R에서 탐색적 데이터 분석(EDA)을 수행하는 방법(예제 포함)
데이터 분석의 핵심 과정인 탐색적 데이터 분석(EDA)에 대해 알아봅시다. EDA는 통계 요약 및 시각적 표현을 통해 데이터 세트의 추세와 패턴을 파악하고 요약하는 데 필수적입니다.
데이터 과학 프로젝트는 계획, 조직, 그리고 각 단계를 신중히 수행해야 하는 복잡한 과정입니다. 그중에서도 탐색적 데이터 분석(EDA)은 매우 중요한 단계입니다.
이 글에서는 탐색적 데이터 분석이 무엇인지, 그리고 R 프로그래밍 언어를 사용하여 어떻게 수행할 수 있는지 간략하게 살펴보겠습니다.
탐색적 데이터 분석이란 무엇인가?
탐색적 데이터 분석(EDA)은 데이터 세트의 특징을 조사하고 분석하는 과정입니다. 이는 비즈니스, 통계 또는 기계 학습 분야에서 데이터를 실제 응용에 적용하기 전에 수행됩니다.
일반적으로 데이터의 특성 및 주요 특징에 대한 요약은 시각적 방법(그래프, 표 등)을 통해 이루어집니다. 이 과정을 통해 데이터의 잠재력을 평가하고, 향후 복잡한 분석을 위한 기반을 마련합니다.
EDA를 통해 다음을 수행할 수 있습니다:
- 데이터 분석에 필요한 가설 설정
- 데이터 구조 내 숨겨진 세부 정보 탐색
- 결측값, 이상치 또는 비정상적인 데이터 발견
- 데이터 전체의 추세 및 변수 간의 관계 파악
- 분석에 불필요하거나 다른 변수와 상관관계가 있는 변수 제거
- 적절한 모델링 방법 결정
기술 데이터 분석과 탐색적 데이터 분석의 차이점
데이터 분석에는 기술적 분석과 탐색적 분석 두 가지 주요 유형이 있습니다. 이 두 분석은 서로 다른 목적을 가지지만, 함께 진행되는 경우가 많습니다.
기술적 분석은 평균, 중앙값, 최빈값 등 변수의 동작을 설명하는 데 중점을 둡니다.
탐색적 분석은 변수 간의 관계를 파악하고, 초기 통찰력을 얻어 분류, 회귀, 클러스터링과 같은 기계 학습 모델링 방향을 제시하는 것을 목표로 합니다.
두 분석 모두 데이터를 시각적으로 표현할 수 있지만, 탐색적 분석은 의사 결정자의 행동을 유도하는 실질적인 통찰력을 얻는 데 더 집중합니다.
결론적으로, 탐색적 데이터 분석은 문제 해결과 모델링 단계를 위한 솔루션을 제공하며, 기술적 분석은 데이터 세트에 대한 자세한 설명을 제공하는 데 초점을 맞춥니다.
| 기술적 분석 | 탐색적 데이터 분석 | |
| 목표 | 데이터 요약 제공 | 행동 분석 및 관계 분석 |
| 표현 | 테이블 및 그래프 | 데이터 시각화 및 그래프 |
| 설명력 | 낮은 설명력 | 높은 설명력 |
EDA의 실제 활용 사례
#1. 디지털 마케팅
디지털 마케팅은 이제 데이터 중심 프로세스로 진화했습니다. 마케팅 조직은 탐색적 데이터 분석을 활용하여 캠페인 성과를 평가하고, 소비자 투자 및 타겟팅 결정을 내립니다.
인구 통계 연구, 고객 세분화 등의 기법을 통해 마케터는 대량의 소비자 구매 데이터, 설문 조사 데이터, 패널 데이터를 사용하여 효과적인 마케팅 전략을 수립하고 실행할 수 있습니다.
웹사이트 분석을 통해 마케터는 웹사이트 내 사용자 행동에 대한 세션 수준 정보를 수집할 수 있습니다. 구글 애널리틱스는 이러한 목적으로 사용되는 대표적인 무료 분석 도구입니다.
마케팅 분야에서 일반적으로 사용되는 탐색 기법에는 마케팅 믹스 모델링, 가격 및 프로모션 분석, 판매 최적화, 탐색적 고객 분석(예: 세분화) 등이 있습니다.
#2. 탐색적 포트폴리오 분석
탐색적 데이터 분석은 포트폴리오 분석에도 자주 활용됩니다. 은행이나 대출 기관은 다양한 가치와 위험을 가진 계좌들을 관리합니다.
계좌는 보유자의 사회적 지위(고소득, 중산층, 저소득), 지리적 위치, 순자산 등 다양한 요인에 따라 달라질 수 있습니다. 대출 기관은 각 대출의 채무 불이행 위험과 수익성을 고려해야 합니다. 이때 포트폴리오 전체를 어떻게 평가할지가 중요한 문제가 됩니다.
가장 낮은 위험의 대출은 고소득층에 제공할 수 있지만, 고소득층의 수는 제한적입니다. 반대로 저소득층에게는 대출 수요가 많지만 위험은 더 높습니다.
탐색적 데이터 분석은 시계열 분석과 결합하여 다양한 차입자 세그먼트나 대출 비율에 자금을 할당하는 시기를 결정하는 데 도움을 줄 수 있습니다. 또한 포트폴리오 내에서 특정 부문의 손실을 다른 부문의 이익으로 상쇄할 수 있습니다.
#3. 탐색적 위험 분석
은행은 개별 고객의 위험 점수에 대한 신뢰도를 높이기 위해 예측 모델을 개발합니다. 신용 점수는 개인의 체납 가능성을 예측하며, 각 신청자의 신용도를 평가하는 데 널리 사용됩니다.
위험 분석은 과학계와 보험 산업에서도 이루어집니다. 온라인 결제 대행업체와 같은 금융 기관은 거래의 진위 여부를 분석하는 데 이 기법을 활발히 활용하고 있습니다.
이를 위해 고객의 거래 내역을 활용합니다. 특히 신용 카드 구매 분석에 유용합니다. 고객의 거래량이 갑자기 증가할 경우, 거래를 본인이 직접 수행했는지 확인하기 위해 연락을 취하기도 합니다. 또한 위험 분석은 잠재적 손실을 줄이는 데 기여합니다.
R을 이용한 탐색적 데이터 분석
R을 사용하여 EDA를 수행하려면 먼저 R과 R Studio(IDE)를 다운로드한 다음, 다음 패키지를 설치하고 로드해야 합니다.
# 패키지 설치
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
# 패키지 로드
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
이 튜토리얼에서는 R에 내장되어 있으며 미국 경제의 연간 경제 지표 데이터를 제공하는 'economics' 데이터 세트를 사용하고, 편의를 위해 이름을 'econ'으로 변경합니다.
econ <- ggplot2::economics
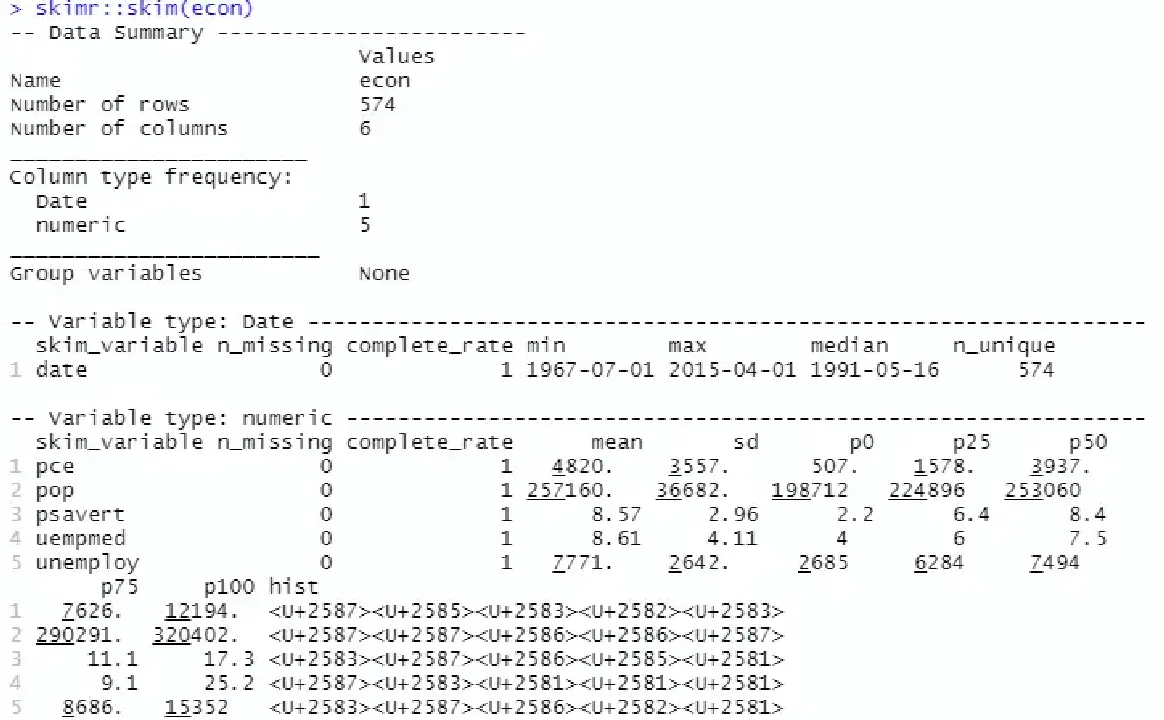
기술적 분석을 위해 통계값을 간결하게 계산해주는 'skimr' 패키지를 사용합니다.
# 기술 통계 분석 skimr::skim(econ)
기술 통계는 'summary' 함수를 사용하여 얻을 수도 있습니다.

기술 통계 결과, 데이터 세트는 547개의 행과 6개의 열로 구성되어 있으며, 날짜는 1967-07-01부터 2015-04-01까지입니다. 또한 평균값과 표준편차 등의 정보도 확인할 수 있습니다.
'econ' 데이터 세트의 기본적인 정보를 파악했습니다. 이번에는 'uempmed' 변수의 히스토그램을 그려 데이터를 좀 더 자세히 살펴보겠습니다.
# 실업률 히스토그램 econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
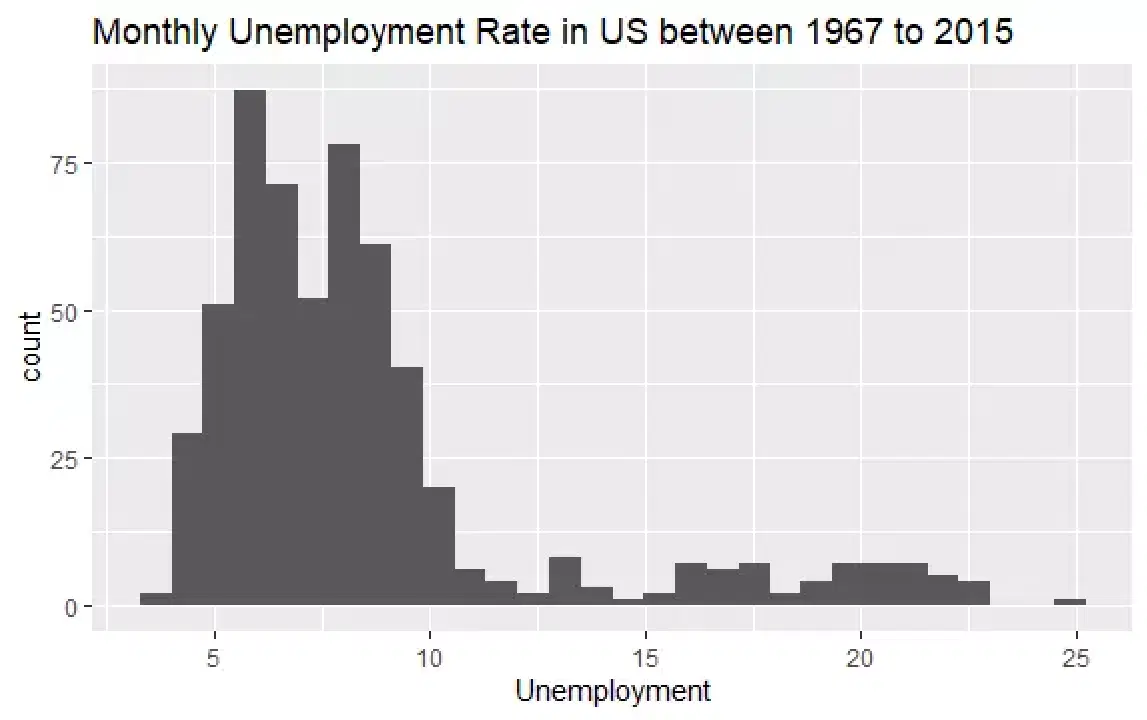
히스토그램 분포를 보면 오른쪽으로 꼬리가 길게 늘어져 있습니다. 즉, 극단적인 값이 몇 개 있을 수 있다는 것을 의미합니다. 이러한 극단적인 값이 발생한 시기는 언제이며, 변수의 추세는 어떻게 될까요?
변수의 추세를 파악하는 가장 간단한 방법은 선 그래프를 이용하는 것입니다. 아래 코드를 실행하여 선 그래프를 그리고 추세선을 추가해 보겠습니다.
# 실업률 선 그래프 econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
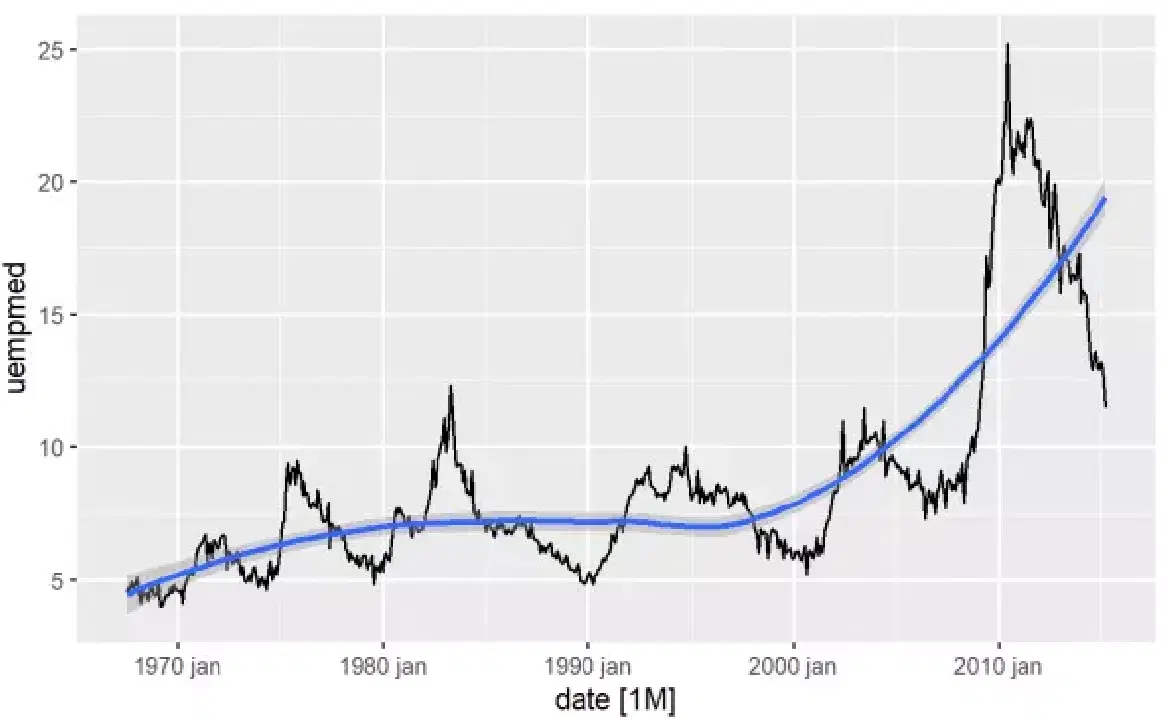
그래프를 보면 2010년 이후 실업률이 과거 수십 년간의 추세보다 훨씬 증가하는 경향을 보입니다.
계량 경제학 모델링에서 또 다른 중요한 점은 시계열의 안정성입니다. 즉, 평균과 분산이 시간에 따라 일정한지를 확인하는 것입니다.
변수가 안정적이지 않으면, 즉 단위근을 가지면 해당 변수가 받는 충격이 영구적인 영향을 미칠 수 있습니다.
실업률 변수도 이러한 특징을 보입니다. 변동성이 크게 변화했음을 알 수 있습니다. 이는 경제 이론과 관련하여 중요한 의미를 가집니다. 그렇다면 변수가 정상인지 아닌지 어떻게 확인할 수 있을까요?
'forecast' 패키지는 ADF, KPSS와 같은 검정을 적용할 수 있는 기능을 제공합니다. 이 검정은 시계열을 안정적으로 만드는 데 필요한 차분 횟수를 반환합니다.
# ADF 검정을 통한 안정성 확인 forecast::ndiffs( x = econ$uempmed, test = "adf")

p-값이 0.05보다 크면 데이터가 안정적이지 않음을 의미합니다.
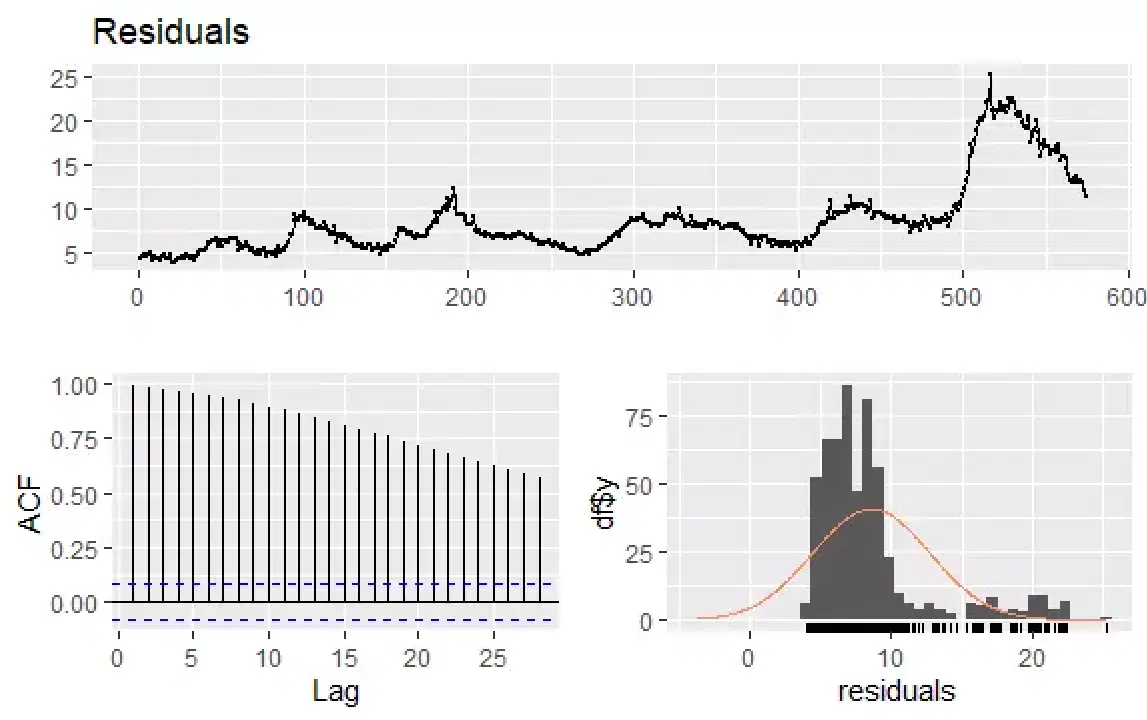
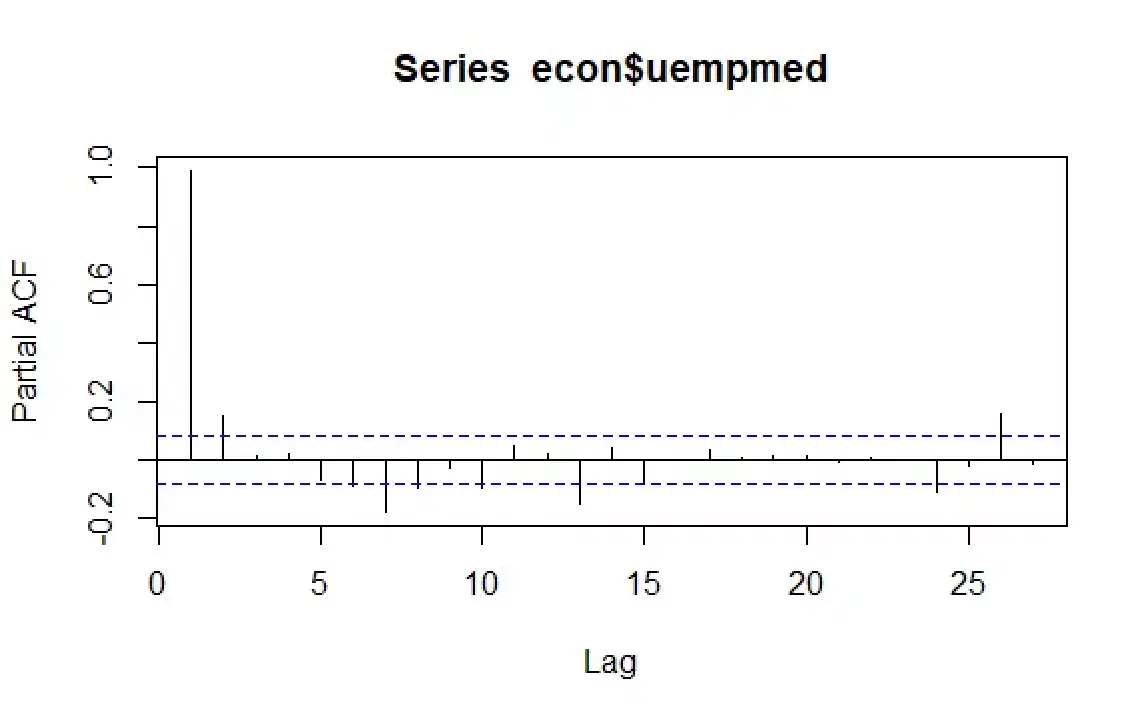
시계열 분석에서 또 다른 중요한 점은 시차 값 사이에 가능한 상관 관계(선형 관계)를 파악하는 것입니다. ACF 및 PACF 상관도는 이를 확인하는 데 도움을 줍니다.
이 데이터 세트에는 계절성은 없지만 특정 추세가 있습니다. 시간적으로 가까운 관측값은 값도 비슷한 경향이 있으므로 초기 자기 상관이 크고 양수일 가능성이 높습니다.
추세가 있는 시계열의 자기 상관 함수(ACF)는 시차가 증가함에 따라 천천히 감소하는 양수 값을 가집니다.
# 실업률 잔차 확인 checkresiduals(econ$uempmed) pacf(econ$uempmed)
결론
데이터를 정리한 후에는 곧바로 모델링을 시도하고 싶은 유혹을 느낄 수 있습니다. 하지만 이러한 유혹을 이겨내고 탐색적 데이터 분석을 먼저 수행해야 합니다. 탐색적 데이터 분석은 간단하지만, 데이터에 대한 중요한 통찰력을 얻는 데 도움이 됩니다.
데이터 과학과 통계를 학습하기 위한 유용한 자료들을 더 찾아보세요.