Python에서 Lambda 함수를 사용하는 방법 [With Examples]
본 튜토리얼에서는 파이썬 람다 함수에 대한 모든 것을 알아봅니다. 람다 함수를 정의하는 문법부터 다양한 활용 사례까지 코드 예시를 통해 상세히 설명합니다.
파이썬에서 람다는 간결한 문법을 가진 익명 함수이며, 다른 유용한 내장 함수들과 함께 활용될 수 있습니다. 이 튜토리얼을 마치면 람다 함수를 정의하는 방법과 일반 파이썬 함수 대신 람다 함수를 사용하는 것이 더 적합한 경우를 이해하게 될 것입니다.
자, 시작해 볼까요!
파이썬 람다 함수: 문법과 예시
다음은 파이썬에서 람다 함수를 정의하는 일반적인 문법입니다.
lambda 매개변수(들): 반환 값위의 문법에서:
lambda는 람다 함수를 정의할 때 사용해야 하는 키워드이며, 그 뒤에는 함수가 받을 하나 이상의 매개변수가 옵니다.- 매개변수와 반환 값을 구분하는 콜론(
:)이 있습니다.
💡 람다 함수를 정의할 때, 반환 값은 단일 표현식을 평가하여 계산되어야 하며, 이 표현식은 한 줄의 코드로 작성되어야 합니다. 예제를 통해 더 자세히 이해해 보겠습니다.
파이썬 람다 함수 예제
람다 함수를 이해하는 가장 좋은 방법은 일반 파이썬 함수를 람다 함수로 재작성하는 것부터 시작하는 것입니다.
👩🏽💻 파이썬 REPL 또는 온라인 파이썬 편집기에서 코드를 직접 작성해 볼 수 있습니다.
#1. 숫자 num을 인수로 받아 해당 숫자의 제곱을 반환하는 다음 함수 square()를 생각해 봅시다.
def square(num):
return num*num인수를 사용하여 함수를 호출하고 정상적으로 작동하는지 확인할 수 있습니다.
>>> square(9)
81
>>> square(12)
144이 람다 표현식을 변수 이름(예: square1)에 할당하여 함수 정의를 더욱 간결하게 만들 수 있습니다. square1 = lambda num: num*num 이후에는 임의의 숫자를 인수로 사용하여 square1 함수를 호출할 수 있습니다. 하지만 람다가 익명 함수라는 점을 고려하면 변수에 할당하는 것은 피하는 것이 좋습니다.
square() 함수의 경우 매개변수는 num이고, 반환 값은 num*num입니다. 이들을 파악한 후에는 다음과 같이 람다 표현식에 연결하고 인수를 사용하여 호출할 수 있습니다.
>>> (lambda num: num*num)(2)
4이것이 바로 함수를 정의한 직후에 호출하는 즉시 호출 함수 표현식의 개념입니다.
#2. 다음으로 숫자 num1과 num2를 인자로 받아 그 합 num1 + num2를 반환하는 또 다른 간단한 함수 add()를 재작성해 보겠습니다.
def add(num1, num2):
return num1 + num2두 개의 숫자를 인수로 사용하여 add() 함수를 호출해 봅시다.
>>> add(4, 3)
7
>>> add(12, 5)
17
>>> add(12, 6)
18이 경우 num1과 num2는 두 개의 매개변수이고, 반환 값은 num1 + num2입니다.
>>> (lambda num1, num2: num1 + num2)(3, 7)
10파이썬 함수는 매개변수에 기본값을 사용할 수도 있습니다. add() 함수의 정의를 수정하고 num2 매개변수의 기본값을 10으로 설정해 보겠습니다.
def add(num1, num2=10):
return num1 + num2다음 함수 호출에서:
- 첫 번째 함수 호출에서
num1의 값은 1이고num2의 값은 3입니다. 함수 호출 시num2의 값을 전달하면 해당 값이 사용됩니다. 함수는 4를 반환합니다.
- 그러나 하나의 인수(
num1은 7)만 전달하면num2에 기본값 10이 사용됩니다. 함수는 17을 반환합니다.
>>> add(1, 3)
4
>>> add(7)
17특정 매개변수에 대한 기본값을 람다 표현식으로 사용하는 함수를 작성할 때, 매개변수를 정의할 때 기본값을 지정할 수 있습니다.
>>> (lambda num1, num2=10: num1 + num2)(1)
11파이썬에서 람다 함수는 언제 사용해야 할까요?
이제 파이썬에서 람다 함수의 기본 사항을 익혔으므로, 몇 가지 사용 사례를 살펴보겠습니다.
- 반환 표현식이 한 줄의 코드인 함수가 있고, 동일한 모듈의 다른 곳에서 해당 함수를 참조할 필요가 없을 때 람다 함수를 사용할 수 있습니다. 지금까지 예시를 통해 이 부분을 확인했습니다.
map(),filter(),reduce()와 같은 내장 함수를 사용할 때 람다 함수를 활용할 수 있습니다.- 람다 함수는 리스트와 딕셔너리 같은 파이썬 데이터 구조를 정렬하는 데 유용하게 사용될 수 있습니다.
내장 함수와 함께 파이썬 람다를 사용하는 방법
1. map()과 함께 람다 사용하기
map() 함수는 iterable과 함수를 인자로 받아, iterable의 각 요소에 함수를 적용합니다.
nums 리스트를 생성하고, map() 함수를 사용하여 nums 리스트의 각 숫자의 제곱을 포함하는 새로운 리스트를 만들어 봅시다. 제곱 연산을 정의하기 위해 람다 함수를 사용하고 있다는 점에 주목하세요.
>>> nums = [4, 5, 6, 9]
>>> list(map(lambda num: num*num, nums))
[16, 25, 36, 81]map() 함수는 map 객체를 반환하므로, 이를 리스트로 변환해야 합니다.
▶️ 파이썬의 map() 함수에 대한 튜토리얼을 참조하세요.
2. filter()와 함께 람다 사용
숫자 리스트인 nums를 정의해 봅시다.
>>> nums = [4, 5, 6, 9]이 리스트를 필터링하여 홀수만 남기고 싶다고 가정해 보겠습니다.
파이썬의 내장 함수인 filter()를 사용할 수 있습니다.
filter() 함수는 조건과 iterable을 인자로 받습니다: filter(condition, iterable). 결과에는 조건을 충족하는 원본 iterable의 요소만 포함됩니다. 반환된 객체는 list와 같은 파이썬 iterable로 변환할 수 있습니다.
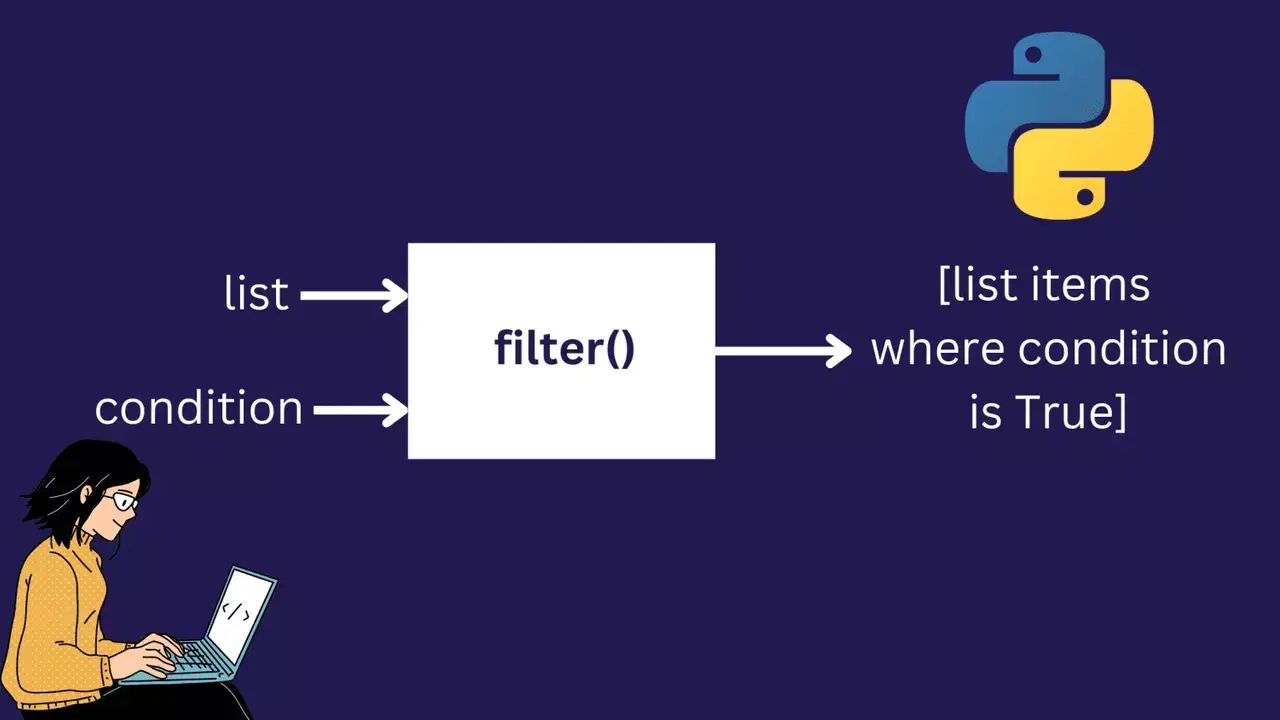
짝수를 모두 걸러내고 홀수만 남기도록 해 봅시다. 따라서 람다 표현식은 lambda num: num%2 != 0이어야 합니다. num%2는 num을 2로 나눈 나머지입니다.
num%2 != 0은num이 홀수일 때마다True입니다.num%2 != 0은num이 짝수일 때마다False입니다.
>>> nums = [4, 5, 6, 9]
>>> list(filter(lambda num: num%2 != 0, nums))
[5, 9]3. reduce()와 함께 람다 사용
reduce() 함수는 iterable과 함수를 인자로 받습니다. iterable의 요소에 함수를 반복적으로 적용하여 iterable을 하나의 값으로 줄입니다.
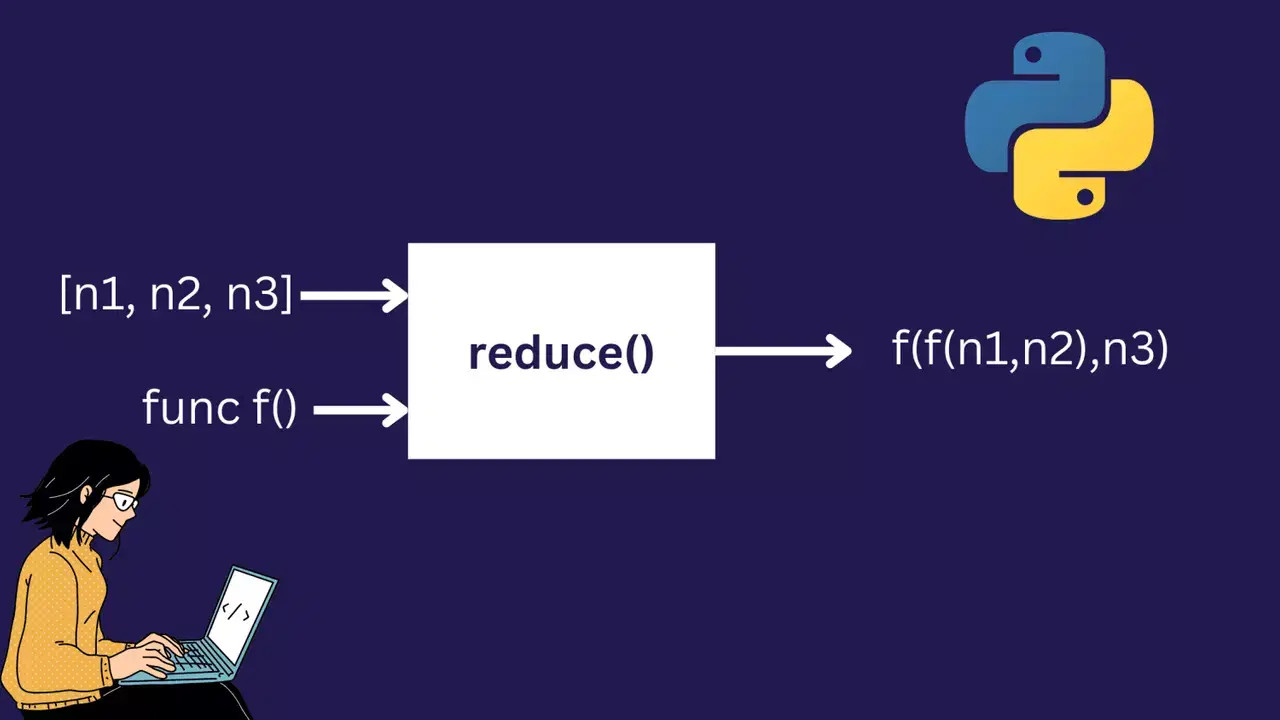
reduce() 함수를 사용하려면 파이썬의 내장 functools 모듈에서 가져와야 합니다.
>>> from functools import reducereduce() 함수를 사용하여 nums 리스트에 있는 모든 숫자의 합을 계산해 봅시다. 람다 표현식 lambda num1, num2: num1 + num2를 합산 함수로 정의합니다.
리듀스 연산은 다음과 같이 진행됩니다. f(f(f(4, 5), 6), 9) = f(f(9, 6), 9) = f(15, 9) = 24, 여기서 f는 람다 함수로 정의된 리스트의 두 요소에 대한 덧셈 연산입니다.
>>> from functools import reduce
>>> nums = [4, 5, 6, 9]
>>> reduce(lambda num1, num2: num1 + num2, nums)
24정렬 사용자 정의를 위한 파이썬 람다 함수
map(), filter() 및 reduce()와 같은 내장 파이썬 함수와 함께 람다 함수를 사용할 뿐만 아니라, 정렬에 사용되는 내장 함수와 메서드를 사용자 정의하는 데에도 활용할 수 있습니다.

1. 파이썬 리스트 정렬하기
파이썬 리스트를 다룰 때, 특정 정렬 기준에 따라 리스트를 정렬해야 할 경우가 많습니다. 파이썬 리스트를 제자리에서 정렬하려면 내장 메서드 sort()를 사용할 수 있습니다. 리스트의 정렬된 복사본이 필요하면 sorted() 함수를 사용할 수 있습니다.
파이썬의 sorted() 함수 문법은 sorted(iterable, key=..., reverse=True | False)입니다.
key매개변수는 정렬을 사용자 정의하는 데 사용됩니다.reverse매개변수는True또는False로 설정할 수 있습니다. 기본값은False입니다.
숫자 및 문자열 리스트를 정렬할 때 기본 정렬은 각각 오름차순 및 알파벳순입니다. 그러나 때로는 정렬을 위해 사용자 정의 기준을 정의해야 할 수도 있습니다.
다음과 같은 fruits 리스트를 생각해 봅시다. 리스트의 정렬된 복사본을 얻고 싶다고 가정합니다. 문자열 내에서 'p'가 나타나는 횟수에 따라 내림차순으로 문자열을 정렬해야 합니다.
>>> fruits = ['apple', 'pineapple', 'grapes', 'mango']이제 선택적 key 매개변수를 사용할 차례입니다. 문자열은 파이썬에서 iterable이며, 문자열 내에서 문자의 발생 횟수를 얻으려면 내장 메서드 .count()를 사용할 수 있습니다. 따라서 정렬이 문자열 내에서 'p'가 나타나는 횟수를 기반으로 하도록 key를 lambda x: x.count('p')로 설정합니다.
>>> fruits = ['apple', 'pineapple', 'grapes', 'mango']
>>> sorted(fruits, key=lambda x: x.count('p'), reverse=True)
['pineapple', 'apple', 'grapes', 'mango']이 예시에서:
- 정렬 기준은 문자 'p'의 발생 횟수로, 람다 표현식으로 정의됩니다.
reverse매개변수를True로 설정했으므로, 'p'가 나타나는 횟수가 감소하는 순서로 정렬됩니다.
fruits 리스트에서 'pineapple'에는 'p'가 3번, 'apple'에는 2번, 'grapes'에는 1번, 'mango'에는 0번 나타납니다.
안정 정렬 이해하기
다른 예시를 생각해 봅시다. 같은 정렬 기준에 대해 fruits 리스트를 재정의했습니다. 여기에서 'p'는 문자열 'apple'과 'grapes'에서 각각 두 번과 한 번 나타납니다. 그리고 'mango'와 'melon' 문자열에서는 전혀 나타나지 않습니다.
>>> fruits = ['mango', 'apple', 'melon', 'grapes']
>>> sorted(fruits, key=lambda x: x.count('p'), reverse=True)
['apple', 'grapes', 'mango', 'melon']출력된 리스트에서 'mango'는 문자 'p'가 없지만 'melon' 앞에 나옵니다. 왜 그럴까요? sorted() 함수는 안정 정렬을 수행합니다. 따라서 'p'의 개수가 두 문자열에 대해 같을 경우, 원본 fruits 리스트의 요소 순서가 유지됩니다.
빠른 연습으로, fruits 리스트에서 'mango'와 'melon'의 위치를 바꾸고 같은 기준에 따라 리스트를 정렬한 다음, 출력을 관찰해 보세요.
▶️ 파이썬 리스트 정렬에 대해 더 알아보세요.
2. 파이썬 딕셔너리 정렬하기
파이썬 딕셔너리를 정렬할 때도 람다 함수를 사용할 수 있습니다. 항목과 가격이 포함된 다음 딕셔너리 price_dict를 생각해 봅시다.
>>> price_dict = {
... 'Milk': 10,
... 'Honey': 15,
... 'Bread': 7,
... 'Candy': 3
... }딕셔너리의 키-값 쌍을 튜플 리스트로 가져오려면 내장 딕셔너리 메서드 .items()를 사용할 수 있습니다.
>>> price_dict_items = price_dict.items()
dict_items([('Milk', 10), ('Honey', 15), ('Bread', 7), ('Candy', 3)])파이썬에서 모든 iterable(리스트, 튜플, 문자열 등)은 0-인덱싱을 따릅니다. 따라서 첫 번째 항목은 인덱스 0에 있고, 두 번째 항목은 인덱스 1에 있습니다.
딕셔너리에 있는 각 항목의 가격인 값으로 정렬하고 싶습니다. price_dict_items 리스트의 각 튜플에서 인덱스 1의 항목이 가격입니다. 따라서 key를 lambda x: x[1]로 설정합니다. 이는 인덱스 1의 항목인 가격을 사용하여 딕셔너리를 정렬하라는 의미입니다.
>>> dict(sorted(price_dict_items, key=lambda x: x[1]))
{'Candy': 3, 'Bread': 7, 'Milk': 10, 'Honey': 15}출력 결과에서 딕셔너리 항목은 가격의 오름차순으로 정렬되었습니다. 가격이 3인 'Candy'부터 시작하여 가격이 15인 'Honey'까지입니다.
▶️ 자세한 내용은 파이썬 딕셔너리를 키와 값으로 정렬하는 가이드를 참조하세요.
정리
자, 이제 람다 함수를 정의하고 다른 파이썬 내장 함수와 함께 효과적으로 사용하는 방법을 배웠습니다. 주요 내용을 요약해 보겠습니다.
- 파이썬에서 람다는 여러 인수를 받을 수 있고 값을 반환하는 익명 함수입니다. 이 반환 값을 생성하기 위해 평가할 표현식은 한 줄의 코드여야 합니다. 작은 함수 정의를 더 간결하게 만드는 데 사용할 수 있습니다.
- 람다 함수를 정의하려면
lambda 매개변수(들): 반환 값과 같은 문법을 사용합니다. - 주요 사용 사례 중 일부는
map(),filter(),reduce()함수와 함께 사용하고 파이썬 iterable의 정렬을 사용자 정의하기 위한key매개변수로 사용하는 것입니다.
다음으로는 파이썬에서 나눗셈을 수행하는 방법을 배워봅시다.