스크래핑 브라우저로 데이터 추출이 쉽습니다.
웹 페이지에서 특정 정보를 수집하는 과정, 즉 데이터 추출은 다양한 목적으로 활용됩니다. 사용자들은 텍스트, 이미지, 비디오, 리뷰, 상품 정보 등 다양한 형태의 데이터를 추출할 수 있습니다. 이렇게 추출된 데이터는 시장 조사, 감정 분석, 경쟁사 분석, 그리고 데이터 집계와 같은 다양한 분야에서 활용될 수 있습니다.
만약 처리해야 할 데이터의 양이 적다면, 웹 페이지에서 필요한 정보를 복사하여 스프레드시트나 문서 형태로 붙여넣는 수동적인 방법으로도 데이터 추출이 가능합니다. 예를 들어, 소비자들이 구매 결정을 내리는 데 도움을 주는 온라인 리뷰 정보를 수동으로 수집할 수 있습니다.
하지만, 대규모 데이터 세트를 다루어야 할 경우에는 자동화된 데이터 추출 기술이 필수적입니다. 자체적으로 데이터 추출 솔루션을 구축하거나, Proxy API 또는 Scraping API와 같은 도구를 활용할 수 있습니다.
그러나 이러한 기술들은 대상 웹사이트가 보안 문자 등으로 보호되어 있는 경우 효율성이 떨어질 수 있습니다. 봇과 프록시를 관리해야 하는 추가적인 부담도 발생합니다. 이러한 작업들은 상당한 시간과 노력을 요구하며, 추출할 수 있는 데이터의 범위에도 제약을 줄 수 있습니다.
스크래핑 브라우저: 해결책
Bright Data의 스크래핑 브라우저는 이러한 모든 문제점을 해결할 수 있는 효과적인 대안입니다. 이 올인원 브라우저는 기존 방식으로는 데이터 수집이 어려웠던 웹사이트에서도 손쉽게 데이터를 추출할 수 있도록 돕습니다. 그래픽 사용자 인터페이스(GUI)를 제공하며, Puppeteer 또는 Playwright API를 통해 제어되므로 봇으로 감지될 위험이 적습니다.
스크래핑 브라우저에는 사용자 대신 모든 차단 문제를 자동으로 처리하는 기능이 내장되어 있습니다. 또한 Bright Data 서버에서 실행되므로, 대규모 데이터 추출 프로젝트를 위해 값비싼 자체 인프라를 구축할 필요가 없습니다.
Bright Data 스크래핑 브라우저의 주요 특징
- 자동 웹사이트 차단 해제: CAPTCHA 해결, 새로운 차단 규칙, 지문 인식, 재시도 등의 문제를 자동으로 처리하여 사용자가 브라우저를 계속 새로 고칠 필요가 없습니다. 실제 사용자와 유사하게 작동하여 봇 감지를 피합니다.
- 대규모 프록시 네트워크: 7200만 개 이상의 IP 주소를 보유하고 있어 원하는 국가를 타겟팅할 수 있습니다. 특정 도시나 이동통신사를 대상으로 데이터 추출이 가능하며, 동급 최고의 기술을 활용할 수 있습니다.
- 확장성: Bright Data의 강력한 인프라를 기반으로 작동하므로, 수천 개의 세션을 동시에 실행할 수 있습니다.
- Puppeteer 및 Playwright 호환성: Puppeteer(Python) 또는 Playwright(Node.js)를 사용하여 API 호출을 수행하고 여러 브라우저 세션을 관리할 수 있습니다.
- 시간 및 리소스 절약: 사용자가 직접 프록시를 설정할 필요 없이, 스크래핑 브라우저가 백그라운드에서 모든 작업을 처리합니다. 자체 인프라 구축에 드는 비용과 시간을 절약할 수 있습니다.
스크래핑 브라우저 설정 방법
- Bright Data 웹사이트에 접속하여 "스크래핑 솔루션" 탭에서 스크래핑 브라우저를 선택합니다.
- 계정을 생성합니다. "무료 평가판 시작" 또는 "Google 계정으로 시작" 옵션을 선택할 수 있습니다. 여기서는 "무료 평가판 시작"을 선택하고 다음 단계를 진행하겠습니다.
- 계정이 생성되면 대시보드에서 "프록시 및 스크래핑 인프라" 옵션을 선택합니다.
- 새 창에서 스크래핑 브라우저를 선택하고 "시작하기"를 클릭합니다.
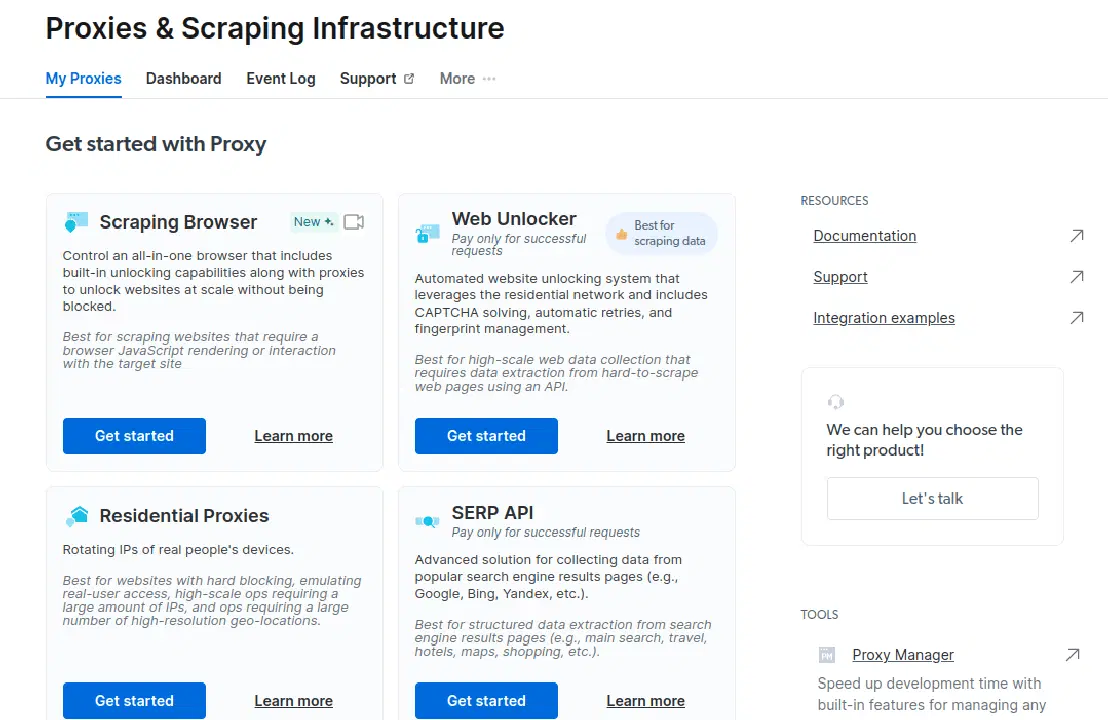
- 구성을 저장하고 활성화합니다.
- 무료 평가판을 활성화합니다. 첫 번째 옵션은 프록시 사용을 위한 $5 크레딧을 제공합니다. 만약 많은 데이터를 처리해야 한다면, $50 이상 충전시 $50를 추가로 받을 수 있는 두 번째 옵션을 선택할 수 있습니다.
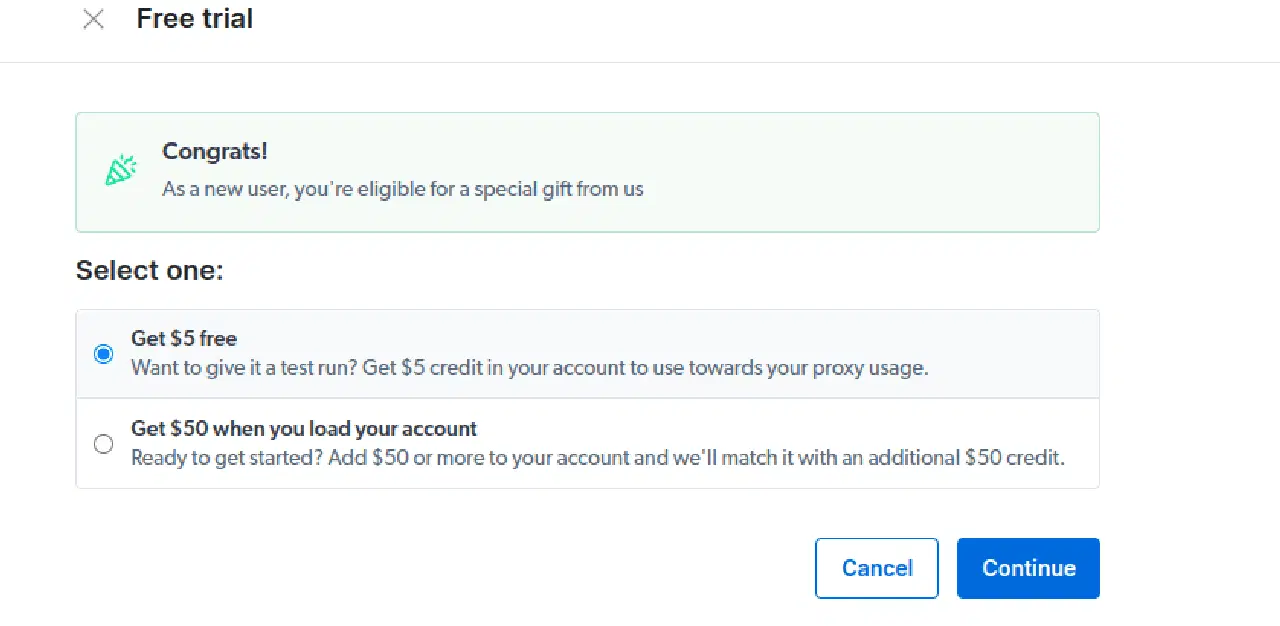
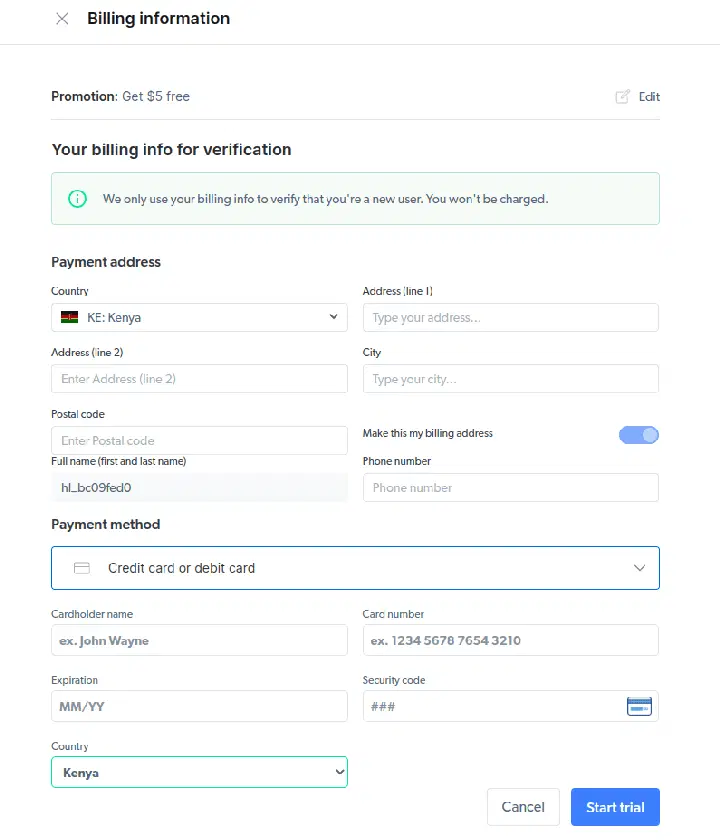
- 결제 정보를 입력합니다. 플랫폼에서는 실제로 요금이 청구되지 않으며, 사용자가 여러 계정을 생성하여 무료 혜택을 악용하는 것을 방지하기 위해 필요한 절차입니다.
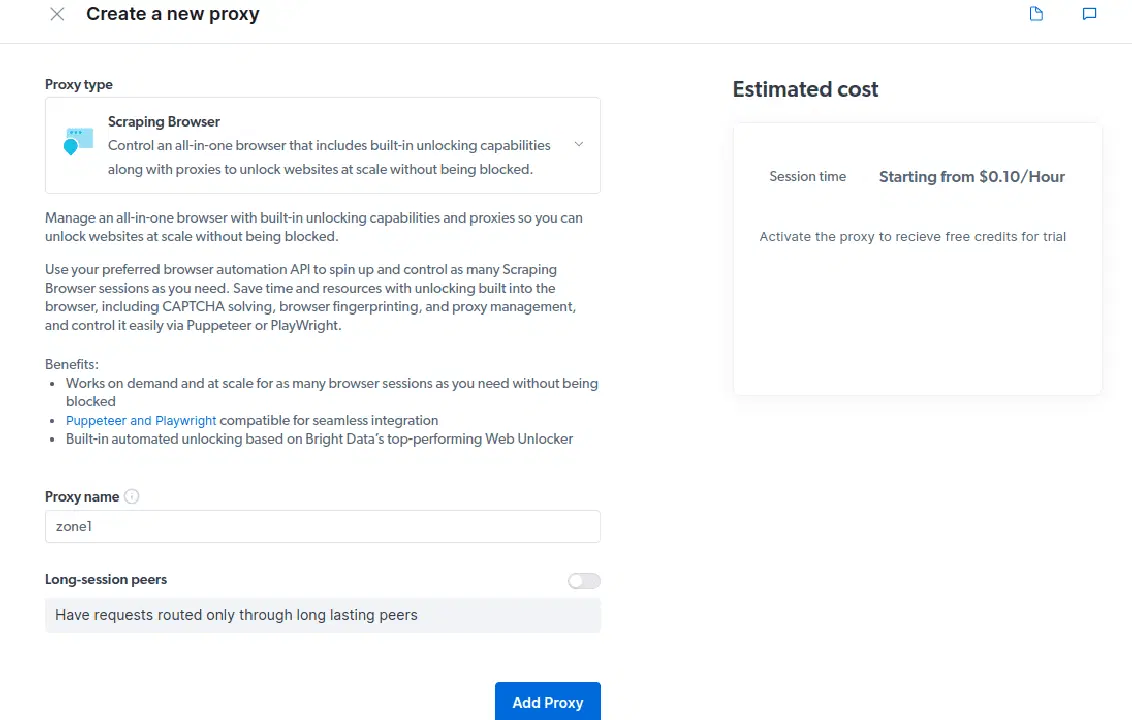
- 새 프록시를 만듭니다. 결제 정보를 저장한 후, "추가" 아이콘을 클릭하고 프록시 유형으로 "스크래핑 브라우저"를 선택합니다. "프록시 추가"를 클릭하여 다음 단계로 이동합니다.
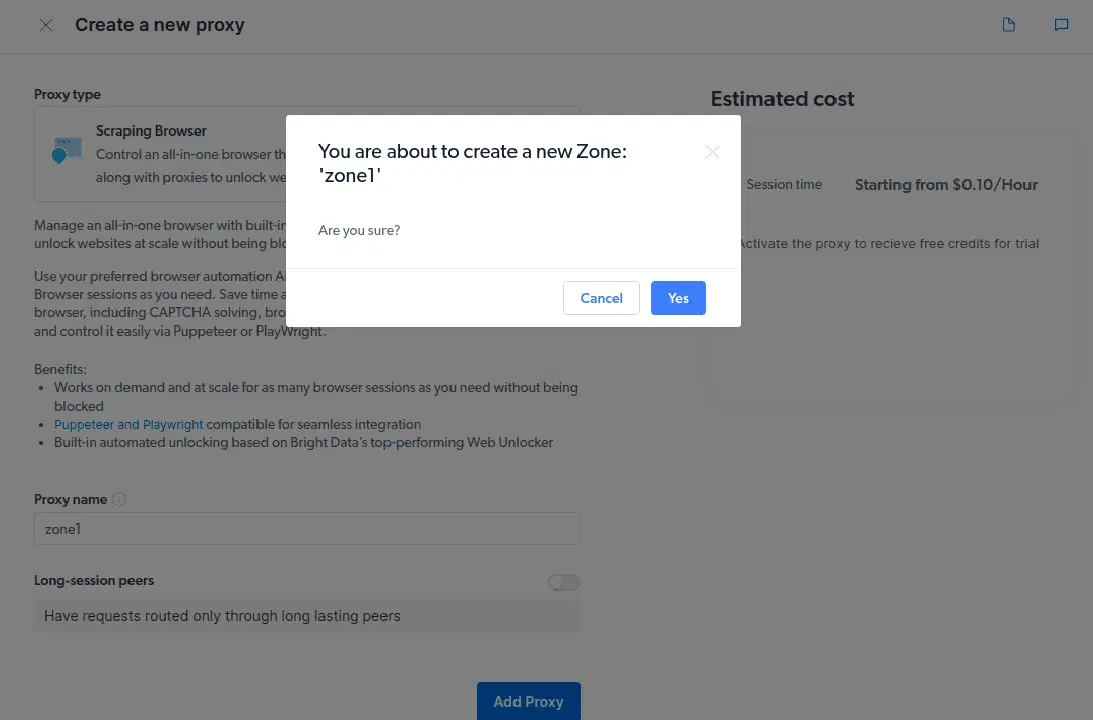
- 새 "영역"을 만듭니다. 새 영역을 만들 것인지 묻는 팝업 창이 나타나면 "예"를 클릭하고 계속 진행합니다.
- "코드 및 통합 예제 확인"을 클릭합니다. 이제 대상 웹사이트에서 데이터를 추출하는 데 사용할 수 있는 프록시 통합 예시 코드를 얻을 수 있습니다. Node.js 또는 Python을 사용하여 데이터를 추출할 수 있습니다.
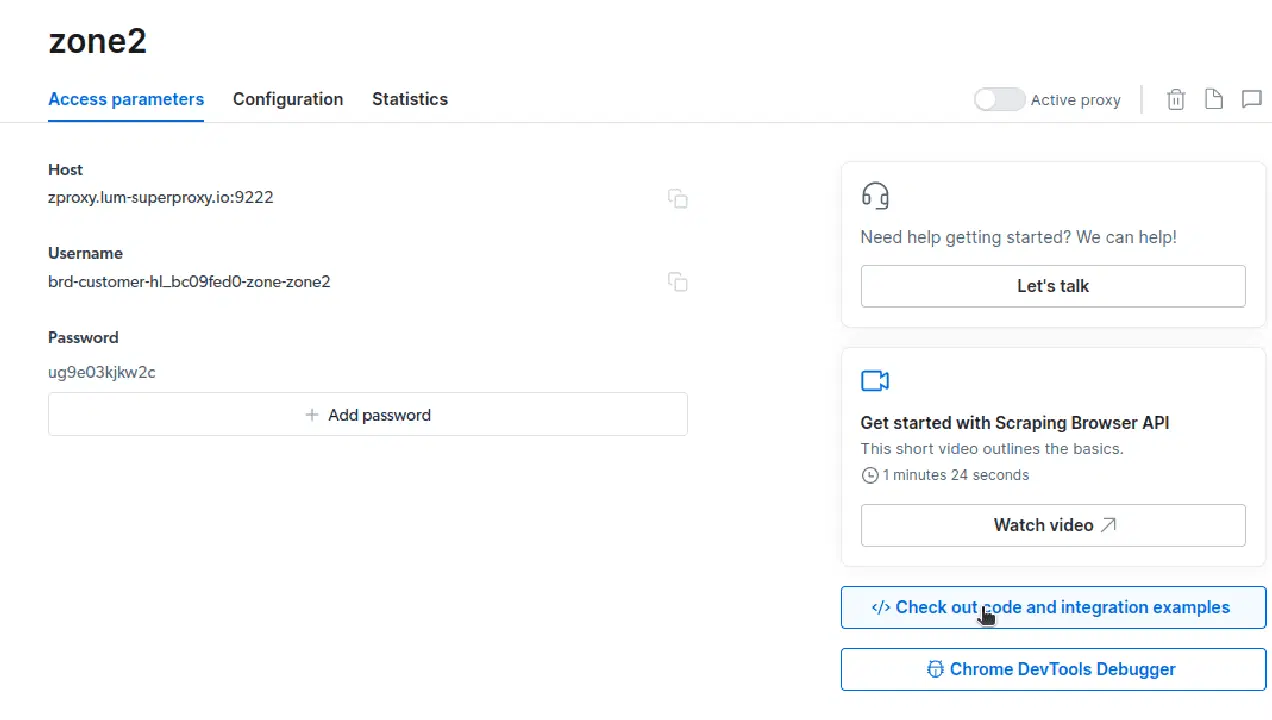
이제 웹사이트에서 데이터를 추출하기 위한 모든 준비가 완료되었습니다. 스크래핑 브라우저의 작동 방식을 설명하기 위해 koreantech.org.com 웹사이트를 사용하겠습니다. 이 예시에서는 node.js를 사용합니다. node.js가 설치되어 있다면 아래 단계를 따라 진행할 수 있습니다.
다음 단계를 따르십시오:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer--zone-:'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
const auth=’USERNAME:PASSWORD’; 부분을 실제 계정 정보로 변경합니다. "액세스 매개변수" 탭에서 사용자 이름, 영역 이름, 비밀번호를 확인하십시오.10번째 줄의 코드를 다음과 같이 변경하겠습니다:
await page.goto('https://koreantech.org.com/authors/');
이제 최종 코드는 다음과 같습니다.
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer--zone-:'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://koreantech.org.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
터미널에 다음과 같은 결과가 표시될 것입니다.
데이터를 내보내는 방법
데이터를 내보내는 방법은 사용 목적에 따라 다양하게 접근할 수 있습니다. 여기서는 콘솔에 출력하는 대신, data.html이라는 새로운 파일을 생성하여 HTML 파일로 데이터를 내보내는 방법을 설명하겠습니다.
다음과 같이 코드 내용을 변경할 수 있습니다.
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer--zone-:'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://koreantech.org.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
이제 다음 명령어를 사용하여 코드를 실행할 수 있습니다.
node script.js
다음 스크린샷에서 볼 수 있듯이, 터미널에 "데이터 내보내기 완료" 메시지가 표시됩니다.
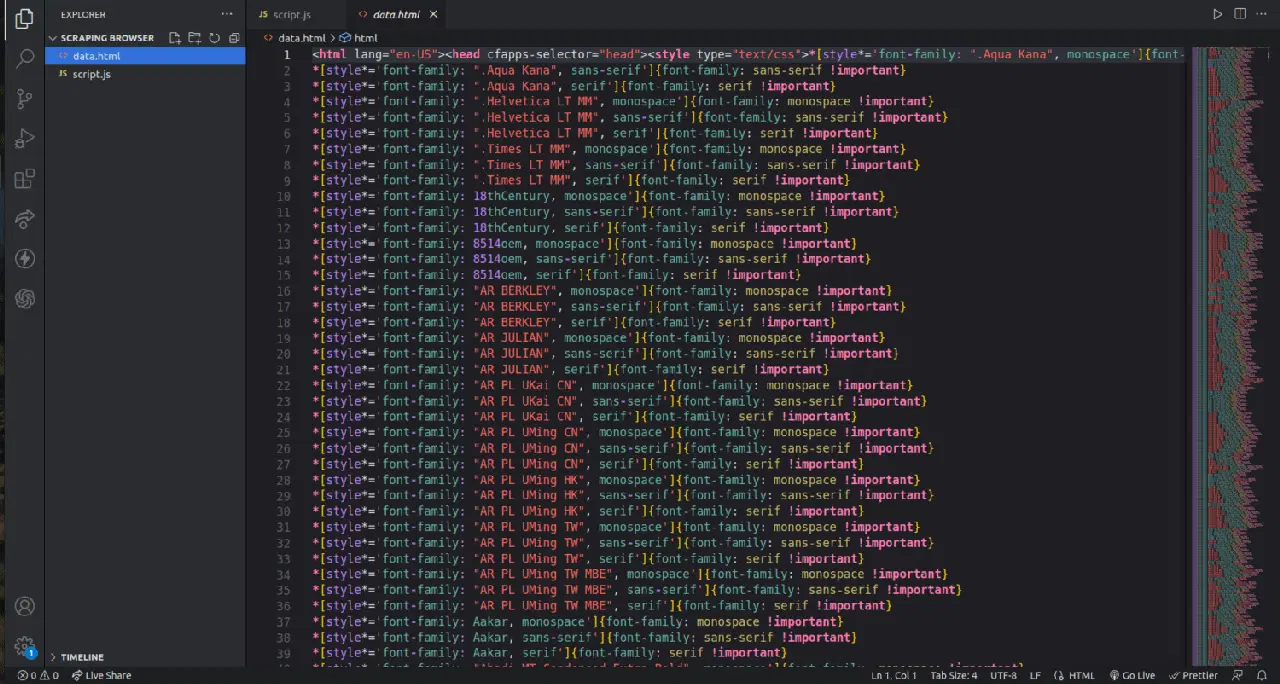
프로젝트 폴더를 확인하면 수천 줄의 코드가 포함된 data.html 파일이 생성된 것을 확인할 수 있습니다.
스크래핑 브라우저를 사용하여 데이터를 추출하는 기본적인 방법을 살펴보았습니다. 이 도구를 사용하여 작성자의 이름과 설명과 같이 특정 데이터만 선택적으로 추출할 수도 있습니다.
스크래핑 브라우저를 효과적으로 사용하려면, 추출하려는 데이터 세트를 명확히 식별하고 그에 맞게 코드를 수정해야 합니다. 대상 웹사이트와 HTML 파일의 구조에 따라 텍스트, 이미지, 비디오, 메타데이터, 링크 등 다양한 정보를 추출할 수 있습니다.
FAQ
데이터 추출 및 웹 스크래핑은 합법적인가요?
웹 스크래핑은 논란의 여지가 있는 주제로, 어떤 사람들은 부도덕하다고 생각하고 다른 사람들은 괜찮다고 생각합니다. 웹 스크래핑의 합법성은 스크랩되는 콘텐츠의 특성과 대상 웹 페이지의 정책에 따라 달라집니다. 일반적으로 주소나 금융 정보와 같은 개인 정보 데이터는 불법적으로 스크랩한 것으로 간주됩니다. 데이터를 스크랩하기 전에 대상 웹사이트에 관련 지침이 있는지 확인하십시오. 항상 공개적으로 사용할 수 없는 데이터를 스크랩하지 않도록 주의해야 합니다.
스크래핑 브라우저는 무료 도구인가요?
아니요, 스크래핑 브라우저는 유료 서비스입니다. 무료 평가판에 등록하면 $5 크레딧을 제공합니다. 유료 패키지는 $15/GB + $0.1/h 부터 시작하며, 종량제 옵션은 $20/GB + $0.1/h 부터 시작합니다.
스크래핑 브라우저와 헤드리스 브라우저의 차이점은 무엇인가요?
스크래핑 브라우저는 그래픽 사용자 인터페이스(GUI)를 가지고 있는 헤드풀 브라우저입니다. 반면, 헤드리스 브라우저에는 그래픽 인터페이스가 없습니다. Selenium과 같은 헤드리스 브라우저는 웹 스크래핑 자동화에 사용되지만, CAPTCHA 및 봇 감지 문제를 직접 처리해야 하므로 때때로 한계가 있습니다.
마무리
스크래핑 브라우저는 웹 페이지에서 데이터 추출 작업을 간소화해 줍니다. Selenium과 같은 기존 도구에 비해 사용하기 쉽고, 개발자가 아닌 사람도 사용자 친화적인 인터페이스와 자세한 설명을 통해 쉽게 사용할 수 있습니다. 또한, 스크래핑 브라우저에는 다른 스크래핑 도구에서는 보기 힘든 차단 해제 기능이 내장되어 있어, 이 프로세스를 자동화하고자 하는 모든 사람에게 효과적인 도구입니다.
또한 ChatGPT 플러그인이 웹사이트 콘텐츠 스크래핑을 중단시키는 방법에 대해서도 알아볼 수 있습니다.