Python의 데이터 분석에 대한 친숙한 소개
파이썬을 활용한 데이터 분석 입문
최근 몇 년 동안 데이터 과학 분야에서 파이썬의 사용이 급증했으며, 그 추세는 앞으로도 계속될 것으로 예상됩니다. 데이터 과학은 광범위한 분야이며, 그중에서도 데이터 분석은 핵심적인 역할을 합니다. 데이터를 이해하고 기본적인 지식을 갖추는 것은 데이터 과학 기술 수준과 관계없이 점점 더 중요해지고 있습니다.
데이터 분석이란 무엇일까요?
데이터 분석은 대량의 구조화되지 않은 데이터를 정리하고 변환하여 정보에 입각한 의사 결정을 내리는 데 필요한 핵심 통찰력과 정보를 도출하는 과정입니다. 데이터 분석에는 파이썬, 마이크로소프트 엑셀, 태블로, SaS 등 다양한 도구가 사용되지만, 여기서는 파이썬과 특히 Pandas 라이브러리를 중심으로 살펴보겠습니다.
Pandas 소개
Pandas는 데이터 조작 및 랭글링에 사용되는 오픈 소스 파이썬 라이브러리입니다. 빠르고 효율적이며 다양한 형식의 데이터를 메모리에 로드하는 기능을 제공합니다. Pandas를 사용하면 데이터를 재구성, 레이블링, 분할, 색인화 또는 그룹화할 수 있습니다.
Pandas의 핵심 데이터 구조
Pandas는 세 가지 주요 데이터 구조를 제공합니다.
- Series: 1차원 배열 형태의 데이터 구조입니다.
- DataFrame: Series 객체가 여러 개 쌓인 2차원 표 형태의 데이터 구조입니다.
- Panel: DataFrame 객체가 여러 개 쌓인 3차원 데이터 구조입니다.
실제 데이터 분석에서 가장 많이 사용되는 것은 2차원 DataFrame이며, 이는 다양한 데이터 세트의 기본 표현 방식입니다.
Pandas를 이용한 데이터 분석 실습
이 문서에서는 별도의 설치 과정 없이 Google에서 제공하는 Colab 도구를 사용합니다. Colab은 데이터 분석, 머신러닝, 인공지능 연구를 위한 온라인 파이썬 환경이며, 클라우드 기반 Jupyter Notebook 형태로 제공됩니다. 데이터 과학에 필요한 대부분의 파이썬 패키지가 미리 설치되어 있어 편리합니다.
다음 링크 https://colab.research.google.com/notebooks/intro.ipynb 로 이동하여 Colab 환경을 시작할 수 있습니다.
Colab 좌측 상단의 파일 메뉴에서 "새 노트북"을 선택하여 새로운 Jupyter 노트북을 생성합니다. 가장 먼저 해야 할 일은 Pandas 라이브러리를 불러오는 것입니다. 다음 코드를 실행하여 Pandas를 사용할 수 있도록 합니다:
import pandas as pd이 예제에서는 주택 가격 데이터 세트를 사용합니다. 데이터 세트는 여기에서 다운로드할 수 있습니다. 이제 이 데이터 세트를 Colab 환경에 로드해 보겠습니다. 새로운 코드 셀을 추가하고 다음 코드를 실행합니다:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media&token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0', sep=',')read_csv 함수는 CSV 파일을 읽어들이는 데 사용되며, sep 속성은 CSV 파일이 쉼표로 구분되어 있음을 나타냅니다. 로드된 CSV 파일은 df라는 변수에 저장됩니다.
Jupyter Notebook에서는 print() 함수를 사용할 필요 없이 변수 이름을 입력하면 해당 변수의 내용이 출력됩니다. 새로운 셀에 df를 입력하고 실행하면 데이터 세트의 모든 내용이 DataFrame 형태로 출력됩니다.
데이터 세트의 모든 데이터를 보는 대신 처음 몇 개의 행과 열 이름만 확인하고 싶을 때가 있습니다. df.head() 함수는 데이터 세트의 처음 5개 행을 출력하고, df.tail() 함수는 마지막 5개 행을 출력합니다. 다음은 df.head()의 출력 결과입니다:
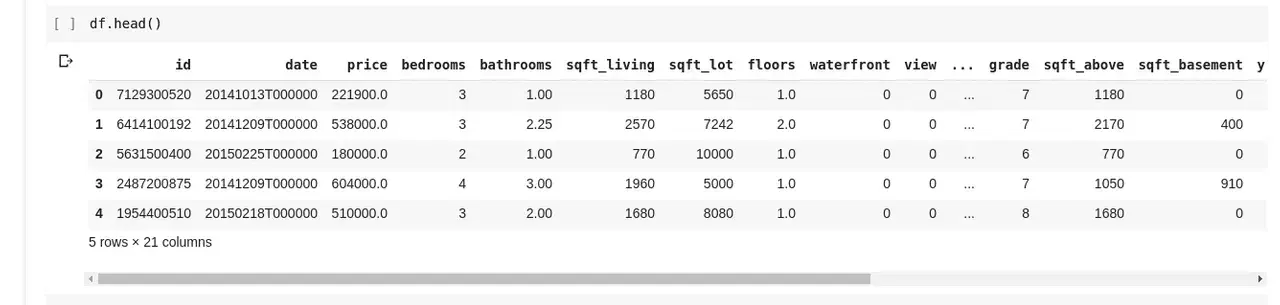
데이터 행과 열 간의 관계를 파악하기 위해 .describe() 함수를 사용할 수 있습니다. df.describe()를 실행하면 다음과 같은 결과가 나타납니다:
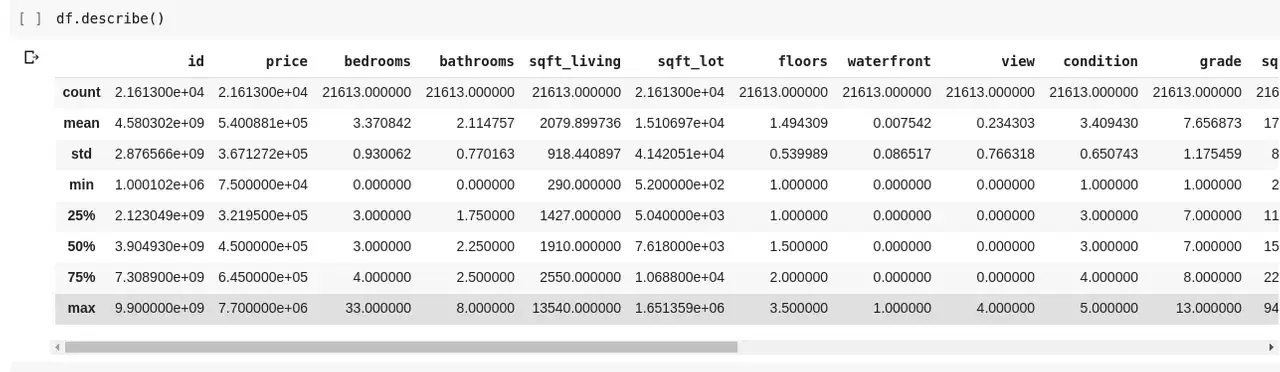
.describe() 함수는 DataFrame의 각 열에 대한 평균, 표준편차, 최소값, 최대값 및 백분위수를 제공합니다. 이 정보는 데이터의 전반적인 특성을 이해하는 데 매우 유용합니다.
데이터 프레임의 모양, 즉 행과 열의 개수를 확인하려면 df.shape 속성을 사용합니다. 이 속성은 (행 수, 열 수) 형태의 튜플을 반환합니다. 또한 df.columns 속성을 사용하여 DataFrame의 모든 열 이름을 확인할 수 있습니다.
특정 열의 데이터만 선택하고 싶다면 어떻게 해야 할까요? 이는 딕셔너리를 사용하는 방법과 유사합니다. 새로운 코드 셀에 다음 코드를 입력하고 실행합니다:
df['price']이 코드는 'price' 열의 모든 데이터를 반환합니다. 이 데이터를 새로운 변수에 저장하여 추가 작업을 수행할 수도 있습니다:
price = df['price']이제 price 변수는 실제 DataFrame의 하위 집합이므로 df.head(), df.shape 등 DataFrame에서 사용할 수 있는 모든 작업을 수행할 수 있습니다.
여러 열을 선택하려면 다음과 같이 열 이름 목록을 df에 전달할 수 있습니다:
data = df[['price', 'bedrooms']]위 코드는 'price'와 'bedrooms'라는 두 개의 열을 선택합니다. data.head()를 새로운 셀에 입력하면 다음과 같은 결과가 나타납니다:

위에서 설명한 열 슬라이싱 방식은 해당 열의 모든 행 요소를 반환합니다. 데이터 세트에서 행과 열의 하위 집합을 동시에 반환하려면 어떻게 해야 할까요? 이는 .iloc을 사용하여 파이썬 리스트와 유사한 방식으로 인덱싱할 수 있습니다. 예를 들어 다음과 같이 사용할 수 있습니다:
df.iloc[50:, 3]이 코드는 50번째 행부터 마지막 행까지의 데이터 중 4번째 열의 값을 반환합니다. 이는 파이썬에서 리스트를 슬라이싱하는 것과 매우 유사합니다.
이제 데이터 분석의 중요한 측면 중 하나를 살펴보겠습니다. 주택 가격 데이터 세트에는 주택 가격을 나타내는 열과 각 주택의 침실 수를 나타내는 열이 있습니다. 주택 가격은 연속적인 값인 반면, 침실 수는 이산적인 값입니다. 즉, 침실 수가 2개, 3개, 4개 등 특정 값으로 제한됩니다. 침실 수가 같은 모든 주택을 그룹화하고 각 그룹의 평균 가격을 구하고 싶다면 어떻게 해야 할까요?
Pandas에서는 다음 코드를 사용하여 쉽게 처리할 수 있습니다:
df.groupby('bedrooms')['price'].mean()위 코드는 df.groupby() 함수를 사용하여 침실 수가 같은 주택들을 그룹화하고, ['price']를 사용하여 'price' 열을 선택한 후, .mean() 함수를 사용하여 각 그룹의 평균 가격을 계산합니다.
결과를 시각화하기 위해 .plot() 함수를 추가하면 각 침실 수에 대한 평균 가격 변화를 그래프로 볼 수 있습니다:
df.groupby('bedrooms')['price'].mean().plot()결과로 다음과 같은 그래프가 출력됩니다:
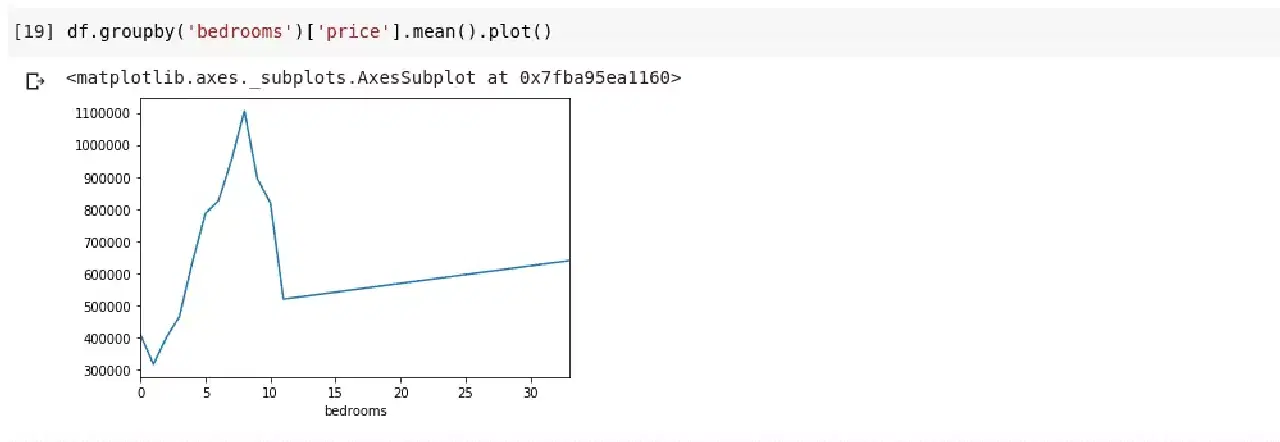
위 그래프에서 가로축은 침실 수를 나타내며, 세로축은 해당 침실 수를 가진 주택들의 평균 가격을 나타냅니다. 그래프를 통해 침실이 5개에서 10개 사이인 주택이 3개인 주택보다 훨씬 비싸다는 것을 알 수 있습니다. 또한 침실이 7~8개인 주택이 침실이 15개, 20개 심지어 30개인 주택보다 훨씬 비싸다는 사실도 확인할 수 있습니다.
이처럼 데이터 분석은 데이터에서 유용한 통찰력을 추출하는 데 중요한 역할을 합니다. 분석 없이는 발견하기 어렵거나 불가능한 정보들을 데이터로부터 얻을 수 있습니다.
결측 데이터 처리
설문조사를 실시하여 수천 명의 응답자로부터 피드백을 받는 상황을 가정해 보겠습니다. 일부 응답자는 질문에 답하는 것을 꺼려 공란으로 남겨둘 수 있습니다. 이러한 결측값은 데이터 분석에서 문제를 일으킬 수 있습니다. 예를 들어, 수치 데이터를 수집하고 분석 중에 합계, 평균 등의 계산이 필요할 때 결측값은 부정확성을 초래할 수 있습니다. 따라서 결측값을 식별하고 적절한 값으로 대체하는 것이 중요합니다.
Pandas는 isnull() 함수를 제공하여 DataFrame에서 결측값을 찾을 수 있도록 합니다.
df.isnull()위 코드는 각 셀의 값이 결측값인지 아닌지를 나타내는 부울(True/False) DataFrame을 반환합니다. 출력 결과는 다음과 같습니다:
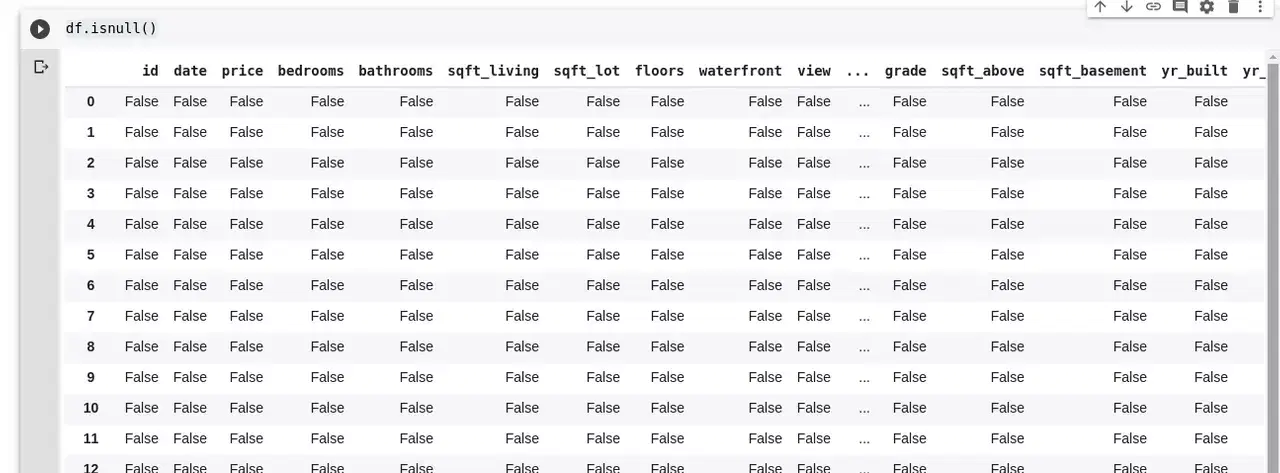
결측값을 처리하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 결측값을 0으로 채우거나, 데이터 세트의 평균값, 주변값의 평균값 등으로 대체하는 것입니다. Pandas에서는 fillna() 함수를 사용하여 결측값을 채울 수 있습니다.
df.fillna(0)위 코드는 모든 결측값을 0으로 채웁니다. 다른 값으로 채우고 싶다면 해당 값을 fillna() 함수에 전달하면 됩니다.
데이터의 중요성은 아무리 강조해도 지나치지 않으며, 데이터를 통해 올바른 결정을 내릴 수 있습니다. 데이터 분석은 디지털 경제 시대의 새로운 원유라고 할 수 있습니다.
이 문서에서 사용된 모든 코드는 다음 링크에서 확인할 수 있습니다: https://colab.research.google.com/drive/1sPP04Bp9hUITjlph6lfzRNaXb_Lli7x_
더 자세한 내용을 배우고 싶다면 파이썬 및 Pandas를 이용한 데이터 분석 온라인 강좌를 참고하시기 바랍니다.