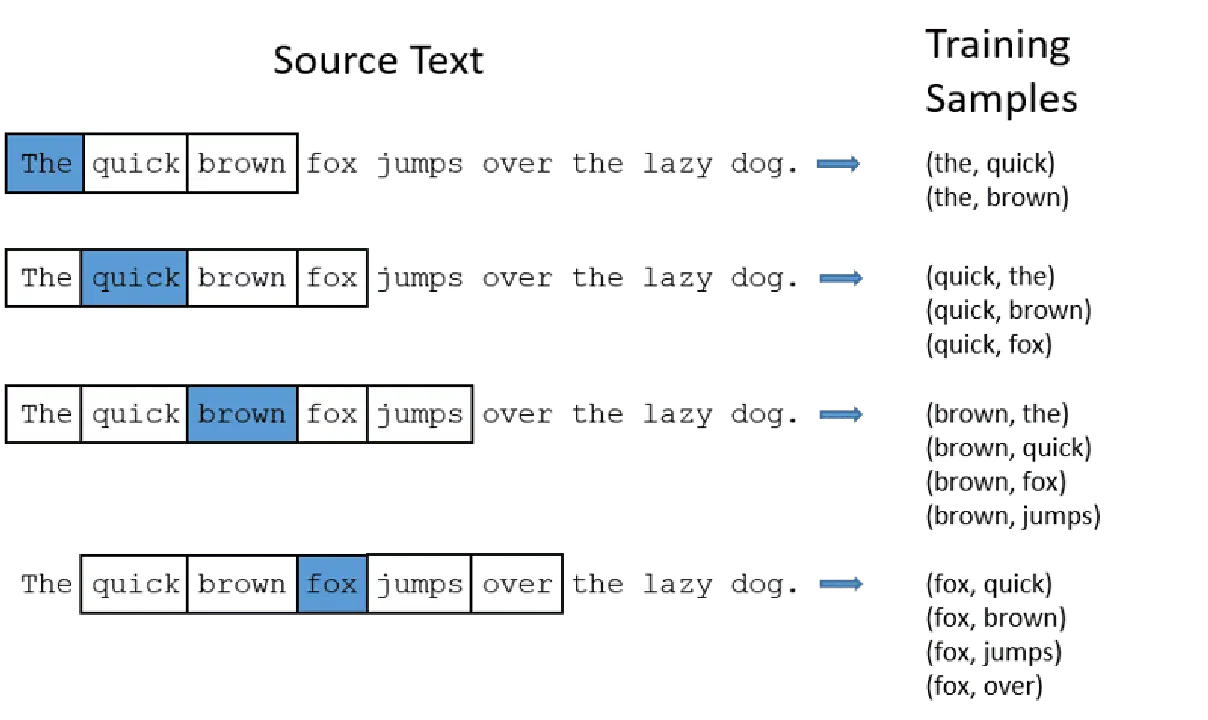 Word2Vec
Word2Vec
- CBOW는 2(왼쪽 2개, 오른쪽 2개)와 같은 고정 크기의 단어 창을 사용합니다.
- 단어들을 임베딩으로 변환합니다.
- CBOW는 단어 임베딩의 평균값을 계산합니다.
- CBOW는 주변 단어 임베딩의 평균값을 구합니다.
- 평균 벡터를 사용하여 신경망을 통해 타겟 단어를 예측합니다.
이제 스킵그램(Skip-gram)이 CBOW와 어떻게 다른지 알아보겠습니다.
스킵그램: 스킵그램은 단어 임베딩 모델이지만 작동 방식이 다릅니다. 스킵그램은 타겟 단어를 예측하는 대신, 타겟 단어가 주어졌을 때 주변 단어를 예측합니다.
스킵그램은 단어 간의 의미 관계를 파악하는 데 더 효과적입니다.
예시: '왕 - 남자 + 여자 = 여왕'
Word2Vec을 사용하려면 직접 모델을 훈련시키거나 미리 훈련된 모델을 사용할 수 있습니다. 여기서는 미리 훈련된 모델을 사용해 보겠습니다.
Gensim 가져오기
pip install 명령어를 사용하여 gensim을 설치할 수 있습니다.
pip install gensim
word_tokenize를 사용하여 문장을 토큰화합니다.
먼저 문장을 소문자로 변환한 후, word_tokenize를 사용하여 문장을 토큰화합니다.
# 필요한 라이브러리 가져오기
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# 샘플 문장
sentences = [
"나는 토르를 좋아합니다",
"헐크는 어벤져스의 중요한 멤버입니다",
"아이언맨은 스파이더맨을 돕습니다",
"스파이더맨은 어벤져스의 인기있는 멤버 중 하나입니다",
]
# 문장 토큰화
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
모델을 학습시켜 보겠습니다.
토큰화된 문장을 제공하여 모델을 학습시키겠습니다. 이 모델은 창 크기를 5로 설정했습니다. 필요에 따라 조정할 수 있습니다.
# Word2Vec 모델 학습
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# 유사한 단어 찾기
similar_words = model.wv.most_similar("어벤져스")
# 유사한 단어 출력
print("‘어벤져스’와 유사한 단어:")
for word, score in similar_words:
print(f"{word}: {score}")
'어벤져스'와 유사한 단어:
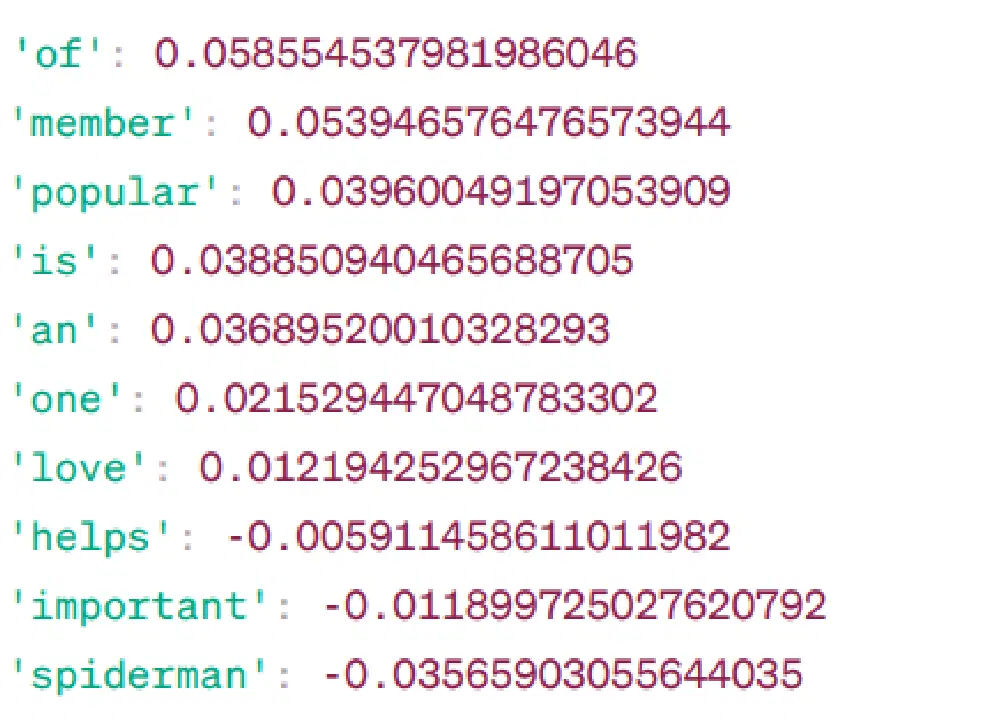 Word2Vec 유사도
Word2Vec 유사도
Word2Vec 모델을 기반으로 '어벤져스'와 유사한 단어와 그 유사도 점수입니다.
모델은 ‘어벤져스’ 단어 벡터와 어휘에 있는 다른 단어들 사이의 유사도 점수(주로 코사인 유사도)를 계산합니다. 유사도 점수는 벡터 공간에서 두 단어가 얼마나 밀접하게 관련되어 있는지를 나타냅니다.
예시 -
여기서 '돕습니다'라는 단어는 '어벤져스'라는 단어와 코사인 유사도 점수가 -0.005911458611011982입니다. 음수 값은 두 단어가 서로 다를 수 있음을 나타냅니다.
코사인 유사도 값의 범위는 -1부터 1까지입니다. 여기서:
- 1은 두 벡터가 동일하고 긍정적인 유사도를 가짐을 나타냅니다.
- 1에 가까운 값은 높은 긍정적 유사도를 나타냅니다.
- 0에 가까운 값은 벡터가 밀접하게 관련되어 있지 않음을 나타냅니다.
- -1에 가까운 값은 비유사성이 높다는 것을 나타냅니다.
- -1은 두 벡터가 완전히 반대이고 완전한 음의 유사도를 가지고 있음을 나타냅니다.
더 자세히 알고 싶다면 다음 링크를 방문하여 Word2Vec 모델이 어떻게 작동하는지 시각적으로 표현된 도구를 사용해 보십시오. CBOW와 스킵그램이 실제로 어떻게 작동하는지 볼 수 있는 좋은 도구입니다.
Word2Vec과 유사하게 GloVe도 있습니다. GloVe는 Word2Vec에 비해 더 적은 메모리를 필요로 하는 임베딩을 생성할 수 있습니다. 이제 GloVe에 대해 좀 더 알아보겠습니다.
GloVe
GloVe(Global Vectors for Word Representation)는 Word2Vec과 유사한 기술로, 단어를 연속적인 공간의 벡터로 표현하는 데 사용됩니다. GloVe의 기본적인 개념은 Word2Vec과 동일합니다. 즉, 문맥 속에서 단어의 의미를 파악하여 단어 임베딩을 생성하는 것입니다. 다만, Word2Vec의 장점을 유지하면서 전역 통계를 활용한다는 차이점이 있습니다.
GloVe가 필요한 이유는 무엇인가?
Word2Vec은 윈도우 기반 방식으로 주변 단어를 이용하여 단어를 이해하는 접근 방식을 사용합니다. 이는 특정 단어의 의미가 문장 내 주변 단어의 영향을 받는다는 것을 의미하지만, 통계적인 측면에서는 비효율적입니다.
GloVe는 단어 임베딩을 생성할 때 지역 정보뿐만 아니라 전역 통계 정보도 함께 고려합니다.
GloVe는 언제 사용해야 할까?
더 넓은 의미론적 관계와 전역적인 단어 연관성을 포착하는 단어 임베딩이 필요할 때 GloVe를 사용하는 것이 좋습니다.
GloVe는 명명된 엔터티 인식 작업, 단어 유추, 단어 유사성 측면에서 다른 모델보다 더 나은 성능을 보입니다.
먼저 Gensim을 설치해야 합니다:
pip install gensim
1단계: 필요한 라이브러리를 가져오겠습니다.
# 필요한 라이브러리 가져오기 import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
2단계: GloVe 모델 가져오기
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
3단계: '귀엽다'라는 단어에 대한 벡터 단어 표현 검색
glove_model["귀엽다"]
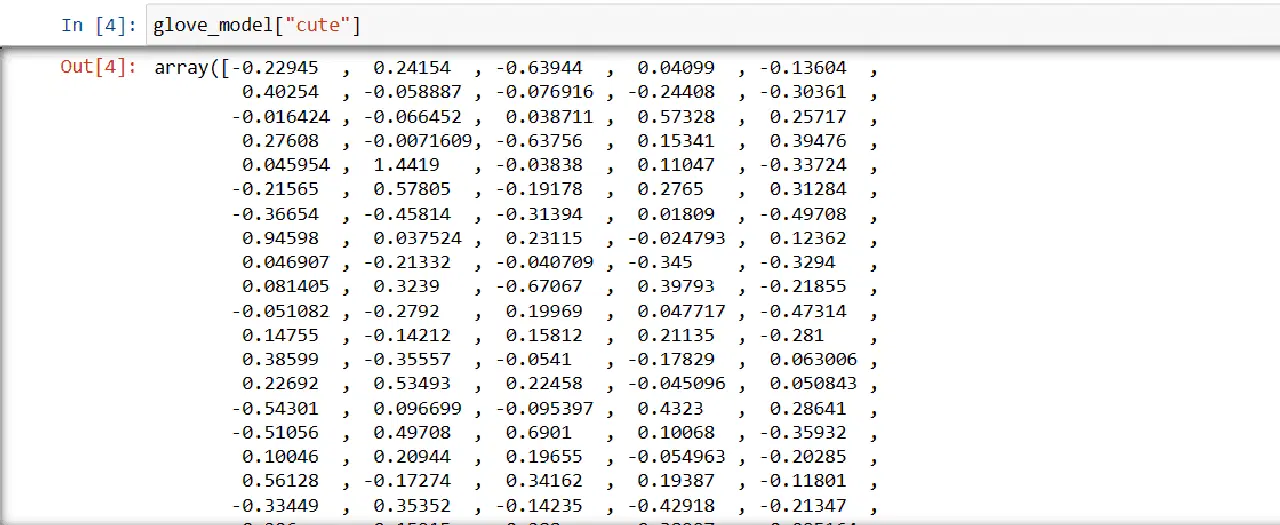 '귀엽다'라는 단어에 대한 벡터
'귀엽다'라는 단어에 대한 벡터
이러한 값은 단어의 의미와 다른 단어와의 관계를 포착합니다. 양수 값은 특정 개념과의 양의 연관성을 나타내고, 음수 값은 다른 개념과의 음의 연관성을 나타냅니다.
GloVe 모델에서 단어 벡터의 각 차원은 단어의 의미나 문맥의 특정 측면을 나타냅니다.
이러한 차원의 음수 및 양수 값은 '귀엽다'가 모델 어휘의 다른 단어들과 의미상 얼마나 관련되는지에 영향을 미칩니다.
모델에 따라 값이 다를 수 있습니다. 이번에는 '소년'이라는 단어와 유사한 단어를 찾아보겠습니다.
모델이 생각하는 '소년'과 가장 유사한 단어 상위 10개를 출력합니다.
# 유사 단어 찾기
glove_model.most_similar("소년")
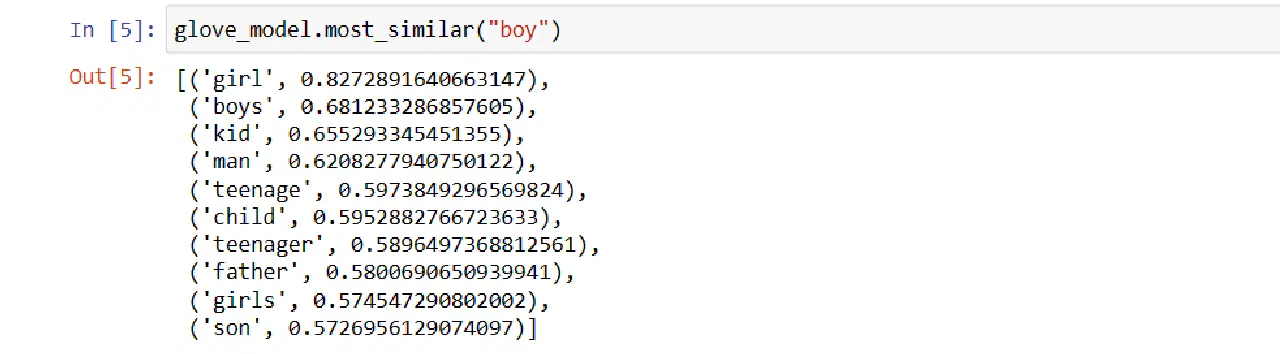 '소년'과 비슷한 단어 TOP 10
'소년'과 비슷한 단어 TOP 10
보시다시피 '소년'과 가장 유사한 단어는 '소녀'입니다.
이제 모델이 주어진 단어에서 의미론적 의미를 얼마나 정확하게 추출할 수 있는지 확인해 보겠습니다.
glove_model.most_similar(positive=['소년', '여왕'], negative=['소녀'], topn=1)
 '여왕'과 가장 관련 있는 단어
'여왕'과 가장 관련 있는 단어
우리 모델은 단어 간의 관계를 완벽하게 파악할 수 있음을 보여줍니다.
어휘 목록 정의:
이제 단어 사이의 의미적 관계를 시각화하여 이해도를 높여보겠습니다. 시각화할 단어 목록을 정의합니다.
# 시각화할 단어 목록 정의 vocab = ["소년", "소녀", "남자", "여자", "왕", "여왕", "바나나", "사과", "망고", "소", "코코넛", "오렌지", "고양이", "개"]
임베딩 행렬 생성:
임베딩 행렬을 생성하는 코드를 작성해 보겠습니다.
# 임베딩 행렬 생성 코드
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
t-SNE 시각화를 위한 함수 정의:
시각화 플롯 기능을 정의합니다.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
플롯을 확인해 보겠습니다.
# 임베딩 행렬과 단어 목록으로 tsne_plot 함수 호출 tsne_plot(embedding_matrix, vocab)
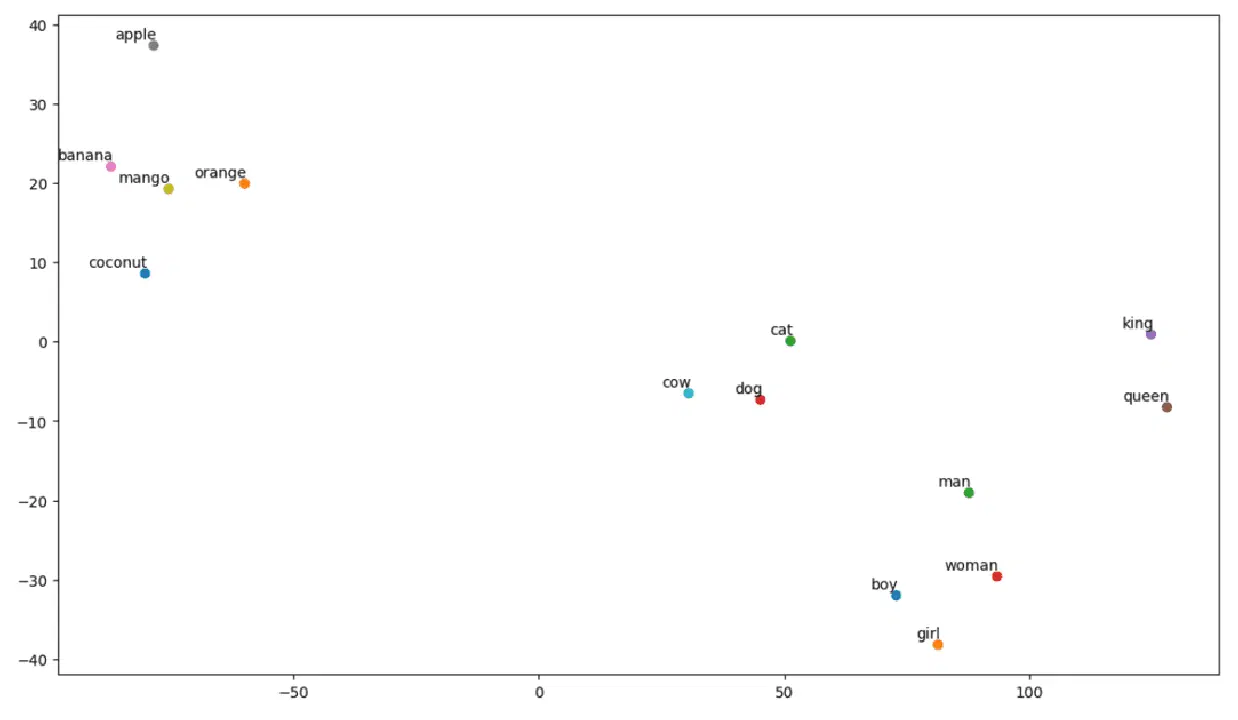 t-SNE 플롯
t-SNE 플롯
보시다시피, 플롯의 왼쪽에는 '바나나', '망고', '오렌지', '코코넛', '사과'와 같은 과일 단어들이 모여 있습니다. 반면 '소', '개', '고양이'는 모두 동물이므로 서로 비슷한 위치에 있습니다.
따라서 모델이 의미론적 의미와 단어 간의 관계를 잘 파악할 수 있음을 알 수 있습니다.
어휘를 변경하거나 직접 모델을 생성하여 다양한 단어를 실험해 볼 수 있습니다.
생성된 임베딩 행렬은 단어 유사성 작업에 활용하거나, 신경망의 임베딩 레이어에 입력하는 등 다양하게 활용할 수 있습니다.
GloVe는 의미론적 의미를 도출하기 위해 동시 발생 행렬을 학습합니다. 단어-단어 동시 발생은 지식의 필수적인 부분이며, 통계적 접근 방식을 사용하여 단어 임베딩을 생성하는 것이 효과적인 방법이라는 아이디어에 기반합니다. 이것이 바로 GloVe가 최종 결과에 '