

Tesseract OCR 엔진을 사용하여 Linux 명령줄의 이미지에서 텍스트를 추출할 수 있습니다. 빠르고 정확하며 약 100개 언어로 작동합니다. 사용 방법은 다음과 같습니다.
목차
광학 문자 인식
광학 문자 인식 (OCR)은 이미지에서 단어를 보고 찾은 다음 편집 가능한 텍스트로 추출하는 기능입니다. 인간이 하는 이 간단한 작업은 컴퓨터가 하기에는 매우 어렵습니다. 초기의 노력은 말할 것도 없이 투박했습니다. 글꼴이나 크기가 OCR 소프트웨어의 취향에 맞지 않으면 컴퓨터는 종종 혼동을 일으켰습니다.
그럼에도 불구하고 이 분야의 개척자들은 여전히 높은 평가를 받았습니다. 문서의 전자 사본을 분실했지만 여전히 인쇄된 버전이 있는 경우 OCR은 편집 가능한 전자 버전을 다시 만들 수 있습니다. 결과가 100% 정확하지 않더라도 시간을 크게 절약할 수 있습니다.
수동으로 정리하면 문서를 되찾을 수 있습니다. 사람들은 OCR 패키지가 직면한 작업의 복잡성을 이해했기 때문에 실수를 용서했습니다. 또한 전체 문서를 다시 입력하는 것보다 낫습니다.
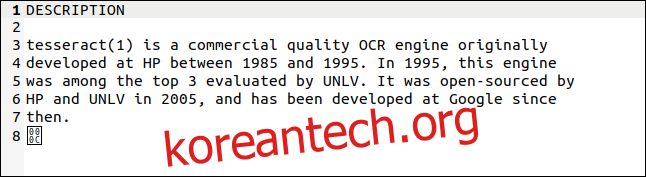
그 이후로 상황이 크게 개선되었습니다. Tesseract OCR 애플리케이션, 휴렛 패커드의, 상용 응용 프로그램으로 1980년대에 시작되었습니다. 2005년에 오픈 소스로 제공되었으며 현재 다음에서 지원합니다. Google. 다국어 기능이 있고 가장 정확한 OCR 시스템 중 하나로 간주되며 무료로 사용할 수 있습니다.
Tesseract OCR 설치
Ubuntu에 Tesseract OCR을 설치하려면 다음 명령을 사용하십시오.
sudo apt-get install tesseract-ocr

Fedora에서 명령은 다음과 같습니다.
sudo dnf install tesseract

Manjaro에서는 다음을 입력해야 합니다.
sudo pacman -Syu tesseract

Tesseract OCR 사용
우리는 Tesseract OCR에 일련의 도전 과제를 제기할 것입니다. 텍스트가 포함된 첫 번째 이미지는 Recital 63에서 발췌한 것입니다. 일반 데이터 보호 규정. OCR이 이것을 읽을 수 있는지(그리고 깨어 있는지) 봅시다.

각 문장이 입법 문서에서 흔히 볼 수 있는 희미한 위첨자 숫자로 시작하기 때문에 까다로운 이미지입니다.
tesseract 명령에 다음을 포함한 몇 가지 정보를 제공해야 합니다.
처리할 이미지 파일의 이름입니다.
추출된 텍스트를 보관하기 위해 생성할 텍스트 파일의 이름입니다. 파일 확장자를 제공할 필요가 없습니다(항상 .txt임). 같은 이름의 파일이 이미 있으면 덮어씁니다.
–dpi 옵션을 사용하여 tesseract에게 인치당 도트 수 (dpi) 이미지의 해상도입니다. dpi 값을 제공하지 않으면 tesseract가 이를 알아내려고 시도합니다.
이미지 파일의 이름은 “recital-63.png”이고 해상도는 150dpi입니다. “recital.txt”라는 텍스트 파일을 만들 것입니다.
우리의 명령은 다음과 같습니다.
tesseract recital-63.png recital --dpi 150

결과는 매우 좋습니다. 유일한 문제는 위 첨자가 너무 희미해서 제대로 읽을 수 없다는 것입니다. 좋은 결과를 얻으려면 좋은 품질의 이미지가 중요합니다.

tesseract는 위 첨자 숫자를 인용 부호(“)와 도 기호(°)로 해석했지만 실제 텍스트는 완벽하게 추출되었습니다(여기에 맞게 이미지의 오른쪽을 잘라야 했습니다).
마지막 문자는 캐리지 리턴인 0x0C의 16진수 값을 가진 바이트입니다.
아래는 다양한 크기의 텍스트와 굵게 및 기울임꼴이 있는 또 다른 이미지입니다.

이 파일의 이름은 “bold-italic.png”입니다. “bold.txt”라는 텍스트 파일을 만들고자 하므로 명령은 다음과 같습니다.
tesseract bold-italic.png bold --dpi 150

이것은 문제를 일으키지 않았고 텍스트는 완벽하게 추출되었습니다.
다른 언어 사용
Tesseract OCR 지원 약 100개 언어. 언어를 사용하려면 먼저 언어를 설치해야 합니다. 목록에서 사용하려는 언어를 찾으면 해당 언어의 약어를 기록해 두십시오. 웨일스어에 대한 지원을 설치할 것입니다. 약어는 “Cym”으로 웨일스어를 의미하는 “Cymru”의 줄임말입니다.
설치 패키지의 이름은 “tesseract-ocr-“이고 끝에 태그가 붙은 언어 약어가 있습니다. Ubuntu에 웨일스어 언어 파일을 설치하려면 다음을 사용합니다.
sudo apt-get install tesseract-ocr-cym

텍스트가 있는 이미지는 아래에 있습니다. 웨일즈 국가의 첫 구절입니다.

Tesseract OCR이 문제를 해결하는지 봅시다. -l(언어) 옵션을 사용하여 tesseract에 작업하려는 언어를 알립니다.
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150

tesseract는 아래 추출된 텍스트와 같이 완벽하게 대처합니다. Da iawn, Tesseract OCR.

문서에 두 개 이상의 언어가 포함되어 있는 경우(예: 웨일스어-영어 사전) 더하기 기호(+)를 사용하여 다음과 같이 tesseract에 다른 언어를 추가하도록 지시할 수 있습니다.
tesseract image.png textfile -l eng+cym+fra
PDF와 함께 Tesseract OCR 사용
tesseract 명령은 이미지 파일과 함께 작동하도록 설계되었지만 PDF를 읽을 수는 없습니다. 그러나 PDF에서 텍스트를 추출해야 하는 경우 먼저 다른 유틸리티를 사용하여 이미지 세트를 생성할 수 있습니다. 단일 이미지는 PDF의 단일 페이지를 나타냅니다.
필요한 pdftppm 유틸리티 이미 설치되어 있어야 합니다 당신의 리눅스 컴퓨터에서. 우리가 예제에 사용할 PDF는 인공 지능에 관한 Alan Turing의 획기적인 논문인 “Computing Machinery and Intelligence”의 사본입니다.

-png 옵션을 사용하여 PNG 파일을 생성하도록 지정합니다. PDF 파일 이름은 “turing.pdf”입니다. 이미지 파일을 “turing-01.png”, “turing-02.png” 등으로 부를 것입니다.
pdftoppm -png turing.pdf turing

단일 명령을 사용하여 각 이미지 파일에서 tesseract를 실행하려면 다음을 사용해야 합니다. for 루프. 각각의 “turing-nn.png” 파일에 대해 tesseract를 실행하고 이미지 파일 이름의 일부로 “text-“와 “turing-nn”이라는 텍스트 파일을 만듭니다.
for i in turing-??.png; do tesseract "$i" "text-$i" -l eng; done;

모든 텍스트 파일을 하나로 결합하려면 cat을 사용할 수 있습니다.
cat text-turing* > complete.txt

세로 워터마크는 페이지 하단에 횡설수설한 줄로 전사되었습니다. 텍스트가 너무 작아서 tesseract가 정확하게 읽을 수 없었지만 충분히 찾아서 삭제할 수 있었습니다. 최악의 결과는 각 줄 끝에 문자가 누락되었을 것입니다.
흥미롭게도 2페이지의 질문과 답변 목록 시작 부분에 있는 단일 문자는 무시되었습니다. PDF의 섹션이 아래에 나와 있습니다.

아래에서 볼 수 있듯이 질문은 남아 있지만 각 줄의 시작 부분에 있는 “Q”와 “A”는 손실되었습니다.

다이어그램도 올바르게 전사되지 않습니다. Turing PDF에서 아래에 표시된 것을 추출하려고 할 때 어떤 일이 발생하는지 살펴보겠습니다.

아래 결과에서 볼 수 있듯이 문자는 읽었지만 다이어그램의 형식이 손실되었습니다.

다시 말하지만, tesseract는 아래 첨자의 작은 크기로 인해 어려움을 겪었고 잘못 렌더링되었습니다.
그러나 공정하게 말하면 여전히 좋은 결과였습니다. 우리는 직접적인 텍스트를 추출할 수 없었지만, 이 예제는 도전을 제시했기 때문에 의도적으로 선택되었습니다.
당신이 그것을 필요로 할 때 좋은 솔루션
OCR은 매일 사용해야 하는 것이 아닙니다. 그러나 필요할 때 최고의 OCR 엔진 중 하나를 사용할 수 있다는 사실을 아는 것이 좋습니다.