Python을 사용하여 PDF 파일에서 텍스트, 링크 및 이미지를 추출하는 방법
파이썬을 이용한 PDF 파일 데이터 추출 가이드
파이썬은 다양한 기능을 가진 언어이므로, 파이썬 개발자들은 여러 종류의 파일들을 다루고, 이 파일들에 저장된 정보를 가져와 처리해야 하는 상황에 자주 직면합니다. 특히, 널리 사용되는 파일 형식 중 하나는 PDF(Portable Document Format)입니다.
PDF 파일은 텍스트, 이미지, 링크 등을 포함할 수 있습니다. 파이썬 프로그램을 통해 데이터를 처리할 때, PDF 문서에 저장된 데이터를 추출해야 할 필요가 있습니다. 튜플, 리스트, 사전과 같은 일반적인 데이터 구조와 달리, PDF 문서에서 정보를 가져오는 것은 다소 복잡하게 느껴질 수 있습니다.
다행히도 PDF 파일을 쉽게 다루고 데이터를 추출할 수 있도록 도와주는 다양한 라이브러리가 존재합니다. 이 글에서는 이러한 라이브러리를 활용하여 PDF 파일에서 텍스트, 링크, 이미지를 추출하는 방법을 자세히 알아보겠습니다. 시작하기 전에, 예제 PDF 파일을 다운로드하여 파이썬 프로그램 파일과 같은 디렉토리에 저장하세요.
PyPDF2 라이브러리를 이용한 텍스트 추출
파이썬으로 PDF 파일에서 텍스트를 추출하는 가장 일반적인 방법은 PyPDF2 라이브러리를 사용하는 것입니다. PyPDF2는 PDF 파일의 페이지를 병합, 분할, 변환할 수 있는 오픈 소스 파이썬 라이브러리입니다. 또한, PDF 파일에 사용자 정의 데이터, 보기 옵션, 비밀번호를 추가하는 기능도 제공합니다. 가장 중요한 점은 PyPDF2를 사용하여 PDF 파일에서 텍스트를 추출할 수 있다는 것입니다.
PyPDF2를 사용하려면 먼저 pip를 사용하여 설치해야 합니다. pip는 파이썬 패키지를 설치하는 데 사용되는 패키지 관리자입니다.
1. 터미널에서 다음 명령을 실행하여 pip가 설치되어 있는지 확인합니다.
pip --version
만약 버전 번호가 표시되지 않으면 pip가 설치되지 않은 것입니다.
2. pip를 설치하려면 pip 설치 스크립트를 다운로드하세요.
링크를 클릭하면 아래와 같이 pip 설치 스크립트가 포함된 페이지가 열립니다.
페이지를 마우스 오른쪽 버튼으로 클릭하고 '다른 이름으로 저장'을 선택하여 파일을 저장합니다. 기본 파일 이름은 get-pip.py입니다.
터미널을 열고 get-pip.py 파일이 있는 디렉토리로 이동한 후 다음 명령을 실행합니다.
sudo python3 get-pip.py
그러면 아래와 같이 pip가 설치됩니다.
3. 다음 명령을 실행하여 pip가 성공적으로 설치되었는지 확인합니다.
pip --version
정상적으로 설치되었다면 버전 번호를 확인할 수 있습니다.

pip 설치가 완료되었으므로 PyPDF2를 사용할 준비가 되었습니다.
1. 터미널에서 다음 명령을 실행하여 PyPDF2를 설치합니다.
pip install PyPDF2
2. 파이썬 파일을 만들고 다음 코드를 추가하여 PyPDF2에서 PdfReader 클래스를 임포트합니다.
from PyPDF2 import PdfReader
PyPDF2 라이브러리는 PDF 파일을 다루기 위한 다양한 클래스를 제공합니다. 그 중 하나인 PdfReader 클래스는 PDF 파일을 열고, 내용을 읽고, 텍스트를 추출하는 데 사용됩니다.
3. PDF 파일 작업을 시작하려면 먼저 파일을 열어야 합니다. PdfReader 클래스의 인스턴스를 생성하고 작업하려는 PDF 파일을 전달하여 파일을 열 수 있습니다.
reader = PdfReader('games.pdf')
위 코드는 PdfReader 객체를 생성하고, 지정된 PDF 파일의 내용에 접근할 준비를 합니다. 생성된 객체는 reader 변수에 저장되며, 이를 통해 PdfReader 클래스의 다양한 메서드와 속성을 사용할 수 있습니다.
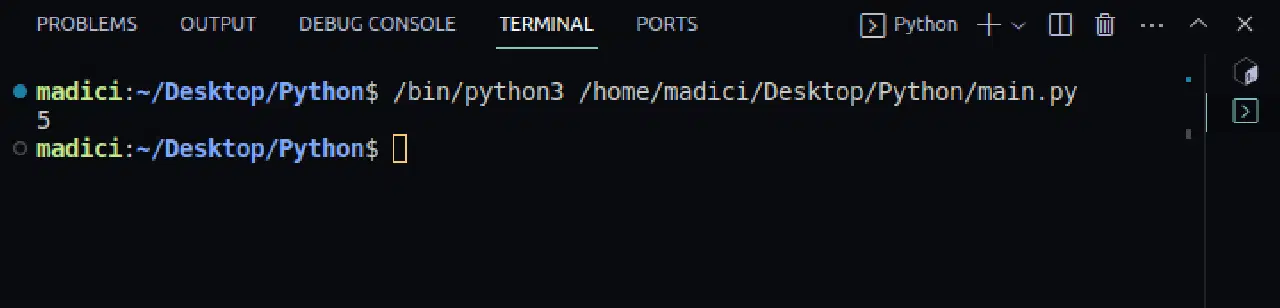
4. 코드가 정상적으로 작동하는지 확인하기 위해, 다음 코드를 사용하여 PDF 파일의 총 페이지 수를 출력합니다.
print(len(reader.pages))
출력 결과:
5
5. PDF 파일이 5페이지로 구성되어 있으므로, PDF 내의 각 페이지에 접근할 수 있습니다. 참고로, 파이썬의 인덱싱 규칙에 따라 페이지 번호는 0부터 시작합니다. 즉, PDF 파일의 첫 번째 페이지는 페이지 번호 0입니다. PDF의 첫 번째 페이지를 가져오려면 다음 코드를 추가하세요.
page1 = reader.pages[0]
위 코드는 PDF 파일의 첫 번째 페이지를 가져와 page1 변수에 저장합니다.
6. 이제 PDF 파일의 첫 번째 페이지에서 텍스트를 추출하려면 다음 코드를 추가합니다.
textPage1 = page1.extract_text()
위 코드는 PDF 첫 페이지에서 텍스트를 추출하여 textPage1 변수에 저장합니다. 이제 textPage1 변수를 통해 PDF 파일의 첫 페이지에 있는 텍스트에 접근할 수 있습니다.
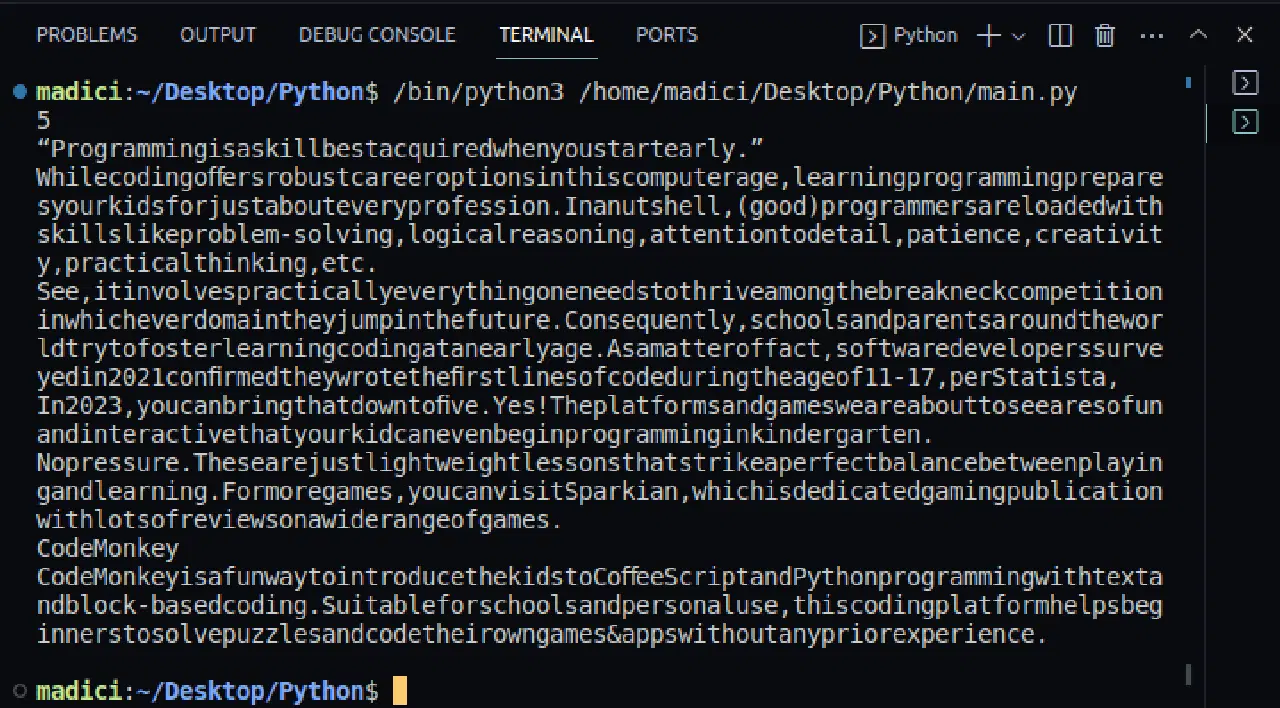
7. 텍스트가 성공적으로 추출되었는지 확인하려면 textPage1 변수의 내용을 출력해 보세요. 다음은 PDF 파일의 첫 번째 페이지에 있는 텍스트를 출력하는 전체 코드입니다.
# PyPDF2에서 PdfReader 클래스 임포트
from PyPDF2 import PdfReader
# PdfReader 클래스 인스턴스 생성
reader = PdfReader('games.pdf')
# PDF 파일의 총 페이지 수 가져오기
print(len(reader.pages))
# PDF의 첫 번째 페이지 접근
page1 = reader.pages[0]
# 첫 번째 페이지에서 텍스트 추출
textPage1 = page1.extract_text()
# 추출된 텍스트 출력
print(textPage1)
출력 결과:
PyMuPDF 라이브러리를 이용한 링크 추출
PDF 파일에서 링크를 추출하기 위해, PDF와 같은 문서를 분석, 변환, 조작하는 데 사용되는 파이썬 라이브러리인 PyMuPDF를 사용하겠습니다. PyMuPDF를 사용하려면 파이썬 3.8 이상 버전이 필요합니다. 시작하려면 다음 단계를 따르세요.
1. 터미널에서 다음 명령을 실행하여 PyMuPDF를 설치합니다.
pip install PyMuPDF
2. 다음 코드를 사용하여 PyMuPDF를 파이썬 파일로 가져옵니다.
import fitz
3. 링크를 추출하려는 PDF 파일에 접근하려면 먼저 파일을 열어야 합니다. 다음 코드를 사용하여 파일을 엽니다.
doc = fitz.open("games.pdf")
4. PDF 파일을 연 후, 다음 코드를 사용하여 PDF의 총 페이지 수를 출력합니다.
print(doc.page_count)
출력 결과:
5
5. PDF 파일에서 링크를 추출하려면 먼저 링크를 추출할 페이지를 로드해야 합니다. 다음 코드를 사용하여 페이지를 로드합니다. 여기서 숫자는 로드하려는 페이지 번호를 나타냅니다.
page = doc.load_page(0)
첫 번째 페이지에서 링크를 추출하려면 0을 전달합니다. 페이지 번호는 배열이나 사전과 같이 0부터 시작합니다.
6. 페이지에서 링크를 추출하려면 다음 코드를 사용합니다.
links = page.get_links()
지정된 페이지(여기서는 첫 번째 페이지)의 모든 링크가 추출되어 links 변수에 저장됩니다.
7. 링크 변수의 내용을 확인하려면 다음 코드를 실행하여 출력합니다.
print(links)
출력 결과:
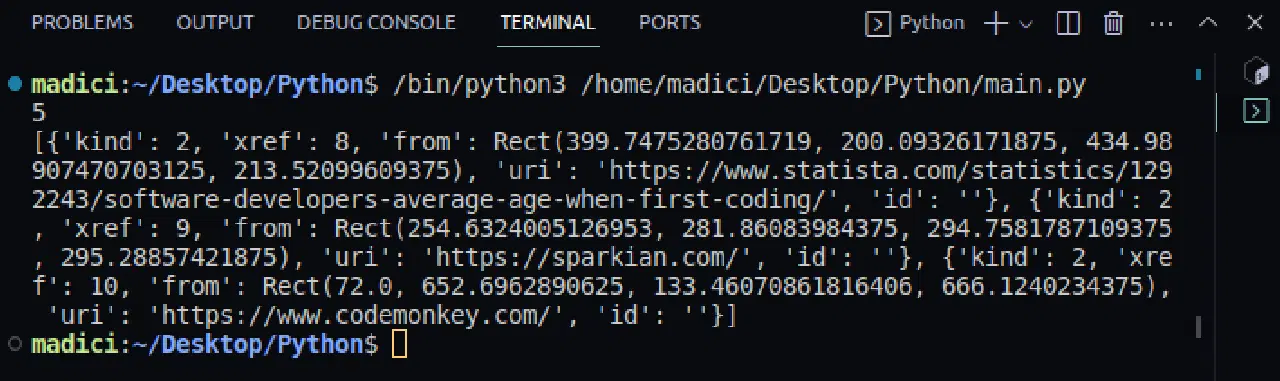
출력 결과를 보면 links 변수에 키-값 쌍으로 이루어진 사전들의 리스트가 저장되어 있음을 알 수 있습니다. 각 링크는 사전 형태로 표현되며, 실제 링크는 "uri" 키 아래에 저장됩니다.
8. links 변수에 저장된 리스트에서 실제 링크를 가져오려면, for 반복문을 사용하여 리스트를 순회하고, 각 사전에서 "uri" 키 아래에 저장된 링크를 출력합니다. 다음은 전체 코드입니다.
import fitz
# PDF 파일 열기
doc = fitz.open("games.pdf")
# 총 페이지 수 출력
print(doc.page_count)
# 첫 번째 페이지 로드
page = doc.load_page(0)
# 페이지에서 모든 링크 추출 및 저장
links = page.get_links()
# 링크 객체 출력 (주석 처리)
# print(links)
# "uri" 키에 저장된 실제 링크 출력
for obj in links:
print(obj["uri"])
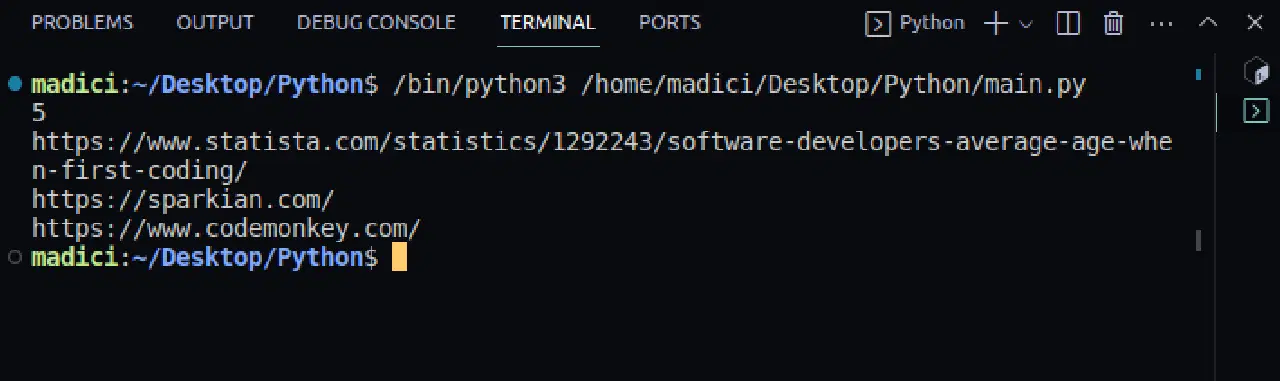
출력 결과:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
9. 코드의 재사용성을 높이기 위해, PDF에서 모든 링크를 추출하는 함수와 추출된 링크를 출력하는 함수를 정의하여 코드를 리팩토링할 수 있습니다. 이렇게 하면 PDF 파일만 전달하여 모든 링크를 쉽게 추출할 수 있습니다. 다음은 코드를 리팩토링한 버전입니다.
import fitz
# PDF 문서에서 모든 링크 추출 함수
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# PDF에서 가져온 모든 링크 출력 함수
def print_all_links(links):
for link in links:
print(link["uri"])
# 함수 호출하여 PDF 내 모든 링크 추출
all_links = extract_link("games.pdf")
# 함수 호출하여 PDF 내 모든 링크 출력
print_all_links(all_links)
출력 결과:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
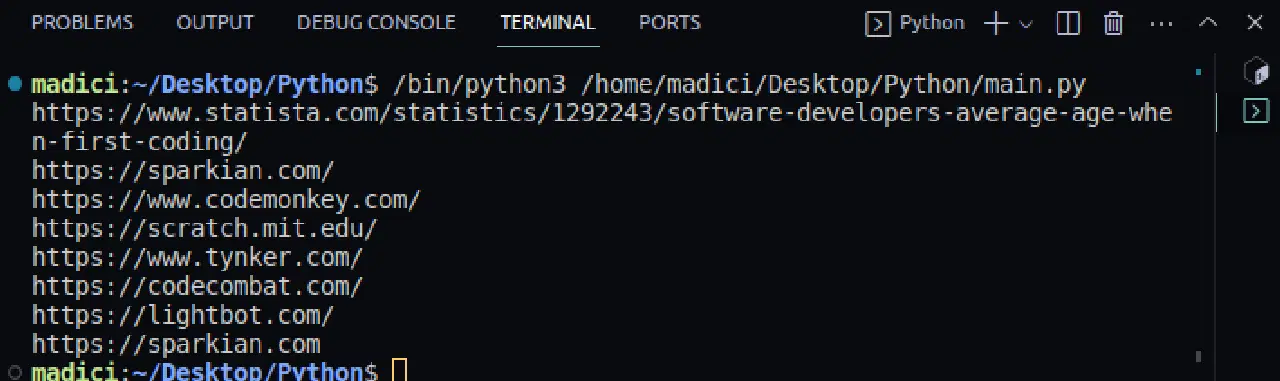
위 코드에서 extract_link() 함수는 PDF 파일 경로를 받아 해당 파일의 모든 페이지를 순회하면서 링크를 추출하여 반환합니다. 이 함수의 반환값은 all_links 변수에 저장됩니다.
print_all_links() 함수는 extract_link() 함수의 결과를 받아 리스트를 순회하면서 실제 링크를 출력합니다.
PyMuPDF와 PIL을 이용한 이미지 추출
PDF에서 이미지를 추출하기 위해 PyMuPDF를 계속 사용하겠습니다. 이미지 추출을 위해서는 다음 단계를 따르세요.
1. PyMuPDF, io 및 PIL을 임포트합니다. PIL(Python Imaging Library)은 이미지를 쉽게 생성하고 저장하는 도구를 제공하며, io는 바이너리 데이터를 효율적으로 처리하는 클래스를 제공합니다.
import fitz from io import BytesIO from PIL import Image
2. 이미지를 추출하려는 PDF 파일을 엽니다.
doc = fitz.open("games.pdf")
3. 이미지를 추출하려는 페이지를 로드합니다.
page = doc.load_page(0)
4. PyMuPDF는 일반적으로 정수 형태의 상호 참조 번호(xref)를 사용하여 PDF 파일 내 이미지를 식별합니다. PDF 파일의 모든 이미지에는 고유한 외부 참조가 있습니다. 따라서 PDF에서 이미지를 추출하려면, 먼저 해당 이미지의 외부 참조 번호를 가져와야 합니다. 페이지 내 이미지의 외부 참조 번호를 얻으려면 get_images() 함수를 사용합니다.
image_xref = page.get_images() print(image_xref)
출력 결과:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
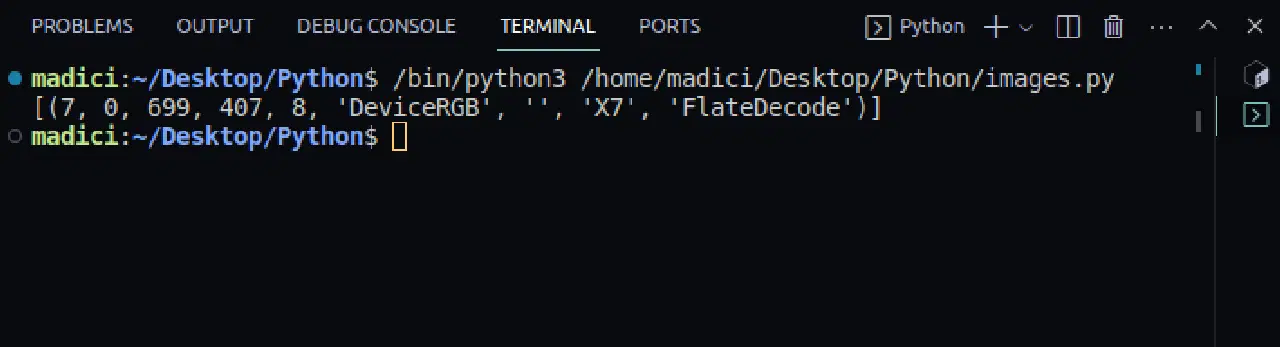
get_images() 함수는 이미지에 대한 정보가 포함된 튜플 목록을 반환합니다. 첫 번째 페이지에는 이미지가 하나만 있으므로 튜플도 하나만 반환됩니다. 튜플의 첫 번째 요소는 페이지 내 이미지의 외부 참조를 나타냅니다. 따라서 첫 번째 페이지 이미지의 외부 참조는 7입니다.
5. 튜플 리스트에서 이미지의 외부 참조 값을 추출하려면 다음 코드를 사용합니다.
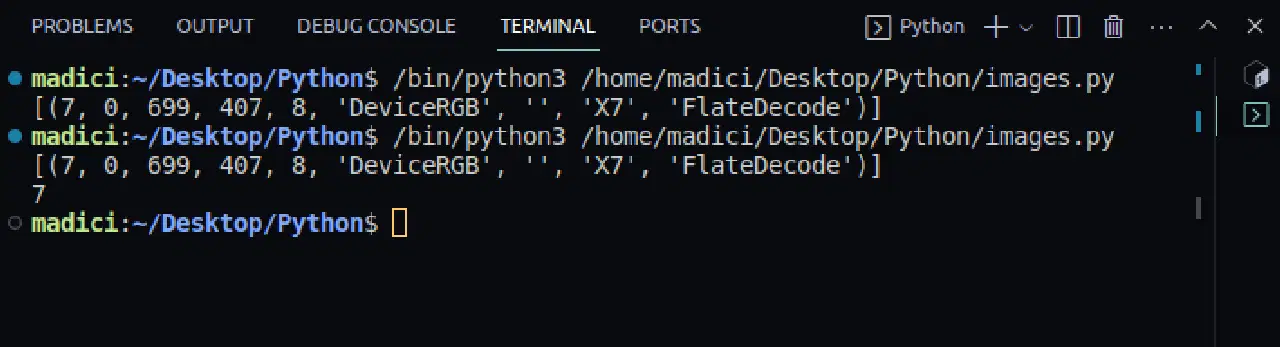
# 이미지 외부 참조 값 가져오기 xref_value = image_xref[0][0] print(xref_value)
출력 결과:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
6. 이제 PDF에서 이미지를 식별하는 외부 참조를 얻었으므로, extract_image() 함수를 사용하여 이미지를 추출할 수 있습니다.
img_dictionary = doc.extract_image(xref_value)
하지만 이 함수는 실제 이미지를 반환하지 않고, 이미지의 이진 데이터와 이미지에 대한 메타데이터를 포함하는 사전을 반환합니다.
7. extract_image() 함수가 반환한 사전에서 추출된 이미지의 파일 확장자를 확인합니다. 파일 확장자는 "ext" 키 아래에 저장됩니다.
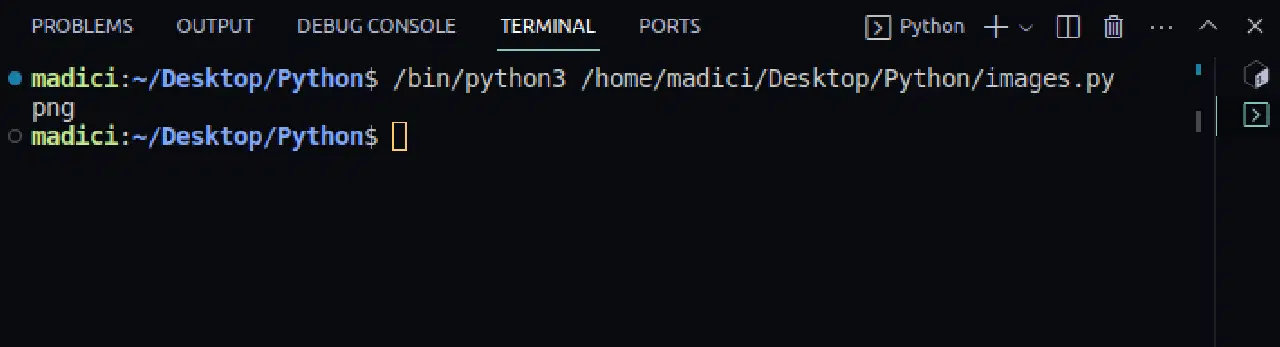
# 파일 확장자 가져오기 img_extension = img_dictionary["ext"] print(img_extension)
출력 결과:
png
8. img_dictionary에 저장된 사전에서 이미지 바이너리를 추출합니다. 이미지 바이너리는 "image" 키 아래에 저장됩니다.
# 이미지 바이너리 데이터 가져오기 img_binary = img_dictionary["image"]
9. BytesIO 객체를 생성하고, 이미지를 나타내는 바이너리 이미지 데이터로 초기화합니다. 이는 이미지를 저장할 수 있도록 PIL과 같은 파이썬 라이브러리에서 처리할 수 있는 파일 형식의 객체를 생성하는 데 필요합니다.
# 이미지 바이트 데이터를 처리하기 위한 BytesIO 객체 생성 image_io = BytesIO(img_binary)
10. PIL 라이브러리를 사용하여 image_io라는 BytesIO 객체에 저장된 이미지 데이터를 열고 구문 분석합니다. 이는 PIL 라이브러리가 이미지 형식을 결정할 수 있도록 해주며 (이 경우 PNG), 이미지 형식을 감지한 후 PIL은 save() 메서드와 같은 PIL 함수와 메서드로 조작할 수 있는 이미지 객체를 생성하여 이미지를 저장할 수 있게 합니다.
# Pillow 라이브러리를 사용하여 이미지 열기 image = Image.open(image_io)
11. 이미지를 저장할 경로를 지정합니다.
output_path = "image_1.png"
위 코드는 추출된 이미지를 현재 파이썬 파일과 같은 디렉토리에 "image_1.png"라는 이름으로 저장합니다. 확장자는 원본 이미지의 확장자와 일치해야 합니다.
12. 이미지를 저장하고 BytesIO 객체를 닫습니다.
# 이미지 저장 image.save(output_path) # BytesIO 객체 닫기 image_io.close()
PDF 파일에서 이미지를 추출하는 전체 코드는 다음과 같습니다.
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# 이미지의 외부 참조(xref) 가져오기
image_xref = page.get_images()
# 실제 이미지의 외부 참조 값 가져오기
xref_value = image_xref[0][0]
# 이미지 추출
img_dictionary = doc.extract_image(xref_value)
# 파일 확장자 가져오기
img_extension = img_dictionary["ext"]
# 실제 이미지 바이너리 데이터 가져오기
img_binary = img_dictionary["image"]
# 이미지 바이트 데이터를 다루기 위한 BytesIO 객체 생성
image_io = BytesIO(img_binary)
# PIL 라이브러리를 사용하여 이미지 열기
image = Image.open(image_io)
# 이미지를 저장할 경로 지정
output_path = "image_1.png"
# 이미지 저장
image.save(output_path)
# BytesIO 객체 닫기
image_io.close()
코드를 실행하고 파이썬 파일이 저장된 폴더로 이동하면, "image_1.png"라는 이름으로 추출된 이미지를 확인할 수 있습니다.
결론
PDF에서 링크, 이미지, 텍스트를 추출하는 방법을 더 많이 연습하려면 예제 코드에서 보여준 것처럼, 코드를 리팩토링하여 재사용 가능하게 만들어보세요. 이렇게 하면 PDF 파일만 입력하면 파이썬 프로그램이 전체 PDF에서 모든 링크, 이미지, 텍스트를 추출할 수 있게 됩니다. 즐거운 코딩하세요!
비즈니스 요구 사항에 맞는 최고의 PDF API를 찾아볼 수도 있습니다.