Meta에서 개발한 오픈 소스 대형 언어 모델(LLM)인 Llama 2는 GPT-3.5 및 PaLM 2와 같은 일부 독점 모델을 능가하는 뛰어난 성능을 자랑합니다. 이 모델은 70억, 130억, 700억 개의 매개변수를 가진 다양한 크기로 제공됩니다.
Streamlit과 Llama 2를 함께 사용하여 챗봇을 구축하며 Llama 2의 대화 능력을 직접 체험해 보겠습니다.
Llama 2의 특징과 장점
Llama 2는 이전 버전인 Llama 1과 비교하여 어떤 차이점을 가지고 있을까요?
- 확장된 모델 크기: Llama 2는 최대 700억 개의 매개변수를 보유하고 있어, 단어와 문장 간의 복잡한 관계를 더 잘 학습할 수 있습니다.
- 향상된 대화 능력: 인간 피드백을 통한 강화 학습(RLHF)을 통해 대화형 응용 프로그램에서의 활용도가 크게 증가했습니다. 이를 통해 복잡한 대화 시나리오에서도 인간과 유사한 콘텐츠 생성이 가능해졌습니다.
- 더욱 빨라진 추론 속도: 그룹화된 쿼리 어텐션이라는 새로운 기법을 도입하여 추론 속도를 향상시켰습니다. 이로써 챗봇이나 가상 비서와 같이 실용적인 애플리케이션을 구축하는 데 더욱 적합하게 되었습니다.
- 뛰어난 효율성: 이전 모델 대비 메모리 및 계산 리소스 효율성이 향상되었습니다.
- 오픈 소스 및 비상업적 라이선스: 오픈 소스 모델로, 연구자와 개발자는 제약 없이 Llama 2를 활용하고 수정할 수 있습니다.
Llama 2는 모든 면에서 이전 버전을 뛰어넘는 성능을 제공하며, 챗봇, 가상 비서, 자연어 이해 등 다양한 분야에서 강력한 도구로 활용될 수 있습니다.
챗봇 개발을 위한 간편한 환경 설정
애플리케이션 개발을 시작하기 전에 먼저 개발 환경을 설정해야 합니다. 이를 통해 기존 프로젝트로부터 현재 프로젝트를 격리시킬 수 있습니다.
먼저, Pipenv 라이브러리를 사용하여 가상 환경을 생성합니다.
pipenv shell
다음으로 챗봇 개발에 필요한 라이브러리를 설치합니다.
pipenv install streamlit replicate
Streamlit은 기계 학습 및 데이터 과학 애플리케이션을 빠르게 웹 앱 형태로 렌더링할 수 있는 오픈 소스 프레임워크입니다.
Replicate는 클라우드 기반 플랫폼으로, 다양한 오픈 소스 기계 학습 모델에 접근하여 배포할 수 있도록 지원합니다.
Replicate에서 Llama 2 API 토큰 얻기
Replicate API 토큰을 얻으려면 먼저 계정을 등록해야 합니다. Replicate 웹사이트에서 GitHub 계정을 사용하여 가입할 수 있습니다.
대시보드에 접속한 후 탐색 메뉴에서 ‘Llama 2 chat’을 검색하여 llama-2-70b-chat 모델을 찾습니다.
Llama 2 API 엔드포인트를 확인하려면 llama-2-70b-chat 모델을 클릭하십시오. 모델 페이지의 상단 메뉴에서 ‘API’ 버튼을 클릭한 후, 오른쪽에 나타나는 Python 버튼을 클릭합니다. 그러면 Python 애플리케이션에서 사용할 수 있는 API 토큰에 대한 정보가 제공됩니다.
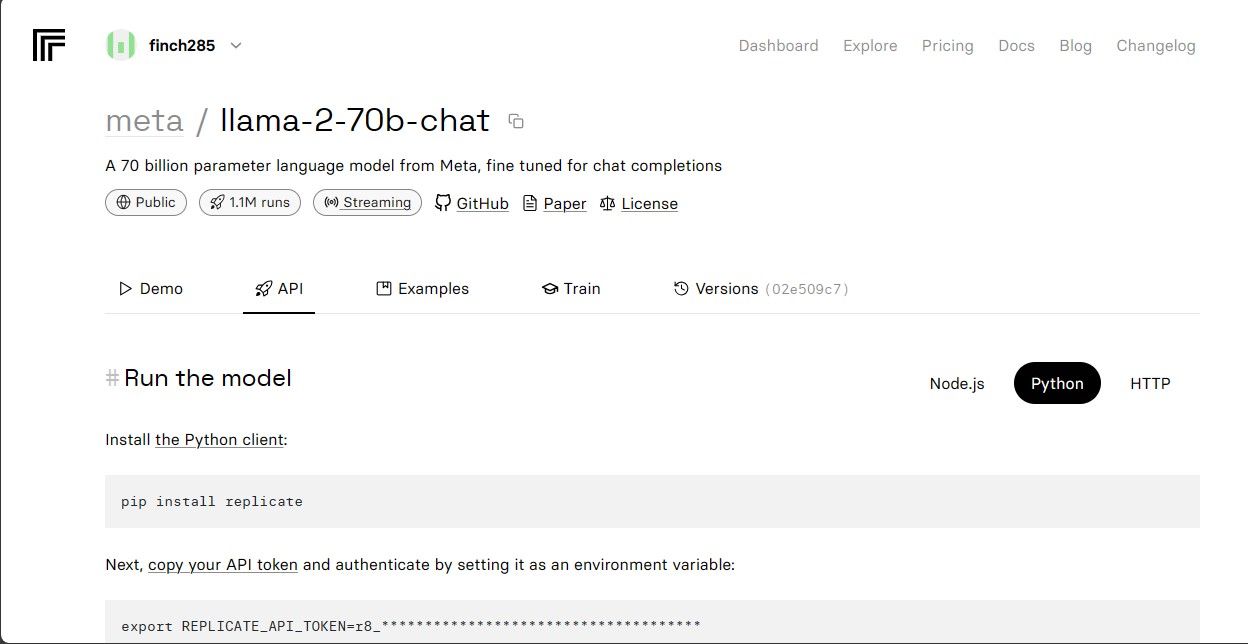
생성된 REPLICATE_API_TOKEN을 복사하여 안전하게 보관하십시오.
챗봇 구축
먼저, llama_chatbot.py라는 이름의 Python 파일과 .env 파일을 만듭니다. llama_chatbot.py 파일에 코드를 작성하고, API 토큰과 같은 민감한 정보는 .env 파일에 저장합니다.
llama_chatbot.py 파일에서 필요한 라이브러리를 임포트합니다.
import streamlit as st
import os
import replicate
다음으로 Llama-2-70b-chat 모델의 전역 변수를 설정합니다.
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
.env 파일에 Replicate 토큰과 모델 엔드포인트를 아래 형식으로 추가합니다.
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Replicate 토큰을 붙여넣고 .env 파일을 저장합니다.
챗봇의 대화 흐름 설계
챗봇의 목적에 따라 Llama 2 모델 시작을 위한 사전 프롬프트를 정의합니다. 이 예시에서는 챗봇이 사용자의 질문에 답변하는 도우미 역할을 수행하도록 설정합니다.
PRE_PROMPT = "당신은 유용한 도우미입니다. '사용자'로 응답하거나 '사용자'인 척하지 않습니다." \
"보조자로서 한 번만 응답합니다."
다음으로 챗봇 페이지의 구성을 설정합니다.
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
세션 상태 변수를 초기화하고 설정하는 함수를 작성합니다.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'LLaMA2 모델 선택:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
이 함수는 세션 상태에서 chat_dialogue, pre_prompt, llm, top_p, max_seq_len, temperature와 같은 주요 변수들을 설정합니다. 또한, 사용자의 선택에 따라 Llama 2 모델을 선택할 수 있도록 합니다.
Streamlit 앱의 사이드바 영역을 구성하는 함수를 작성합니다.
def render_sidebar():
st.sidebar.header("LLaMA2 챗봇")
st.session_state['temperature'] = st.sidebar.slider('온도:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('최대 시퀀스 길이:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'채팅 시작 전 프롬프트. 필요시 수정하세요:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
이 함수는 Llama 2 챗봇의 제목과 설정을 표시하여 사용자가 모델 설정을 조정할 수 있도록 합니다.
Streamlit 앱의 메인 영역에 채팅 내역을 렌더링하는 함수를 작성합니다.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
이 함수는 세션 상태에 저장된 chat_dialogue를 순회하며, 각 메시지의 역할(사용자 또는 보조자)과 함께 내용을 표시합니다.
다음 함수를 사용하여 사용자의 입력을 처리합니다.
def handle_user_input():
user_input = st.chat_input(
"LLaMA2에게 질문을 입력하세요."
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
이 함수는 사용자에게 메시지를 입력할 수 있는 입력 필드를 제공합니다. 사용자가 메시지를 제출하면, 해당 메시지가 ‘user’ 역할을 갖는 세션 상태의 chat_dialogue에 추가됩니다.
Llama 2 모델로부터 응답을 생성하고 이를 채팅 영역에 표시하는 함수를 작성합니다.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
이 함수는 보조자의 응답을 생성하기 위해 debounce_replicate_run 함수를 호출하기 전에 사용자와 보조자의 메시지를 모두 포함한 대화 기록 문자열을 만듭니다. 사용자 인터페이스에서 응답을 실시간으로 업데이트하여 실시간 채팅 경험을 제공합니다.
전체 Streamlit 앱 렌더링을 담당하는 주요 함수를 작성합니다.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
정의된 모든 함수들을 호출하여 세션 상태를 설정하고, 사이드바를 렌더링하고, 채팅 기록을 표시하고, 사용자 입력을 처리하고, 보조자 응답을 논리적 순서로 생성합니다.
render_app 함수를 호출하고 스크립트가 실행될 때 애플리케이션을 시작하는 함수를 작성합니다.
def main():
render_app()if __name__ == "__main__":
main()
이제 애플리케이션을 실행할 준비가 되었습니다.
API 요청 처리
프로젝트 디렉터리에 utils.py 파일을 만들고 아래 함수를 추가합니다.
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "안녕하세요! 요청 속도가 너무 빠릅니다. 다음 요청을 보내기 전에 몇 초 정도 기다려주세요."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
이 함수는 사용자 입력으로 인해 빈번하고 과도한 API 쿼리가 발생하지 않도록 디바운스 메커니즘을 구현합니다.
다음과 같이 디바운스 응답 함수를 llama_chatbot.py 파일로 가져옵니다.
from utils import debounce_replicate_run
이제 애플리케이션을 실행합니다.
streamlit run llama_chatbot.py
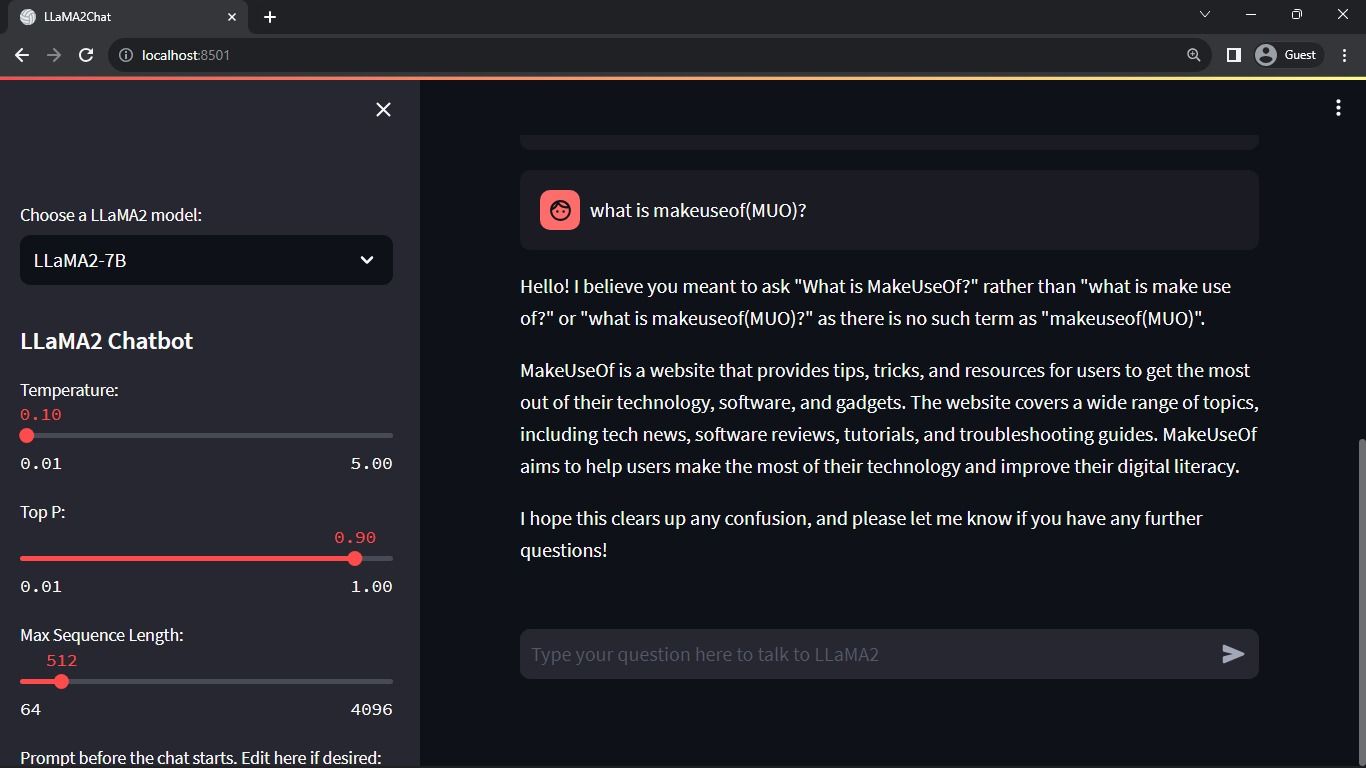
예상 출력:
출력은 모델과 인간 간의 대화를 보여줍니다.
Streamlit 및 Llama 2 챗봇의 실제 응용 사례
Llama 2 애플리케이션의 실제 사용 사례는 다음과 같습니다.
- 챗봇: 다양한 주제에 대해 인간과 유사한 실시간 대화를 할 수 있는 챗봇 개발에 사용됩니다.
- 가상 비서: 자연어 쿼리를 이해하고 이에 응답하는 가상 비서를 만드는 데 활용됩니다.
- 언어 번역: 다국어 간의 텍스트 번역 작업에 사용될 수 있습니다.
- 텍스트 요약: 긴 텍스트를 짧고 이해하기 쉬운 형태로 요약하는 데 사용됩니다.
- 연구: 다양한 주제에 대한 질문에 답변함으로써 연구 목적으로 Llama 2를 사용할 수 있습니다.
AI의 미래
GPT-3.5 및 GPT-4와 같은 독점 모델을 사용하면 GPT 모델 API에 접근하는 데 상당한 비용이 발생하므로, 소규모 개발자들이 LLM을 활용하여 실질적인 결과물을 만들기가 매우 어렵습니다.
Llama 2와 같이 진보된 대형 언어 모델을 개발자 커뮤니티에 공개하는 것은 AI의 새로운 시대를 여는 시작에 불과합니다. 이는 실질적인 응용 프로그램에서 더욱 창의적이고 혁신적인 모델 구현을 장려하여 인공 초지능(ASI) 달성을 향한 경쟁을 가속화할 것입니다.