Python을 사용한 웹 스크래핑: 단계별 가이드
웹 스크래핑이란 무엇인가?
웹 스크래핑은 인터넷상의 웹사이트에서 유용한 정보를 추출하여 특정 목적에 맞게 활용하는 기술입니다. 예를 들어, 웹 페이지에 표시된 테이블 데이터를 추출하여 JSON 파일로 저장하고, 이를 기반으로 자체적인 도구를 개발할 수 있습니다. 웹 스크래핑은 웹 페이지 내 특정 요소를 정확하게 찾아내 원하는 데이터를 수집하는 데 매우 효과적인 방법입니다.
데이터 추출 능력은 개발자나 데이터 과학자에게 필수적인 역량입니다. 이 글에서는 웹사이트를 효과적으로 스크랩하는 방법을 소개하고, 필요한 데이터를 정확히 얻어 웹사이트를 원하는 대로 조작하는 데 필요한 지식을 제공합니다. 특히, 데이터 스크래핑에 널리 사용되는 Python의 BeautifulSoup 패키지를 중심으로 설명합니다.
웹 스크래핑에 Python을 사용하는 이유
많은 개발자들이 웹 스크래퍼를 만들 때 Python을 가장 먼저 고려합니다. Python이 웹 스크래핑에 자주 선택되는 데에는 여러 가지 이유가 있지만, 여기서는 세 가지 주요 이점을 살펴보겠습니다.
풍부한 라이브러리와 커뮤니티 지원: Python은 BeautifulSoup, Scrapy, Selenium 등 웹 페이지 스크래핑에 필요한 다양한 기능을 제공하는 강력한 라이브러리를 갖추고 있습니다. 활발한 개발 커뮤니티 덕분에 문제 발생 시 신속하게 도움을 받을 수 있다는 것도 큰 장점입니다.
자동화 기능: Python은 자동화에 뛰어난 기능을 제공합니다. 웹 스크래핑을 기반으로 하는 복잡한 도구를 개발할 때, 단순히 데이터를 추출하는 것 외에도 가격 추적이나 데이터베이스 업데이트 같은 자동화 기능이 필요합니다. Python은 이러한 과정을 쉽게 자동화할 수 있도록 도와줍니다.
데이터 시각화: 웹 스크래핑은 데이터 과학 분야에서 자주 활용됩니다. Python은 Pandas와 같은 라이브러리를 통해 추출한 데이터를 시각적으로 표현하는 데 용이하여, 원시 데이터를 분석하기 쉽도록 만들어 줍니다.
Python 웹 스크래핑에 사용되는 주요 라이브러리
Python에는 웹 스크래핑 작업을 간편하게 만들어주는 다양한 라이브러리가 있습니다. 다음은 가장 널리 사용되는 세 가지 라이브러리입니다.
1. BeautifulSoup
BeautifulSoup은 웹 스크래핑에서 가장 인기 있는 라이브러리 중 하나입니다. 2004년부터 개발자들에게 웹 페이지 스크래핑을 위한 편리한 도구를 제공해 왔습니다. 이 라이브러리는 구문 분석 트리를 탐색, 검색, 수정하는 데 간편한 방법을 제공하며, 데이터 인코딩 기능도 지원합니다. BeautifulSoup은 체계적인 관리와 활발한 커뮤니티를 자랑합니다.
2. Scrapy
Scrapy는 데이터 추출에 특화된 또 다른 인기 프레임워크입니다. GitHub에서 43,000개 이상의 별을 받을 만큼 많은 지지를 얻고 있습니다. Scrapy는 API에서 데이터를 스크랩하는 데에도 사용할 수 있으며, 이메일 전송과 같은 유용한 기능을 내장하고 있습니다.
3. Selenium
Selenium은 원래 웹 스크래핑 라이브러리가 아닌 브라우저 자동화 패키지입니다. 하지만 웹 페이지 스크래핑 기능을 쉽게 확장할 수 있다는 장점이 있습니다. Selenium은 WebDriver 프로토콜을 사용하여 다양한 브라우저를 제어하며, 20년 가까이 시장에서 꾸준히 사용되고 있습니다. Selenium을 사용하면 웹 페이지에서 데이터를 자동으로 추출하고 스크랩하는 것이 용이합니다.
Python 웹 스크래핑의 어려움
웹사이트에서 데이터를 스크랩하려고 할 때 여러 가지 문제에 직면할 수 있습니다. 느린 네트워크 연결, 스크래핑 방지 도구, IP 주소 차단, 캡차 등의 문제가 있습니다. 이러한 문제들은 웹 스크래핑을 매우 어렵게 만들 수 있습니다.
하지만 몇 가지 방법을 통해 이러한 문제를 효과적으로 해결할 수 있습니다. 예를 들어, 웹사이트는 특정 시간 간격 동안 너무 많은 요청이 들어오면 IP 주소를 차단하는 경향이 있습니다. 이러한 IP 차단을 피하려면 요청 간에 딜레이를 주도록 스크래퍼를 설정해야 합니다.

또한 개발자들은 스크래퍼를 감지하기 위한 허니팟 트랩을 설치하기도 합니다. 이러한 트랩은 일반 사용자는 볼 수 없지만, 스크래퍼가 걸려들도록 설계되어 있습니다. 따라서 허니팟 트랩이 설치된 웹사이트를 스크래핑하는 경우, 이에 맞게 스크래퍼 코드를 조정해야 합니다.
캡차는 스크래퍼에게 또 다른 심각한 문제입니다. 오늘날 대부분의 웹사이트는 캡차를 사용하여 봇의 접근을 차단합니다. 이러한 경우, 캡차를 우회하기 위해 캡차 해결 프로그램을 사용해야 할 수도 있습니다.
Python을 사용하여 웹사이트 스크래핑하기
이 섹션에서는 앞서 언급한 BeautifulSoup을 사용하여 웹사이트를 스크랩하는 방법을 단계별로 설명합니다. 이 튜토리얼에서는 Coingecko 웹사이트에서 이더리움의 과거 데이터를 추출하여 테이블 형태로 저장하고, 이를 JSON 파일로 변환할 것입니다.
가장 먼저 해야 할 일은 BeautifulSoup과 requests 라이브러리를 설치하는 것입니다. 여기서는 Python 가상 환경 관리자인 Pipenv를 사용합니다. Venv를 사용해도 상관없지만, Pipenv를 선호합니다. Pipenv에 대한 자세한 설명은 이 튜토리얼의 범위를 벗어나므로, Pipenv 사용법 또는 Python 가상 환경에 대한 추가 정보가 필요하면 관련 가이드를 참고하십시오.
프로젝트 디렉토리에서 ‘pipenv shell’ 명령을 실행하여 Pipenv 셸을 시작합니다. 이는 하위 셸을 가상 환경 내에서 실행하는 것입니다. 이제 다음 명령을 실행하여 BeautifulSoup를 설치합니다.
pipenv install beautifulsoup4
requests를 설치하려면 다음 명령을 실행합니다.
pipenv install requests
설치가 완료되면 필요한 패키지를 main.py 파일에 가져옵니다.
from bs4 import BeautifulSoup import requests import json
다음으로, 기록 데이터 페이지의 내용을 가져와 BeautifulSoup에서 사용할 수 있는 HTML 파서를 사용하여 분석합니다.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
위 코드에서 requests 라이브러리의 get 메서드를 사용하여 웹 페이지에 접근하고, 분석된 내용은 soup 변수에 저장됩니다.
이제 스크래핑의 핵심 부분이 시작됩니다. 먼저, DOM에서 테이블을 정확하게 식별해야 합니다. 웹 페이지를 열고 개발자 도구를 사용하여 테이블을 검사해 보면, 테이블이 ‘table table-striped text-sm text-lg-normal’ 클래스를 가지고 있다는 것을 알 수 있습니다.
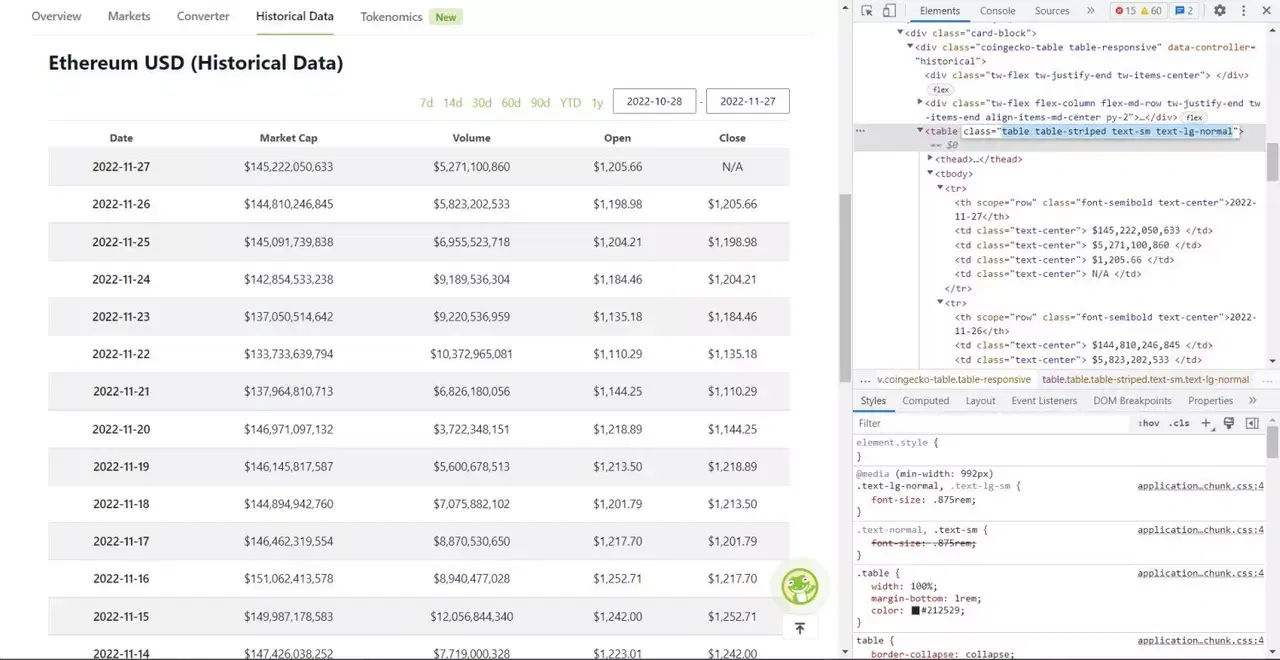 Coingecko 이더리움 과거 데이터 표
Coingecko 이더리움 과거 데이터 표
이 테이블을 특정하려면 find 메서드를 사용합니다.
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
위 코드에서 soup.find 메서드를 사용하여 테이블을 찾은 다음, find_all 메서드를 사용하여 테이블 내 모든 tr 요소를 검색합니다. 이 tr 요소들은 table_data 변수에 저장됩니다. 테이블에는 여러 제목 요소가 있습니다. 제목을 목록으로 유지하기 위해 table_headings라는 새 변수가 초기화됩니다.
그 다음 테이블의 첫 번째 행에 대해 for 루프가 실행됩니다. 이 행에서 th 요소를 모두 찾아 그 텍스트 값을 table_headings 목록에 추가합니다. 텍스트는 text 메서드를 사용하여 추출됩니다. table_headings 변수를 출력하면 다음 결과를 볼 수 있습니다.
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
다음 단계는 나머지 요소를 스크랩하고 각 행에 대한 사전을 생성한 다음, 해당 사전을 목록에 추가하는 것입니다.
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('n', '')})
if data.__len__() > 0:
table_details.append(data)
이 코드는 매우 중요합니다. table_data 변수의 각 tr에 대해 먼저 th 요소를 찾습니다. th 요소는 테이블에 표시된 날짜입니다. 이 th 요소는 th 변수에 저장됩니다. 마찬가지로 모든 td 요소는 td 변수에 저장됩니다.
빈 사전인 data가 초기화됩니다. 초기화 후, td 요소의 범위를 반복합니다. 각 행에 대해 먼저 사전의 첫 번째 필드를 th의 첫 번째 항목으로 업데이트합니다. 코드는 ‘table_headings[0]: th[0].text’를 통해 날짜와 첫 번째 요소의 키-값 쌍을 할당합니다.
첫 번째 요소를 초기화한 후, 다른 요소는 ‘data.update({table_headings[i+1]: td[i].text.replace('n', '')})’로 업데이트합니다. 여기서 td 요소의 텍스트는 먼저 text 메서드를 사용하여 추출하고, replace 메서드를 사용하여 ‘n’을 제거합니다. i번째 요소가 이미 할당되었으므로, table_headings 목록의 i+1번째 요소에 값이 할당됩니다.
데이터 사전의 길이가 0보다 크면, 해당 사전을 table_details 목록에 추가합니다. table_details 목록을 출력하여 내용을 확인할 수 있지만, 여기서는 JSON 파일에 저장할 것입니다. 다음은 그에 대한 코드입니다.
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
여기서는 json.dump 메서드를 사용하여 데이터를 ‘table.json’이라는 JSON 파일에 저장합니다. 저장이 완료되면, 데이터가 JSON 파일에 저장되었다는 메시지를 콘솔에 출력합니다.
이제 다음 명령을 사용하여 파일을 실행합니다.
python run main.py
잠시 후, 콘솔에서 ‘Data saved to json file...’라는 메시지를 확인할 수 있습니다. 또한 작업 디렉토리에 ‘table.json’이라는 새로운 파일이 생성됩니다. 파일의 내용은 다음과 같은 JSON 형식입니다.
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
이로써 Python을 사용하여 웹 스크래퍼를 성공적으로 구현했습니다. 전체 코드는 GitHub 저장소에서 확인할 수 있습니다.
결론
이 글에서는 Python을 사용하여 간단한 웹 스크래퍼를 만드는 방법을 살펴보았습니다. BeautifulSoup을 사용하여 웹사이트에서 데이터를 빠르고 효율적으로 스크랩하는 방법을 알아보았습니다. 또한 다른 유용한 라이브러리와, 많은 개발자가 웹 스크래핑에 Python을 선호하는 이유에 대해서도 논의했습니다.
웹 스크래핑 프레임워크에 대한 추가 정보는 다음 자료를 참고하십시오.