자율주행차가 CNN 기술을 사용하는 방법
어릴 적, 저는 스스로 움직이는 듯한 자동차가 나오는 만화를 즐겨 보았습니다. 그런 자동차가 현실이 될 수 있을까, 작은 로봇이 마법처럼 운전할 수 있을까 하는 상상을 하곤 했습니다.
세월이 흘러, 자율주행차가 실제로 등장하고 있습니다! 저는 이 기술에 깊은 관심을 갖게 되었습니다. 예를 들어, 자율주행차는 정지 신호나 빨간불에서 멈춰야 할 때를 어떻게 인지할까요? 도로를 건너는 동물이나 사람을 어떻게 감지할 수 있을까요? 어두운 밤이나 비, 눈이 오는 궂은 날씨 속에서는 어떻게 운전할까요?

자율주행차에 대해 좀 더 자세히 알아봅시다! 이는 사람이 운전하지 않아도 스스로 주행할 수 있는 자동차입니다. 테슬라, 웨이모 같은 회사들은 딥러닝과 같은 첨단 컴퓨터 기술을 이용하여 이러한 자동차를 매우 똑똑하게 만들고 있습니다. 딥러닝 기술은 자동차가 도로 표지판을 이해하고, 날씨가 좋지 않은 상황에서도 안전하게 운전하는 등 놀라운 일들을 가능하게 합니다. 첨단 기술은 미래의 이동 방식을 혁신하는 데 중요한 역할을 할 것입니다!
역사
자율주행차의 역사는 길고 흥미로운 여정과 같습니다. 자율주행차가 사람들의 상상 속에만 존재했던 1920년대를 떠올려 보세요. 당시, 프랜시스 후디나라는 창의적인 인물은 도로의 선을 따라가는 자동차를 개발하여 주목받았습니다. 하지만 이 자동차는 도로 아래에 설치된 특수 전선의 도움을 받아야 했습니다.
 출처: theatlantic.com
출처: theatlantic.com
1980년대와 1990년대에는 카네기 멜론 대학교의 연구진들이 큰 진전을 이루었습니다. 그들은 카메라를 사용하여 주변을 '볼' 수 있는 자동차를 개발했고, 이를 통해 복잡한 도시 도로를 주행할 수 있게 되었습니다. 마치 탐험가가 세상을 배우듯, 이 자동차들은 주변을 관찰하며 운전하는 방법을 익혔습니다.
2004년에는 사막 챌린지라는 중요한 계기가 마련되었습니다. 자율주행차가 등장하여 어려운 경주에 도전했습니다. 비록 우승하지는 못했지만, 이는 자율주행 기술의 발전을 위한 중요한 시작점이었습니다. 마치 더 나은 운전자가 되기 위한 훈련과 같았습니다.
하지만 실제적인 돌파구는 2000년대와 2010년대에 테슬라, 우버, 구글(현재 웨이모)과 같은 대기업들이 자율주행차 개발에 뛰어들면서 이루어졌습니다. 구글은 2009년부터 자율주행차 테스트를 시작했고, 2015년에는 테슬라 자동차가 특정 도로에서 부분적으로 스스로 운전할 수 있는 기능을 선보였습니다. 이 차량들은 사람의 개입 없이도 핸들링과 차선 유지를 수행할 수 있었습니다.
더 많은 기업들이 경쟁에 참여하면서 완전 자율주행차를 향한 경쟁은 더욱 치열해졌습니다. 사람이 조작하지 않아도 스스로 운전할 수 있는 자동차를 만들기 위해 경쟁하는 발명가들의 팀을 상상해 보세요.
하지만 이야기는 여기서 끝나지 않습니다. 우리는 여전히 스스로 운전하는 자동차를 개발하기 위해 노력하고 있으며, 이는 우리의 이동 방식을 완전히 바꿀 것입니다. 이 모험은 현재도 진행 중이며, 덕분에 더욱 안전하고 편리하게 여행할 수 있는 미래가 다가오고 있습니다.
자율주행차는 어떻게 작동할까요?
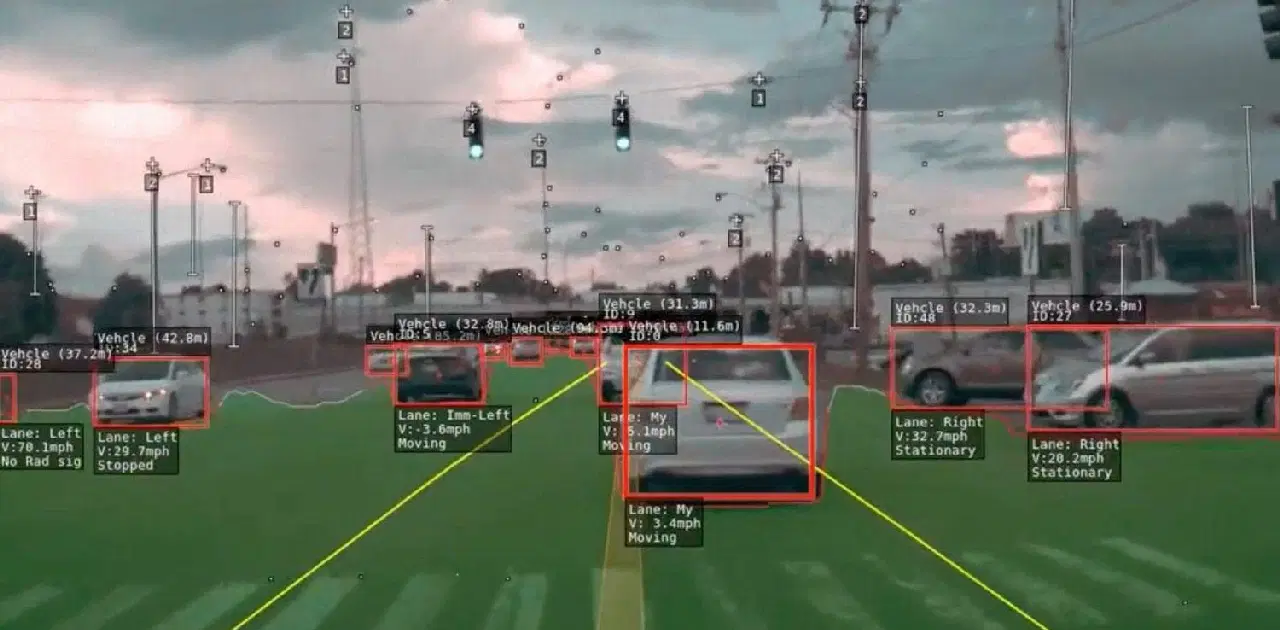
자율주행차는 매우 똑똑한 의사결정자와 같습니다! 이들은 카메라, LiDAR, RADAR, GPS, 그리고 관성 센서들을 사용하여 주변 환경에 대한 데이터를 수집합니다. 그런 다음, 딥러닝 알고리즘이라는 특별한 소프트웨어가 이 데이터를 분석하여 주변에서 무슨 일이 일어나고 있는지 파악합니다. 이러한 이해를 바탕으로 안전하고 부드러운 주행을 위한 중요한 결정을 내립니다.
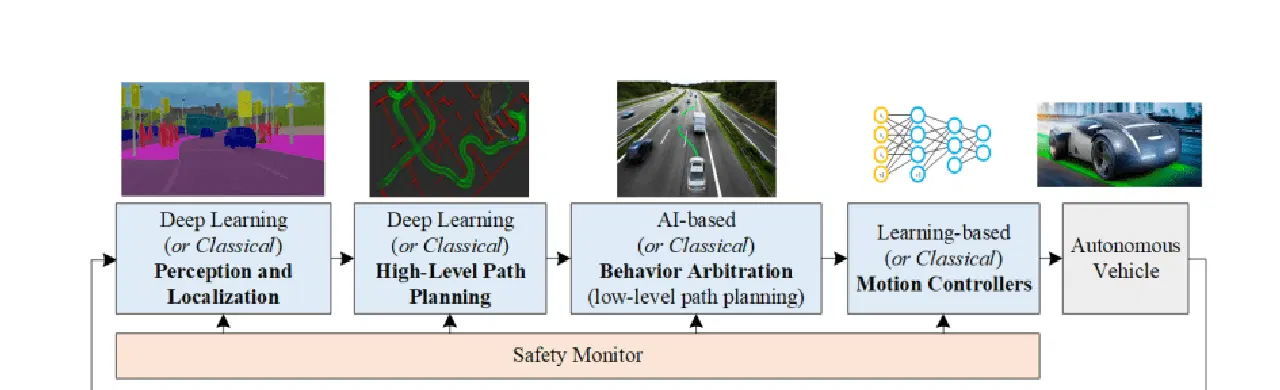 출처: arxiv.org
출처: arxiv.org
자율주행차가 실제로 어떻게 작동하는지 더 자세히 알아보기 위해, 위의 그림에서 보이는 네 가지 주요 단계를 살펴보겠습니다. 이는 마치 퍼즐을 맞추는 것과 같습니다. 각 조각을 이해하면 이 놀라운 자동차가 어떻게 작동하는지 전체 그림을 파악하는 데 도움이 될 것입니다.
- 인지
- 위치 파악
- 예측
- 의사 결정
- 고수준 경로 계획
- 행동 조정
- 모션 제어
인지
#1. 카메라
카메라는 자율주행차의 눈과 같아서 매우 중요합니다! 자동차가 주변에서 무슨 일이 일어나고 있는지 인식하는 데 도움을 줍니다. 이 카메라는 물체를 식별하고, 여러 부분을 구별하고, 자동차의 위치를 파악하는 등 다양한 작업을 수행합니다.
자동차의 전면, 후면, 좌우 측면에 카메라가 설치되어 있어 사각지대가 없도록 돕습니다. 이 카메라는 함께 작동하여 자동차 주변의 모든 것을 파악하는 넓은 시야를 제공합니다. 마치 자동차만의 특별한 360도 카메라와 같습니다!

이 카메라는 단순히 보기 위한 것이 아닙니다. 매우 똑똑합니다. 일부 카메라는 최대 200m 떨어진 곳까지 볼 수 있어 자동차가 앞으로 일어날 일을 미리 인지할 수 있습니다. 다른 카메라는 주변 물체에 집중하여 자동차가 세부 사항까지 놓치지 않도록 합니다. 이 카메라들은 마치 친구가 길을 안내하는 것처럼 자동차가 모든 것을 보고 이해하여 안전하게 운전하고 올바른 판단을 내릴 수 있도록 돕습니다.
특히 주차할 때처럼 때로는 카메라가 큰 도움이 됩니다. 넓은 시야를 제공하고, 신중하게 운전하여 올바른 결정을 내릴 수 있게 해주기 때문입니다.
그러나 카메라만 사용하는 데에는 몇 가지 문제점이 있습니다. 특히 안개, 폭우, 밤과 같은 악천후 속에서는 더욱 그렇습니다. 이런 상황에서는 카메라의 시야가 흐릿해지고 왜곡될 수 있어 안전을 위협할 수 있습니다.
이러한 어려운 상황에 대처하기 위해서는 어둠 속이나 야간에도 작동할 수 있는 특별한 센서가 필요합니다. 또한 빛이 없더라도 물체와의 거리를 측정할 수 있어야 합니다. 이러한 센서를 자동차의 눈(인식 시스템)에 장착하면 날씨가 좋지 않거나 시야가 좋지 않은 환경에서도 자동차의 운전 능력이 향상됩니다. 따라서 자동차는 더욱 안전하게 운전할 수 있으며 이는 도로를 이용하는 모든 사람에게 유익합니다.
#2. LiDAR
LiDAR(Light Detection and Ranging)는 빛을 사용하여 물체와의 거리를 측정하는 고급 기술입니다. LiDAR는 레이저 빔을 방출한 다음, 물체에 반사되어 돌아오는 시간을 측정하여 거리를 계산합니다.

LiDAR와 카메라가 함께 작동하면 자동차가 주변 환경을 더욱 명확하게 이해하는 데 도움이 됩니다. 이들은 자동차 주변의 3D 지도를 만들어냅니다. 이 특별한 정보는 스마트 컴퓨터 프로그램으로 분석되어 자동차가 다른 차량의 움직임을 예측하는 데 도움이 됩니다. 특히 복잡한 교차로와 같은 어려운 상황에서 유용합니다. 자동차가 주변 차량을 감시하고 안전하게 운전할 수 있도록 도와주기 때문입니다.
하지만 LiDAR에도 몇 가지 한계가 있습니다. 밤이나 어두운 환경에서는 잘 작동하지만, 비나 안개의 방해를 받으면 정확도가 떨어질 수 있습니다. 이러한 문제를 해결하기 위해 LiDAR와 RADAR 센서를 함께 사용합니다. 이러한 센서들은 자동차가 주변을 더 잘 이해할 수 있도록 추가 정보를 제공합니다. 자동차는 더욱 안전하고 효율적으로 스스로 주행할 수 있게 됩니다.
#3. 레이더
RADAR는 Radio Detection and Ranging의 약자로 오랫동안 군사 및 일상생활에 사용되어 왔습니다. 원래 군대에서 물체를 탐지하는 데 사용되었던 RADAR는 전파 신호를 이용하여 거리를 측정합니다. 오늘날 RADAR는 많은 자동차, 특히 자율주행차에 필수적인 요소가 되었습니다.
RADAR는 날씨나 빛의 조건에 관계없이 작동할 수 있다는 점에서 매우 뛰어납니다. 레이저 대신 전파를 사용하므로 유연하고 매우 유용합니다. 하지만 RADAR는 노이즈가 많은 센서로 간주됩니다. 즉, 카메라에는 장애물이 보이지 않더라도 이를 감지할 수 있다는 뜻입니다.

자율주행차의 두뇌는 RADAR에서 발생하는 불필요한 신호들 때문에 혼란을 느낄 수 있습니다. 이 문제를 해결하기 위해서는 RADAR 정보를 정리하여 자동차가 올바른 결정을 내릴 수 있도록 해야 합니다.
데이터를 정리한다는 것은 중요한 신호와 중요하지 않은 신호를 분리하는 것과 같은 특별한 기술을 사용하여 강한 신호와 약한 신호를 구별하는 것을 의미합니다. 또한 자동차는 FFT(Fast Fourier Transforms)라는 고급 기술을 활용하여 정보를 더욱 잘 이해합니다.
RADAR와 LiDAR는 마치 종이 위에 찍힌 점과 같은 단일 지점에 대한 정보를 제공합니다. 이러한 점들을 더 잘 이해하기 위해 자동차는 그룹화와 같은 기술을 사용합니다. 이는 비슷한 것들을 하나로 모으는 것과 같습니다. 자동차는 유클리드 클러스터링이나 K-평균 클러스터링과 같은 통계적 방법을 사용하여 비슷한 점들을 결합하고 이해합니다. 이를 통해 자동차는 더욱 스마트하고 안전하게 운전할 수 있습니다.
위치 파악
자율주행차에서 위치 파악 알고리즘은 VO(Visual Odometry)로 알려진 차량의 위치와 방향을 결정하는 데 중요한 역할을 합니다. VO는 연속된 비디오 프레임에서 핵심 포인트를 식별하고 일치시키는 방식으로 작동합니다.
자동차는 지도상의 표시와 같은 특정 정보 포인트를 분석합니다. 그런 다음, SLAM이라는 통계적 방법을 사용하여 물체가 어디에 있고 어떻게 움직이는지 파악합니다. 이는 자동차가 도로와 사람을 포함한 주변 환경을 이해하는 데 도움이 됩니다.

더욱 효율적인 작동을 위해 자동차는 딥러닝 기술을 사용합니다. 이는 매우 똑똑한 컴퓨터와 같습니다.
이러한 기술을 통해 자동차는 주변을 매우 잘 이해할 수 있습니다. PoseNet 및 VLocNet++와 같은 신경망은 점 데이터를 이용하여 물체의 3D 위치와 방향을 추정합니다. 이러한 추정된 3D 위치와 방향은 아래 이미지에서 볼 수 있듯이 장면의 의미를 도출하는 데 사용됩니다. 자동차가 수학과 스마트 컴퓨터 기술을 활용하여 자신의 위치와 주변 환경을 파악할 수 있게 됩니다. 이는 자동차가 안전하고 원활하게 주행할 수 있도록 돕습니다.
예측
사람 운전자의 행동을 이해하는 것은 단순한 논리 이상의 복잡한 문제입니다. 인간의 감정과 반응이 포함되어 있기 때문입니다. 다른 운전자가 무엇을 할지 예측하기 어렵기 때문에, 자율주행차가 그들의 행동을 정확히 예측하는 것이 매우 중요합니다. 이는 도로 안전을 보장하는 데 핵심적인 역할을 합니다.
자율주행차가 360도 시야를 가지고 있어 주변에서 일어나는 모든 일을 볼 수 있다고 상상해 보세요. 자동차는 이 정보를 딥러닝에 사용합니다. 그리고 영리한 기술을 사용하여 다른 운전자의 행동을 예측합니다. 이는 마치 게임에서 이기기 위해 미리 계획을 세우는 것과 비슷합니다.
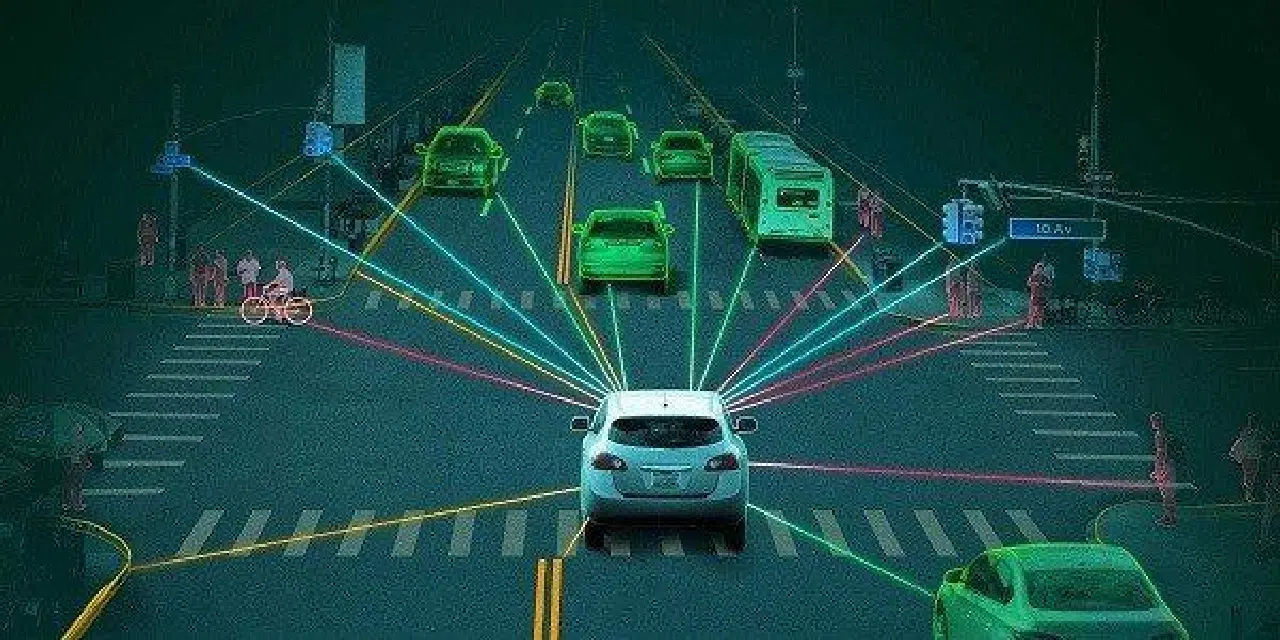
자율주행차의 특수 센서는 마치 눈과 같습니다. 자동차가 사진에 있는 물체를 식별하고, 주변의 물체를 찾고, 위치를 파악하고, 물체가 어디에서 끝나는지 알 수 있도록 도와줍니다. 이는 자동차가 주변을 파악하고 현명한 선택을 하는 데 도움이 됩니다.
학습 과정에서 딥러닝 알고리즘은 LiDAR 및 RADAR에서 수집된 이미지와 클라우드 데이터 포인트에서 복잡한 정보를 모델링합니다. 실제 주행 중(추론 단계)에 동일한 모델은 자동차가 제동, 정지, 감속, 차선 변경과 같은 가능한 움직임을 준비하는 데 도움이 됩니다.
딥러닝은 자동차의 똑똑한 도우미와 같습니다. 자동차가 불확실한 상황을 이해하고, 위치를 파악하고, 운전을 더욱 능숙하게 할 수 있도록 도와줍니다. 덕분에 안전하고 부드러운 주행이 가능해집니다.
하지만 어려운 점은 여러 선택지 중에서 최선의 행동을 결정하는 것입니다. 올바른 움직임을 선택하려면 자동차가 안전하게 운전할 수 있도록 신중한 판단이 필요합니다.
의사 결정
자율주행차는 어려운 상황에서 중요한 결정을 내려야 합니다. 쉽지 않은 일입니다. 센서가 항상 정확하지 않을 수 있고, 도로에 있는 사람들이 예상치 못한 행동을 할 수 있기 때문입니다. 따라서 자동차는 충돌을 피하기 위해 다른 사람이 무엇을 할지 예측하고 그에 맞춰 움직여야 합니다.
결정을 내리기 위해서는 자동차에 많은 정보가 필요합니다. 자동차는 센서를 이용하여 이 정보를 수집한 다음, 딥러닝 알고리즘을 사용하여 물체의 위치를 파악하고 무슨 일이 일어날지 예측합니다. 위치 파악은 자동차가 초기 위치를 설정하는 데 도움을 주고, 예측은 주변 환경에 따라 여러 가능한 행동을 생성합니다.
하지만 남는 질문이 있습니다. 자동차는 어떻게 수많은 예측된 행동 중에서 최선의 행동을 선택할까요?
 출처: semanticscholar.org
출처: semanticscholar.org
DRL(Deep Reinforcement Learning)은 MDP(Markov Decision Process)라는 알고리즘을 사용하여 의사결정을 내리는 기술입니다. MDP는 도로 위의 사람들이 미래에 어떻게 행동할지 예측하는 데 도움이 됩니다. 움직이는 물체가 많아질수록 상황은 더욱 복잡해집니다. 따라서 자율주행차는 더 많은 가능한 행동을 고려해야 합니다.
자동차에 가장 적합한 움직임을 찾는 문제를 해결하기 위해 베이지안 최적화를 사용하여 딥러닝 모델을 최적화했습니다. 때로는 의사결정을 위해 은닉 마르코프 모델과 베이지안 최적화를 결합한 프레임워크가 사용되어 자율주행차가 다양하고 복잡한 시나리오에서 효과적이고 안전하게 주행할 수 있도록 돕습니다.
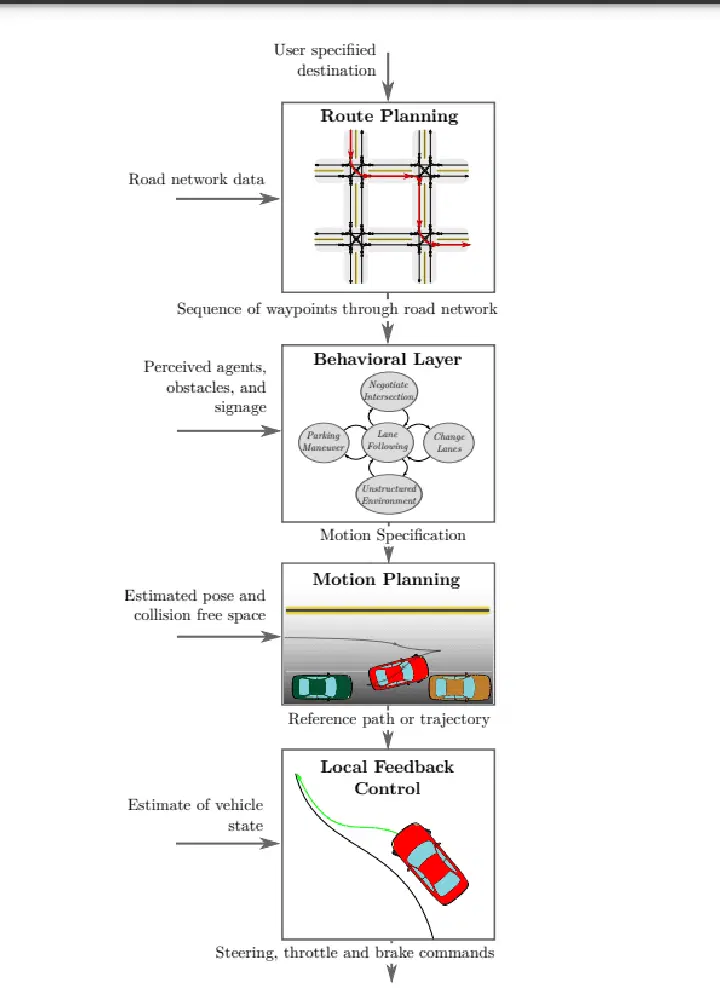 원천: arxiv.org
원천: arxiv.org
자율주행차의 의사결정 과정은 네 가지 주요 요소로 구성된 계층적 프로세스를 따릅니다.
경로 또는 경로 계획: 여행 시작 시 자동차는 현재 위치에서 목적지까지 가장 좋은 경로를 결정합니다. 다양한 경로 중에서 최적의 해결책을 찾는 것이 목표입니다.
행동 조정: 자동차는 경로를 계획한 후 그 경로를 따라 운전해야 합니다. 자동차는 도로 표지판이나 교차로와 같은 정적인 물체를 인식할 수 있지만, 다른 운전자의 정확한 행동을 예측할 수는 없습니다. 이러한 불확실성을 처리하기 위해 계획을 세울 때 MDP(Markov Decision Process)와 같은 스마트 방법을 사용합니다.
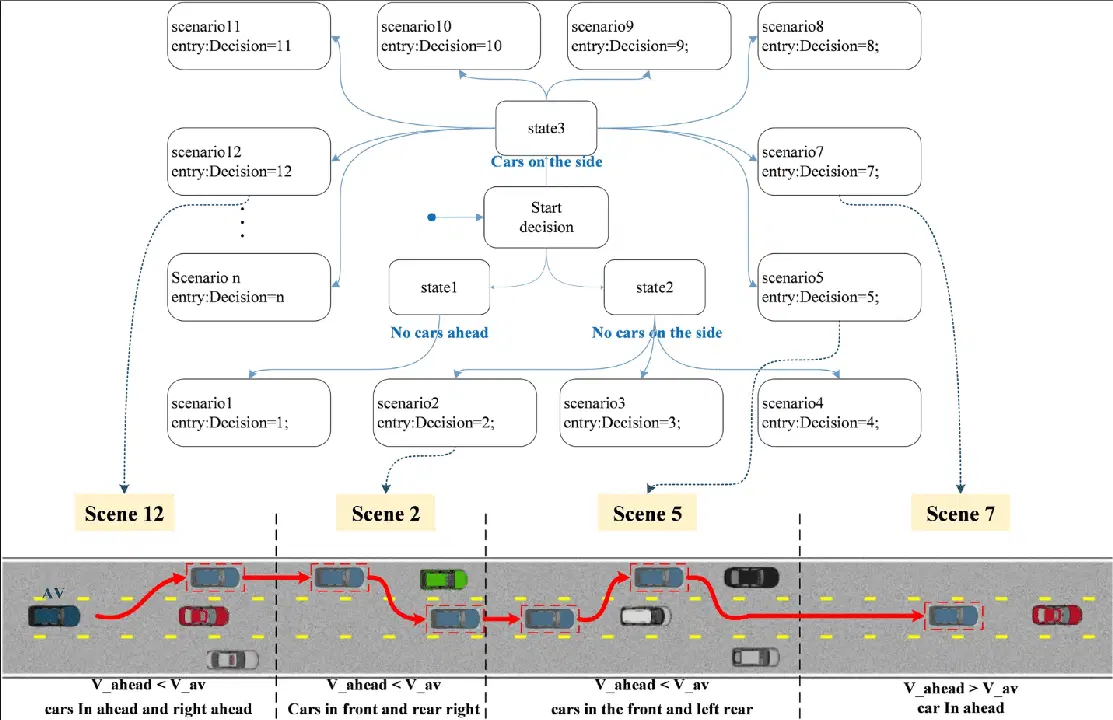
모션 계획: 계획된 경로와 행동 방법에 따라 모션 계획 시스템은 자동차의 움직임을 조정합니다. 이는 자동차가 탑승자에게 안전하고 편안한 방식으로 움직이도록 하는 것을 의미합니다. 속도, 차선 변경, 주변 환경 등을 고려합니다.
차량 제어: 마지막 단계는 차량 제어입니다. 모션 계획 시스템에서 생성된 경로를 따라가면서 차량이 원활하고 안전하게 움직이도록 보장합니다.
의사결정 과정을 이렇게 여러 단계로 나누면 자율주행차는 복잡한 환경에서도 안전하고 효과적으로 주행할 수 있습니다. 이를 통해 탑승자는 부드럽고 편안한 승차감을 경험할 수 있습니다.
컨볼루션 신경망
CNN(컨볼루션 신경망)은 공간 정보, 특히 이미지를 모델링하는 능력 때문에 자율주행차에 널리 사용됩니다. CNN은 이미지에서 특징을 추출하는 데 탁월하여 다양한 물체를 식별하는 데 도움을 줍니다.
CNN에서는 네트워크의 깊이가 깊어질수록 다양한 레이어가 여러 패턴을 포착합니다. 초기 레이어는 가장자리와 같은 단순한 특징을 감지하는 반면, 더 깊은 레이어는 물체의 모양(나무의 잎, 자동차의 타이어 등)과 같은 더욱 복잡한 특징을 인식합니다. 이러한 적응성 때문에 CNN은 자율주행차의 핵심 알고리즘으로 자리 잡았습니다.
CNN의 핵심 구성 요소는 컨볼루션 커널(필터 매트릭스)을 사용하여 입력 이미지의 로컬 영역을 처리하는 컨볼루션 레이어입니다.
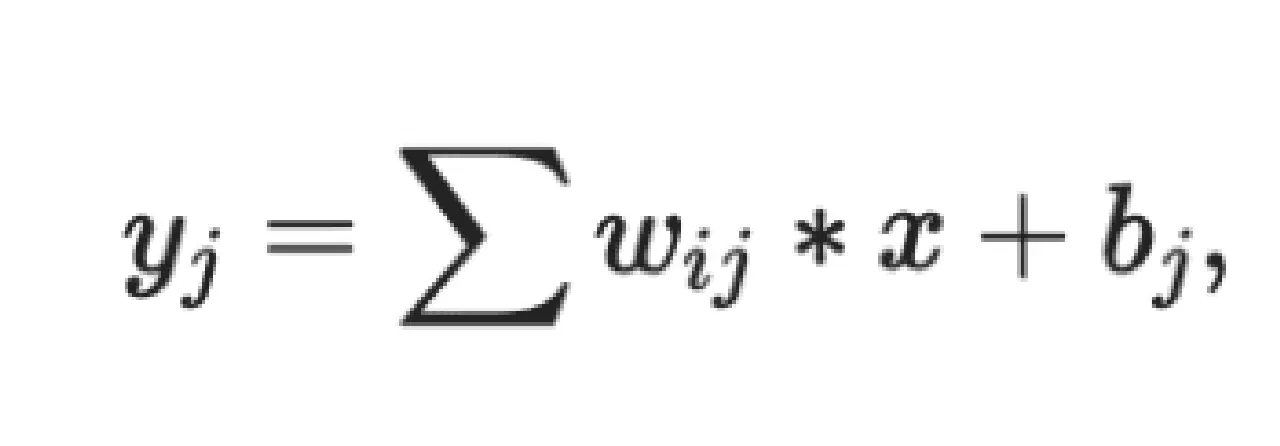
훈련 과정에서 필터 행렬이 업데이트되어 의미 있는 가중치를 얻습니다. CNN의 핵심 속성은 가중치 공유입니다. 즉, 동일한 가중치 파라미터를 사용하여 다양한 변환을 표현하고, 처리 공간을 절약하며, 다양한 특징 표현이 가능합니다.
컨볼루션 레이어의 출력은 일반적으로 Sigmoid, Tanh 또는 ReLU와 같은 비선형 활성화 함수를 거칩니다. ReLU는 다른 것보다 빠르게 수렴하므로 선호됩니다. 또한 결과는 종종 최대 풀링 레이어를 통과합니다. 이를 통해 배경이나 질감과 같은 이미지의 중요한 세부 사항을 유지할 수 있습니다.
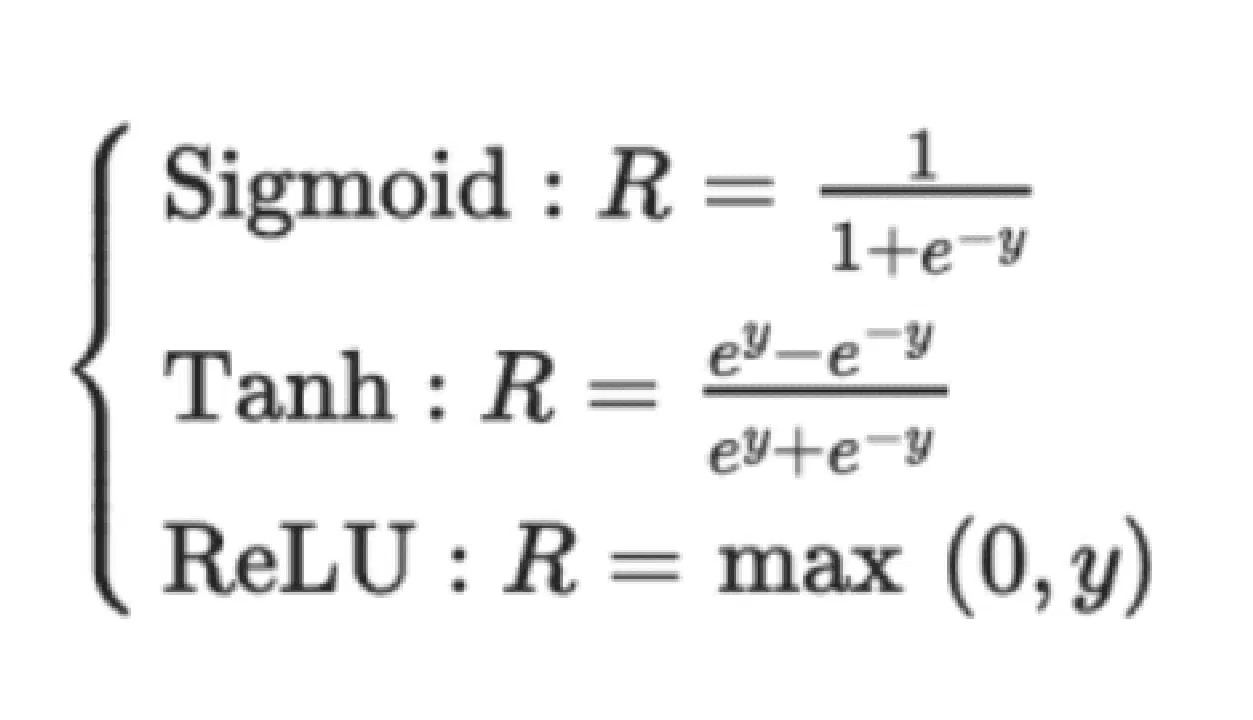
CNN의 세 가지 필수 속성 덕분에 CNN은 자율주행차에 다용도로 사용되는 핵심 요소가 되었습니다.
- 로컬 수용 필드
- 공유 가중치
- 공간 샘플링
이러한 속성은 과적합을 줄이고 이미지 분류, 분할, 위치 파악 등에 중요한 표현과 기능을 저장합니다.
자율주행차를 개발하는 기업들이 사용하는 두 가지 CNN 네트워크는 다음과 같습니다.
- 테슬라의 HydraNet
- 구글 웨이모의 ChauffeurNet
컨볼루션 신경망에 대해 자세히 알아보십시오.
#1. 테슬라의 HydraNet
HydraNet은 Ravi 등이 제시한 동적 아키텍처로, 2018년에 자율주행차의 의미 분할을 위해 개발되었습니다. 핵심 목표는 추론 과정에서의 계산 효율성을 개선하는 것입니다.
HydraNet의 개념에는 특정 작업에 할당된 '분기'라고 불리는 다양한 CNN 네트워크가 포함됩니다. 각 분기는 다른 입력을 받고, 네트워크는 추론 중에 실행할 분기를 선택적으로 선택할 수 있습니다. 그런 다음 여러 분기의 출력을 결합하여 최종 결정을 내립니다.
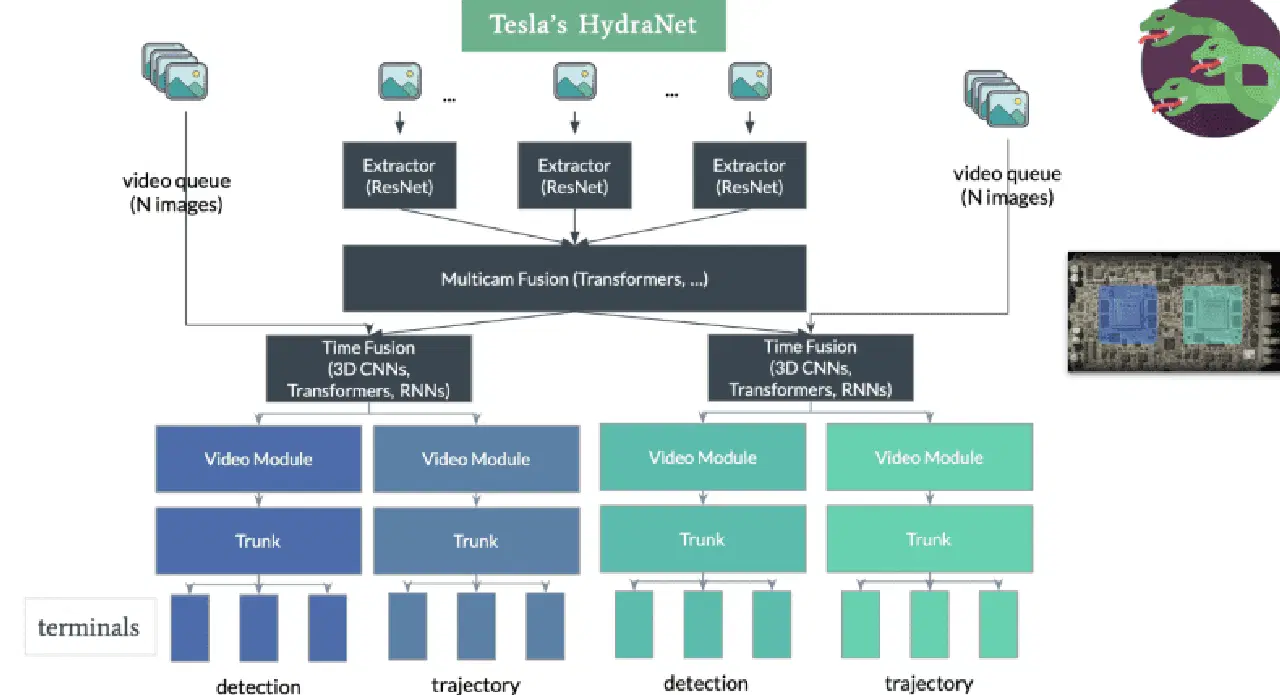
자율주행차의 경우, 입력은 나무, 도로 난간과 같은 정적인 물체, 도로와 차선, 신호등 등 환경의 다양한 측면을 나타낼 수 있습니다. 이러한 입력은 별도의 분기에서 훈련됩니다. 추론 과정에서 게이트 메커니즘은 활성화할 분기를 결정하고, 결합기는 해당 출력을 모아 최종 결정을 내립니다.
테슬라는 추론 과정에서 개별 작업에 대한 데이터를 분리하는 문제를 해결하기 위해 공유 백본을 통합하는 HydraNet 아키텍처를 채택했습니다. 일반적으로 수정된 ResNet-50 블록인 공유 백본을 사용하면 네트워크가 모든 객체 데이터에 대해 훈련될 수 있습니다. U-Net과 같은 의미 분할 아키텍처를 기반으로 하는 작업별 헤드를 사용하면 모델이 각 작업에 특정한 출력을 예측할 수 있습니다.
테슬라의 HydraNet은 환경을 모든 각도에서 3D로 표현하는 데 뛰어납니다. 이러한 향상된 차원성은 자동차의 주행 능력을 개선하는 데 도움이 됩니다. 놀랍게도 테슬라는 LiDAR 센서를 사용하지 않고 이러한 기능을 달성했습니다. 대신 카메라와 레이더 두 가지 센서에만 의존합니다. 테슬라 HydraNet의 효율성을 통해 8대의 카메라에서 얻은 정보를 처리하고 깊이 인식을 생성할 수 있어 LiDAR 기술 없이도 인상적인 성능을 보여줍니다.
#2. 구글 웨이모의 ChauffeurNet
ChauffeurNet은 구글 웨이모에서 모방 학습을 사용하여 자율주행차를 훈련하는 데 사용하는 RNN 기반 신경망입니다. 주로 주행 경로를 생성하기 위해 RNN에 의존하지만, FeatureNet이라는 CNN 구성 요소도 통합합니다.
이 컨볼루션 특징 네트워크는 다른 네트워크에서 공유하는 상황별 특징 표현을 추출하고, 인식 시스템에서 특징을 추출하는 데 사용됩니다.
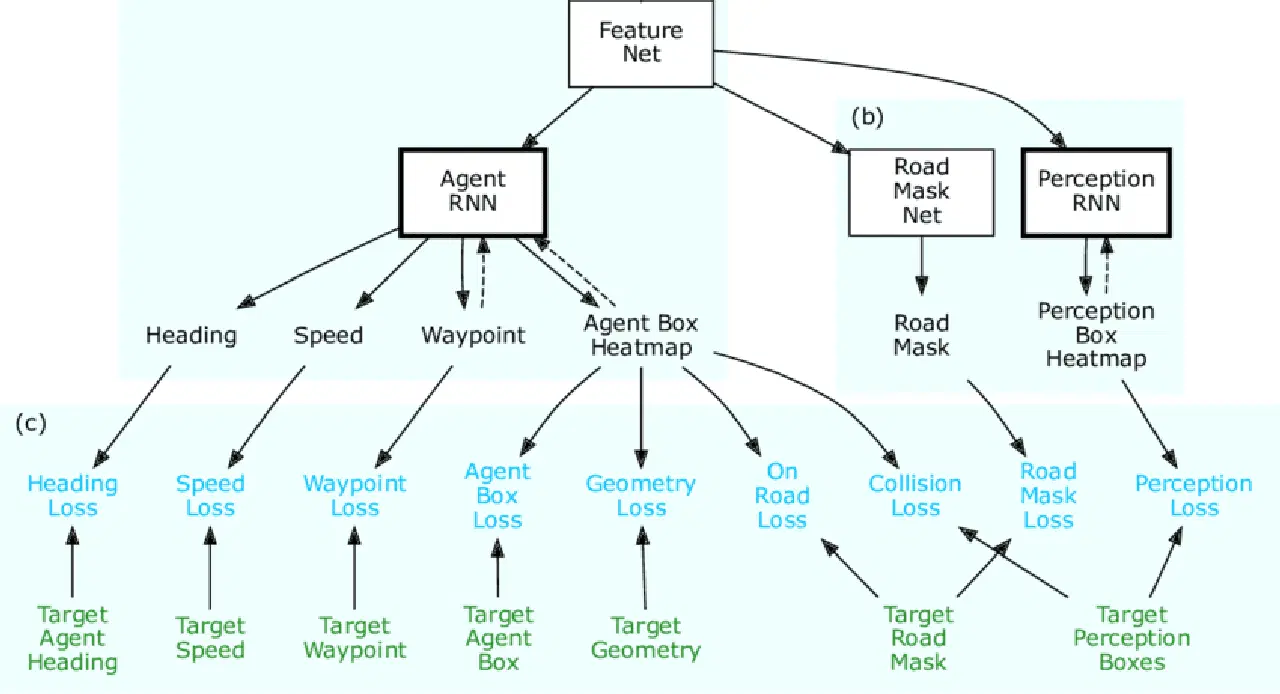 원천: 리서치게이트
원천: 리서치게이트
ChauffeurNet의 기본 아이디어는 모방 학습을 통해 전문 운전자를 모방함으로써 자율주행차를 훈련하는 것입니다. 'ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Wors'라는 논문의 저자들은 실제 훈련 데이터가 부족하다는 문제를 극복하기 위해 합성 데이터를 도입했습니다.
이 합성 데이터는 주행 경로 왜곡, 장애물 추가, 인위적인 장면 생성과 같은 다양한 변화를 포함합니다. 실제 데이터만 사용하는 것보다 합성 데이터를 사용하여 자동차를 훈련하는 것이 더 효과적인 것으로 나타났습니다.
ChauffeurNet에서 인식 시스템은 최종 프로세스의 일부가 아니라 중간 수준 시스템의 역할을 합니다. 네트워크는 인식 시스템에서 다양한 입력 변형을 받을 수 있습니다. 또한 네트워크는 센서에서 장면의 중간 수준 표현을 관찰하고, 이 입력을 합성 데이터와 함께 사용하여 전문가의 운전 행동을 모방합니다.
ChauffeurNet은 인식 작업을 제외하고 환경에 대한 조감도를 생성하여 더 쉬운 전이 학습을 촉진하고, 네트워크가 실제 데이터와 시뮬레이션 데이터를 기반으로 더 나은 결정을 내릴 수 있도록 돕습니다. 네트워크는 중간 수준 표현을 바탕으로 운전 경로의 연속된 지점을 반복적으로 예측하여 주행 경로를 생성합니다. 이러한 접근 방식은 자율주행차를 더욱 효과적으로 훈련시켜 안전하고 신뢰할 수 있는 자율 주행 시스템을 개발하는 데 큰 도움이 될 수 있음을 보여주었습니다.
#3. 자율주행차에 사용되는 부분적으로 관찰 가능한 마르코프 결정 프로세스
부분적으로 관찰 가능한 마르코프 결정 프로세스(POMDP)는 불확실한 상황에서 의사결정을 내리기 위해 자율주행차에 사용되는 수학적 프레임워크입니다. 실제 상황에서 자율주행차는 센서 오류, 폐색 또는 불완전한 인식 시스템으로 인해 주변 환경에 대한 정보가 제한적인 경우가 많습니다. POMDP는 이러한 부분적인 관찰 가능성을 처리하고, 불확실성과 사용 가능한 관찰을 모두 고려하여 최적의 결정을 내리도록 설계되었습니다.
POMDP에서 의사결정 주체는 부분적으로 관찰 가능한 상태의 환경에서 작동합니다. 주체는 행동을 취하고, 환경은 확률적으로 새로운 상태로 전환됩니다. 하지만 주체는 환경의 실제 상태에 대한 부분적이거나 노이즈가 포함된 정보만을 받습니다. 목표는 환경의 불확실성과 주체의 관찰을 모두 고려하면서 시간이 지남에 따라 예상되는 누적 보상을 극대화하는 정책을 찾는 것입니다.
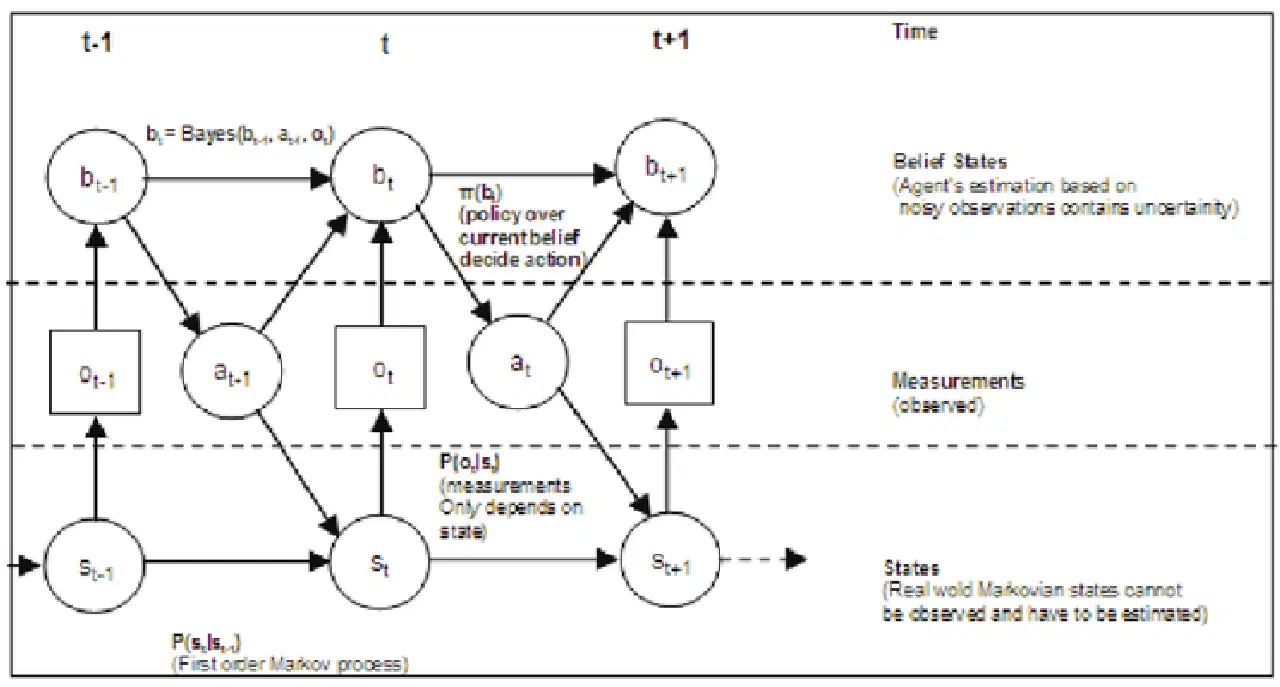 원천: 리서치게이트
원천: 리서치게이트
자율주행차의 경우, POMDP는 모션 계획, 경로 예측, 다른 도로 이용자와의 상호 작용과 같은 작업에 특히 유용합니다. 자율주행차는 주변 환경의 불확실성을 고려하여 POMDP를 사용하여 차선 변경, 속도 조절, 보행자 및 다른 차량과의 상호 작용에 대한 결정을 내릴 수 있습니다.
POMDP는 다음과 같은 6가지 요소로 구성되어 있으며, POMDP = (I, S, A, R, P, γ)로 표시할 수 있습니다.
여기서,
I: 관찰
S: 상태의 유한 집합
A: 동작의 유한 집합
R: 보상 함수
P: 전환 확률 함수
γ: 미래 보상에 대한 할인 요소
POMDP는 고려해야 할 가능성이 많은 상태와 관찰 때문에 계산이 어려울 수 있습니다. 하지만 최적의 정책을 효율적으로 근사화하고, 자율주행차의 실시간 의사결정을 가능하게 하기 위해 신념 공간 계획 및 몬테카를로 방법과 같은 고급 알고리즘이 사용되기도 합니다.
POMDP를 의사결정 알고리즘에 통합함으로써 자율주행차는 복잡하고 불확실한 환경을 더욱 효과적이고 안전하게 탐색할 수 있으며, 센서의 불확실성을 고려하고, 정보를 기반으로 결정을 내려 목표를 달성할 수 있습니다.
주체 역할을 하는 자율주행차는 머신러닝의 일종인 강화 학습(RL)을 통해 환경과 상호작용하며 학습합니다. 상태, 행동, 보상은 심층 강화 학습(DRL)의 핵심에 있는 세 가지 중요한 변수입니다.
상태(State): 도로에서의 위치와 같이 특정 시점에서의 자율주행차의 현재 상태를 설명합니다.
행동(Action): 차선 변경 또는 속도 조절과 같은 결정을 포함하여 자동차가 할 수 있는 모든 가능한 움직임을 나타냅니다.
보상(Reward): 자동차가 특정 행동을 할 때마다 피드백을 제공합니다. 보상은 긍정적일 수도 있고 부정적일 수도 있으며, DRL의 목표는 누적 보상을 최대화하는 것입니다.
알고리즘에 올바른 동작이 명시적으로 제공되는 지도 학습과 달리 DRL은 환경을 탐색하고 해당 동작에 따라 보상을 받음으로써 학습합니다. 자율주행차의 신경망은 CNN(Convolutional Neural Network)에서 추출한 특징을 포함하는 인식 데이터를 기반으로 훈련됩니다.
그런 다음, DRL 알고리즘은 입력의 저차원 변환인 이러한 표현에 대해 훈련되어 추론 과정에서 보다 효율적인 의사결정이 가능합니다.
실제 상황에서 자율주행차를 훈련하는 것은 위험하고 비현실적입니다. 대신 사람의 안전에 위험이 없는 시뮬레이터에서 훈련을 받습니다.
 모의 실험 장치
모의 실험 장치
일부 오픈 소스 시뮬레이터는 다음과 같습니다.
인식 데이터와 강화 학습을 결합함으로써 자율주행차는 복잡한 환경을 탐색하는 방법을 학습하고, 안전하고 최적의 결정을 내리며, 실제 운전 상황에 더 잘 대처할 수 있게 됩니다.
자주 묻는 질문
자율주행차란 무엇인가요