설정 및 실행을 위한 단계별 가이드
실시간 데이터 처리를 위한 Apache Kafka 시작하기
오늘날의 컴퓨팅 환경은 매일 엄청난 양의 데이터를 생성합니다. 금융 거래, 주문, 자동차 센서 데이터 등 다양한 형태의 정보가 쏟아져 나옵니다. 이러한 실시간 데이터 스트림을 효율적으로 처리하고, 다양한 시스템 간에 안정적으로 전송하기 위한 솔루션으로 아파치 카프카(Apache Kafka)가 있습니다.
아파치 카프카는 오픈 소스 데이터 스트리밍 플랫폼으로, 초당 백만 건 이상의 레코드를 처리할 수 있는 강력한 성능을 자랑합니다. 높은 처리량 외에도 확장성, 가용성, 낮은 지연 시간, 영구적인 데이터 저장 기능을 제공합니다.
LinkedIn, Uber, Netflix와 같은 선도적인 기업들이 실시간 데이터 처리 및 스트리밍을 위해 아파치 카프카를 적극적으로 활용하고 있습니다. 아파치 카프카를 처음 접하는 사용자라면 로컬 컴퓨터에서 직접 실행해보는 것이 가장 쉬운 방법입니다. 이를 통해 아파치 카프카 서버의 작동 방식을 이해하고, 메시지를 생성하고 소비하는 과정을 경험할 수 있습니다.
카프카 클라이언트를 사용하여 서버를 시작하고, 토픽을 생성하고, 간단한 Java 코드를 작성하는 실습을 통해 아파치 카프카를 활용하여 데이터 파이프라인 요구 사항을 충족하는 방법을 익힐 수 있습니다.
로컬 환경에 Apache Kafka 다운로드 및 설정
최신 버전의 아파치 카프카는 공식 다운로드 페이지에서 다운로드할 수 있습니다. 다운로드 파일은 .tgz 형식으로 압축되어 제공되며, 다운로드 완료 후 압축을 풀어야 합니다.
Linux 사용자의 경우, 터미널을 열고 다운로드한 압축 파일이 위치한 디렉토리로 이동한 다음 다음 명령을 실행합니다:
tar -xzvf kafka_2.13-3.5.0.tgz
명령 실행이 완료되면 `kafka_2.13-3.5.0` 디렉토리가 생성됩니다. 해당 디렉토리로 이동하여 내부를 살펴봅니다:
cd kafka_2.13-3.5.0
`ls` 명령을 사용하여 디렉토리 내용을 확인할 수 있습니다.
Windows 사용자는 동일한 단계를 따를 수 있습니다. `tar` 명령을 사용할 수 없는 경우, WinZip과 같은 타사 압축 해제 도구를 사용할 수 있습니다.
로컬 환경에서 Apache Kafka 실행하기
아파치 카프카 다운로드 및 압축 해제 후, 실행을 시작할 차례입니다. 별도의 설치 과정은 필요하지 않으며, 명령줄 또는 터미널 창을 통해 직접 실행할 수 있습니다.
아파치 카프카 실행 전에 시스템에 Java 8 이상 버전이 설치되어 있는지 확인해야 합니다. 아파치 카프카는 Java 환경에서 실행되기 때문입니다.
1. Apache Zookeeper 서버 실행
가장 먼저 아파치 주키퍼(Apache Zookeeper) 서버를 실행해야 합니다. 주키퍼는 카프카 아카이브에 함께 포함되어 있으며, 구성 관리 및 서비스 간 동기화를 제공하는 역할을 합니다.
압축 해제된 디렉토리 내에서 다음 명령을 실행합니다:
Linux 사용자:
bin/zookeeper-server-start.sh config/zookeeper.properties
Windows 사용자:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
`zookeeper.properties` 파일은 주키퍼 서버 실행을 위한 설정을 담고 있습니다. 데이터 저장 위치, 실행 포트와 같은 속성을 구성할 수 있습니다.
2. Apache Kafka 서버 시작
주키퍼 서버 실행이 완료되었다면, 이제 아파치 카프카 서버를 시작할 차례입니다.
새 터미널 또는 명령 프롬프트 창을 열고, 압축 해제된 디렉토리로 이동한 후 다음 명령을 실행합니다:
Linux 사용자:
bin/kafka-server-start.sh config/server.properties
Windows 사용자:
bin/windows/kafka-server-start.bat config/server.properties
카프카 서버가 실행 중입니다. 기본 설정을 변경하려면 `server.properties` 파일을 수정하면 됩니다. 사용 가능한 설정 값은 공식 문서에서 확인할 수 있습니다.
로컬 환경에서 Apache Kafka 활용하기
이제 로컬 시스템에서 아파치 카프카를 사용하여 메시지를 생성하고 소비할 준비가 되었습니다. 주키퍼 및 카프카 서버가 모두 실행 중이므로, 첫 번째 토픽을 생성하고, 메시지를 생성 및 소비하는 방법을 알아보겠습니다.
Apache Kafka 토픽 생성 방법
토픽을 생성하기 전에, 토픽의 개념을 이해해야 합니다. 아파치 카프카에서 토픽은 데이터 스트림을 위한 논리적인 저장소입니다. 데이터를 한 컴포넌트에서 다른 컴포넌트로 전달하는 채널이라고 생각하면 됩니다.
토픽은 여러 생산자 및 여러 소비자를 지원합니다. 여러 시스템이 동일한 토픽에서 데이터를 쓰고 읽을 수 있습니다. 다른 메시징 시스템과 달리, 토픽의 메시지는 여러 번 사용할 수 있으며, 메시지 보관 기간을 설정할 수도 있습니다.
예를 들어, 은행 거래 데이터를 생성하는 시스템(생산자)과 해당 데이터를 소비하여 사용자에게 앱 알림을 보내는 시스템(소비자)이 있다고 가정해 봅시다. 이러한 시스템 간 데이터 교환을 위해서는 토픽이 필수적입니다.
새 터미널 또는 명령 프롬프트 창을 열고, 압축 해제된 디렉토리로 이동한 후, 다음 명령을 실행하여 `transactions`라는 토픽을 생성합니다:
Linux 사용자:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
Windows 사용자:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
이제 첫 번째 토픽이 생성되었으며, 메시지 생성 및 소비를 시작할 준비가 완료되었습니다.
Apache Kafka 메시지 생성 방법
아파치 카프카 토픽이 준비되었으므로, 이제 첫 번째 메시지를 생성할 수 있습니다. 새 터미널 또는 명령 프롬프트 창을 열거나, 토픽을 생성하는 데 사용한 창을 그대로 사용할 수 있습니다. 압축 해제된 디렉토리로 이동한 후, 다음 명령을 실행하여 토픽에 메시지를 생성합니다:
Linux 사용자:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
Windows 사용자:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
명령을 실행하면 터미널 또는 명령 프롬프트 창이 입력을 대기합니다. 첫 번째 메시지를 입력하고 Enter 키를 누릅니다:
> This is a transactional record for $100

로컬 환경에서 아파치 카프카에 첫 번째 메시지를 성공적으로 생성했습니다. 이제 이 메시지를 소비할 준비가 되었습니다.
Apache Kafka 메시지 소비 방법
토픽을 생성하고 메시지를 생성했다면, 이제 메시지를 소비할 수 있습니다.
아파치 카프카를 사용하면 여러 소비자를 동일한 토픽에 연결할 수 있습니다. 각 소비자는 논리적 식별자인 소비자 그룹에 속할 수 있습니다. 예를 들어, 동일한 데이터를 처리해야 하는 두 개의 서비스가 있다면, 각각 다른 소비자 그룹에 속하도록 할 수 있습니다.
그러나 동일한 서비스의 여러 인스턴스가 있는 경우, 동일한 메시지를 두 번 이상 소비하고 처리하는 것을 피해야 합니다. 이러한 경우에는 모든 인스턴스가 동일한 소비자 그룹에 속하도록 구성합니다.
터미널 또는 명령 프롬프트 창에서 올바른 디렉토리에 있는지 확인하고, 다음 명령을 실행하여 소비자를 시작합니다:
Linux 사용자:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
Windows 사용자:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
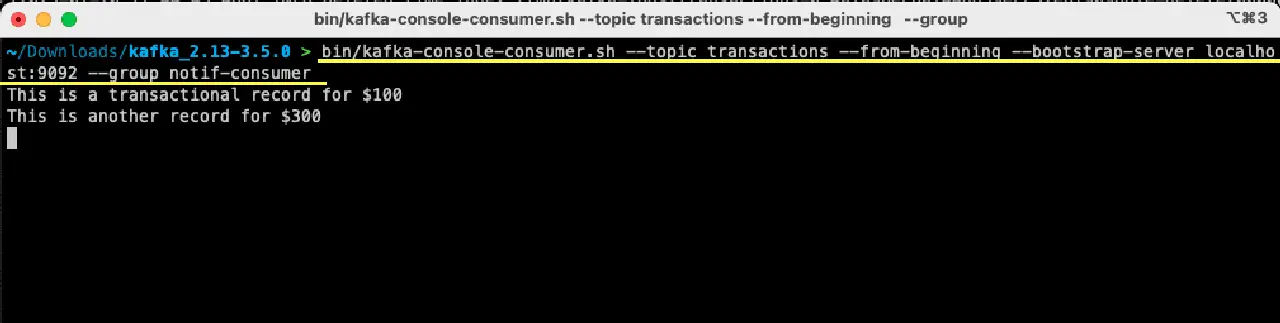
터미널에 이전에 생성한 메시지가 표시되는 것을 확인할 수 있습니다. 이제 아파치 카프카를 사용하여 첫 번째 메시지를 소비했습니다.
`kafka-console-consumer` 명령은 다양한 인수를 사용합니다. 각 인수의 의미를 살펴보겠습니다:
- `--topic`: 소비할 토픽을 지정합니다.
- `--from-beginning`: 콘솔 소비자에게 첫 번째 메시지부터 읽기를 시작하도록 지시합니다.
- `--bootstrap-server`: 아파치 카프카 서버의 주소를 지정합니다.
- `--group`: 소비자 그룹을 지정합니다. 소비자 그룹을 지정하지 않으면 자동으로 생성됩니다.
콘솔 소비자가 실행 중인 동안, 새 메시지를 생성하면 소비되어 터미널에 표시되는 것을 확인할 수 있습니다.
이제 토픽을 생성하고 메시지를 생성 및 소비하는 데 성공했으므로, Java 애플리케이션과 통합해 보겠습니다.
Java를 사용하여 Apache Kafka 생산자 및 소비자 만들기
시작하기 전에, 로컬 시스템에 Java 8 이상이 설치되어 있는지 확인하십시오. 아파치 카프카는 자체 클라이언트 라이브러리를 제공하여 원활하게 연결할 수 있도록 지원합니다. Maven을 사용하여 종속성을 관리하는 경우, `pom.xml` 파일에 다음 종속성을 추가합니다:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
또는 Maven 저장소에서 라이브러리를 다운로드하여 Java 클래스 경로에 추가할 수도 있습니다.
라이브러리가 준비되면, 코드 편집기를 열고 Java를 사용하여 생산자와 소비자를 구현하는 방법을 알아보겠습니다.
Apache Kafka Java 생산자 만들기
카프카 클라이언트 라이브러리가 준비되었으므로, 이제 카프카 생산자를 만들 준비가 되었습니다.
`SimpleProducer.java`라는 클래스를 만들고, 해당 클래스에서 이전에 생성한 토픽에 메시지를 생성하는 역할을 담당하도록 구현합니다. `org.apache.kafka.clients.producer.KafkaProducer` 인스턴스를 생성하고, 생성된 생산자를 사용하여 메시지를 전송합니다.
카프카 생산자를 생성하려면, 아파치 카프카 서버의 호스트 및 포트 정보가 필요합니다. 로컬 컴퓨터에서 실행 중이므로, 호스트는 `localhost`이고, 서버 시작 시 기본 속성을 변경하지 않았다면 포트는 `9092`가 됩니다. 생산자를 생성하는 데 도움이 되는 다음 코드를 참고하십시오:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
위 코드에서 세 가지 속성이 설정되어 있음을 확인할 수 있습니다. 각 속성을 간단히 살펴보겠습니다:
- `BOOTSTRAP_SERVERS_CONFIG`: 아파치 카프카 서버가 실행되는 위치를 정의합니다.
- `KEY_SERIALIZER_CLASS_CONFIG`: 생산자에게 메시지 키를 보낼 때 사용할 형식을 알려줍니다.
- `VALUE_SERIALIZER_CLASS_CONFIG`: 실제 메시지를 전송할 때 사용할 형식을 정의합니다.
문자 메시지를 전송할 것이므로, 두 속성 모두 `StringSerializer.class`를 사용하도록 설정합니다.
실제로 토픽에 메시지를 전송하려면, `ProducerRecord`를 인자로 받는 `producer.send()` 메서드를 사용해야 합니다. 다음 코드는 토픽에 메시지를 전송하고, 메시지 오프셋과 함께 응답을 출력하는 메서드를 제공합니다:
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
전체 코드가 준비되면, 이제 토픽에 메시지를 전송할 수 있습니다. 다음 코드와 같이 `main` 메서드를 사용하여 테스트할 수 있습니다:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
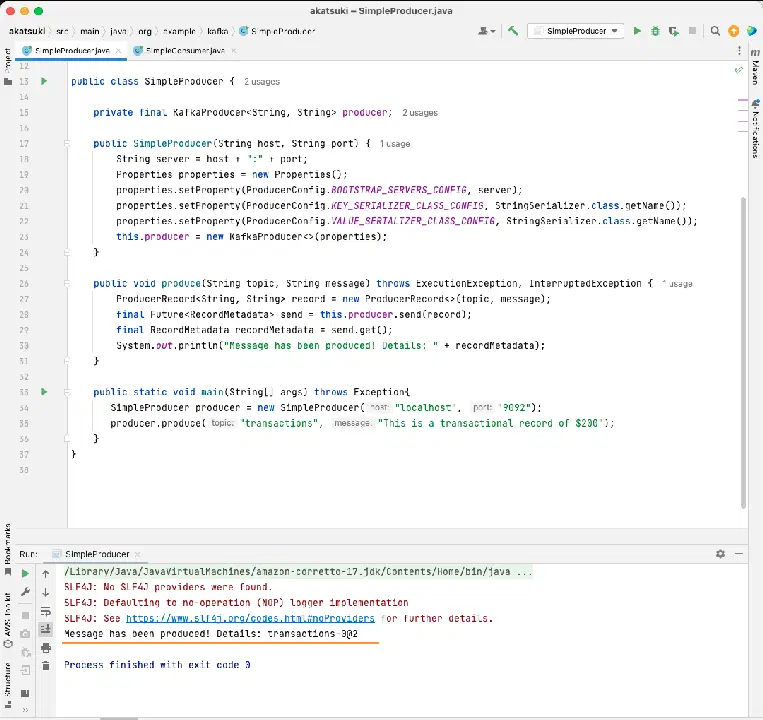
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
이 코드는 로컬 시스템의 아파치 카프카 서버에 연결하는 `SimpleProducer`를 생성합니다. 내부적으로 `KafkaProducer`를 사용하여 토픽에 텍스트 메시지를 생성합니다.
Apache Kafka Java 소비자 만들기
이제 Java 클라이언트를 사용하여 아파치 카프카 소비자를 만들 차례입니다. `SimpleConsumer.java`라는 클래스를 만들고, `org.apache.kafka.clients.consumer.KafkaConsumer`를 초기화하는 생성자를 구현합니다. 소비자를 생성하려면 아파치 카프카 서버의 호스트, 포트, 소비자 그룹, 그리고 소비할 토픽이 필요합니다. 다음 코드 스니펫을 사용하십시오:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
카프카 생산자와 마찬가지로 카프카 소비자도 `Properties` 객체를 인자로 받습니다. 각각의 속성을 살펴보겠습니다:
- `BOOTSTRAP_SERVERS_CONFIG`: 소비자에게 아파치 카프카 서버의 위치를 알려줍니다.
- `GROUP_ID_CONFIG`: 소비자 그룹을 지정합니다.
- `AUTO_OFFSET_RESET_CONFIG`: 소비자가 처음으로 소비를 시작할 때 메시지 오프셋을 어디서부터 시작할지를 지정합니다.
- `KEY_DESERIALIZER_CLASS_CONFIG`: 소비자에게 메시지 키의 유형을 알려줍니다.
- `VALUE_DESERIALIZER_CLASS_CONFIG`: 실제 메시지의 데이터 유형을 알려줍니다.
문자 메시지를 사용하므로, deserializer 속성을 `StringDeserializer.class`로 설정합니다.
이제 토픽의 메시지를 소비할 수 있습니다. 단순하게 유지하기 위해 메시지가 소비되면 콘솔에 출력하도록 하겠습니다. 다음 코드를 사용하여 이를 구현하는 방법을 살펴보겠습니다:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
이 코드는 토픽을 계속해서 폴링합니다. 소비자 레코드를 수신하면 메시지를 출력합니다. `main` 메서드를 사용하여 실제 소비자를 테스트합니다. Java 애플리케이션을 실행하여 메시지 소비를 시작하고, 소비자를 종료하려면 애플리케이션을 중지하면 됩니다.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
코드를 실행하면 Java 생산자가 생성한 메시지뿐만 아니라, 콘솔 생산자를 통해 생성한 메시지도 소비하는 것을 확인할 수 있습니다. `AUTO_OFFSET_RESET_CONFIG` 속성이 `earliest`로 설정되었기 때문입니다.
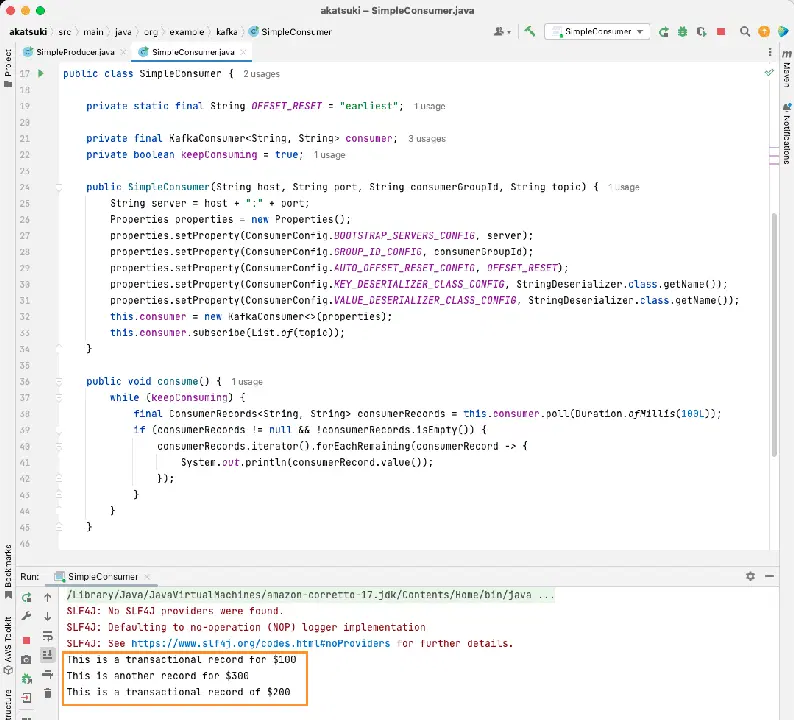
`SimpleConsumer`가 실행 중인 동안, 콘솔 생산자 또는 `SimpleProducer` Java 애플리케이션을 사용하여 토픽에 추가 메시지를 생성하면 콘솔에서 소비되고 출력되는 것을 확인할 수 있습니다.
Apache Kafka로 모든 데이터 파이프라인 요구 사항 충족하기
아파치 카프카를 사용하면 데이터 파이프라인 요구 사항을 손쉽게 처리할 수 있습니다. 로컬 환경에서 아파치 카프카를 설정하면 카프카가 제공하는 다양한 기능을 탐색하고, 공식 Java 클라이언트를 사용하여 아파치 카프카 서버와 효율적으로 데이터를 주고받을 수 있습니다.
다양한 기능을 제공하고 확장성이 뛰어나며 고성능 데이터 스트리밍 플랫폼인 아파치 카프카는 혁신적인 솔루션이 될 수 있습니다. 로컬 개발 환경에 사용하거나 프로덕션 시스템에 통합할 수도 있습니다. 로컬 환경에서 설정하는 것만큼 큰 애플리케이션에 대해 아파치 카프카를 설정하는 것도 어려운 작업은 아닙니다.
실시간 데이터 스트리밍 플랫폼을 찾고 있다면, 실시간 분석 및 처리를 위한 최고의 데이터 스트리밍 플랫폼을 살펴보시기를 권장합니다.