MongoDB에서 집계 파이프라인을 사용하는 방법
MongoDB 집계 파이프라인: 복잡한 쿼리 실행의 핵심
MongoDB에서 복잡한 쿼리를 수행하는 데 가장 권장되는 방법은 집계 파이프라인을 활용하는 것입니다. 만약 이전에 MongoDB의 MapReduce 기능을 사용해 왔다면, 보다 효율적인 데이터 처리를 위해 집계 파이프라인으로의 전환을 고려해 볼 가치가 있습니다.
MongoDB 집계란 무엇이며, 어떻게 작동하는가?
집계 파이프라인은 MongoDB에서 복잡한 쿼리를 처리하기 위한 다단계 프로세스입니다. 데이터는 여러 단계를 거치면서 변환되고 처리됩니다. 각 단계의 결과는 다음 단계의 입력으로 사용될 수 있습니다. 마치 파이프라인처럼 데이터가 흘러가는 구조입니다.
예를 들어, 특정 필터링 조건을 만족하는 데이터를 추출한 후, 그 결과를 정렬하거나 그룹화하는 단계로 넘겨 최종 결과를 얻을 수 있습니다.
각 집계 파이프라인 단계는 MongoDB 연산자를 포함하며, 이는 하나 이상의 변환된 문서를 생성합니다. 쿼리 요구 사항에 따라 특정 단계가 파이프라인 내에서 여러 번 사용될 수 있습니다. 예를 들어, $count나 $sort 연산자 단계가 집계 파이프라인 전체에 걸쳐 여러 번 필요할 수도 있습니다.
집계 파이프라인의 단계별 분석
집계 파이프라인은 데이터를 여러 단계를 거쳐 처리합니다. 다양한 단계들이 있으며, 상세한 내용은 MongoDB 공식 문서에서 확인할 수 있습니다.
여기서는 가장 일반적으로 사용되는 몇 가지 단계를 살펴보겠습니다.
$match 단계
이 단계는 다른 집계 단계를 시작하기 전에 특정 필터링 조건을 정의하는 데 사용됩니다. 즉, 집계 파이프라인에 포함시킬 특정 데이터를 선택하는 역할을 합니다.
$group 단계
그룹 단계에서는 키-값 쌍을 사용하여 특정 기준에 따라 데이터를 여러 그룹으로 나눕니다. 각 그룹은 출력 문서의 키를 나타냅니다.
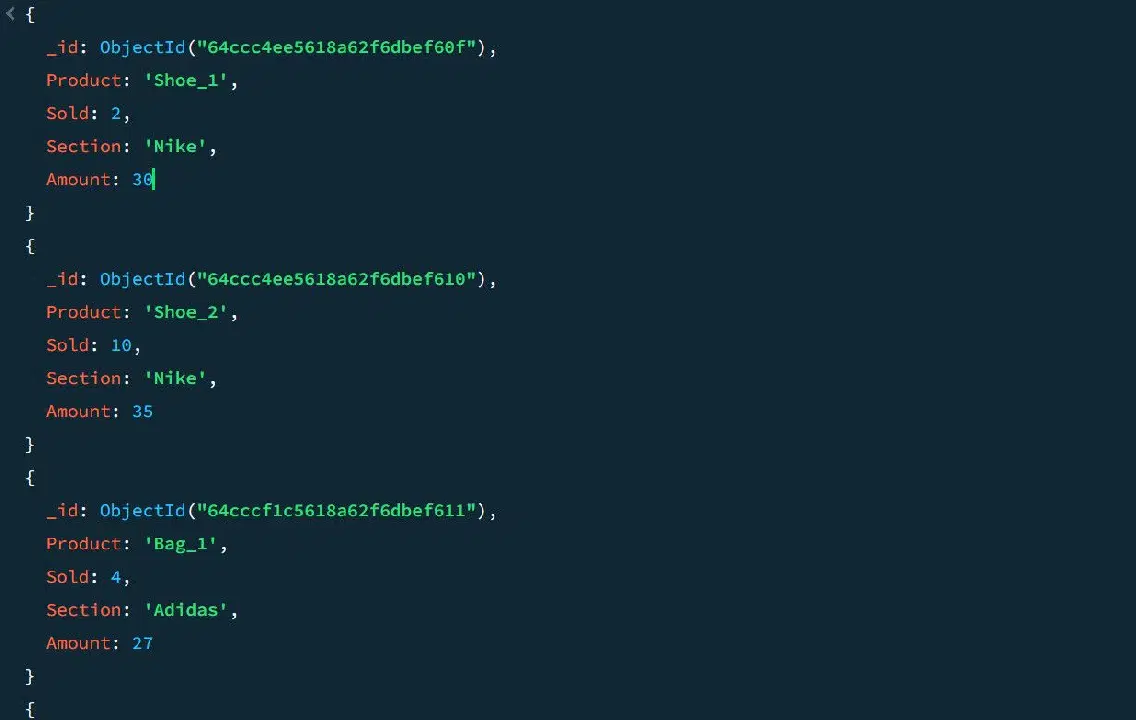
다음과 같은 판매 데이터 샘플을 예시로 들어보겠습니다.
집계 파이프라인을 사용하면 각 제품 섹션별 총 판매량과 최대 판매량을 계산할 수 있습니다.
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
_id: $Section 쌍은 섹션을 기준으로 결과 문서를 그룹화합니다. total_sales_count 및 top_sales 필드를 지정함으로써 MongoDB는 집계자가 정의한 작업을 기반으로 새로운 키를 생성합니다. 여기서 사용된 $sum, $max 외에도 $min, $avg 등의 연산자를 사용할 수 있습니다.
$skip 단계
$skip 단계를 사용하면 지정된 수의 문서를 결과에서 생략할 수 있습니다. 이는 일반적으로 그룹화 이후에 사용됩니다. 예를 들어, 두 개의 결과 문서가 있지만 하나를 건너뛰고 싶다면, 집계 파이프라인은 두 번째 문서만 출력합니다.
skip 단계를 추가하려면 $skip 연산자를 집계 파이프라인에 삽입합니다.
...,
{
$skip: 1
},
$sort 단계
정렬 단계에서는 데이터를 오름차순 또는 내림차순으로 정렬할 수 있습니다. 이전 예시 쿼리의 데이터를 내림차순으로 추가 정렬하여 매출이 가장 높은 섹션을 확인할 수 있습니다.
이전 쿼리에 $sort 연산자를 추가합니다.
...,
{
$sort: {top_sales: -1}
},
$limit 단계
limit 연산자는 집계 파이프라인의 결과로 반환할 문서 수를 제한합니다. 예를 들어, 이전 단계에서 반환된 데이터 중 매출이 가장 높은 단일 섹션만 가져오고 싶다면 $limit 연산자를 사용할 수 있습니다.
...,
{
$sort: {top_sales: -1}
},
{"$limit": 1}
위의 코드는 첫 번째 문서만 반환합니다. 정렬된 결과의 최상위에 위치하는, 매출이 가장 높은 섹션이 반환됩니다.
$project 단계
$project 단계를 사용하면 원하는 대로 출력 문서의 구조를 변경할 수 있습니다. $project 연산자를 사용하면 출력에 포함할 필드를 지정하고, 해당 키 이름을 사용자 정의할 수 있습니다.
예를 들어, $project 단계가 적용되지 않은 샘플 출력은 다음과 같습니다.
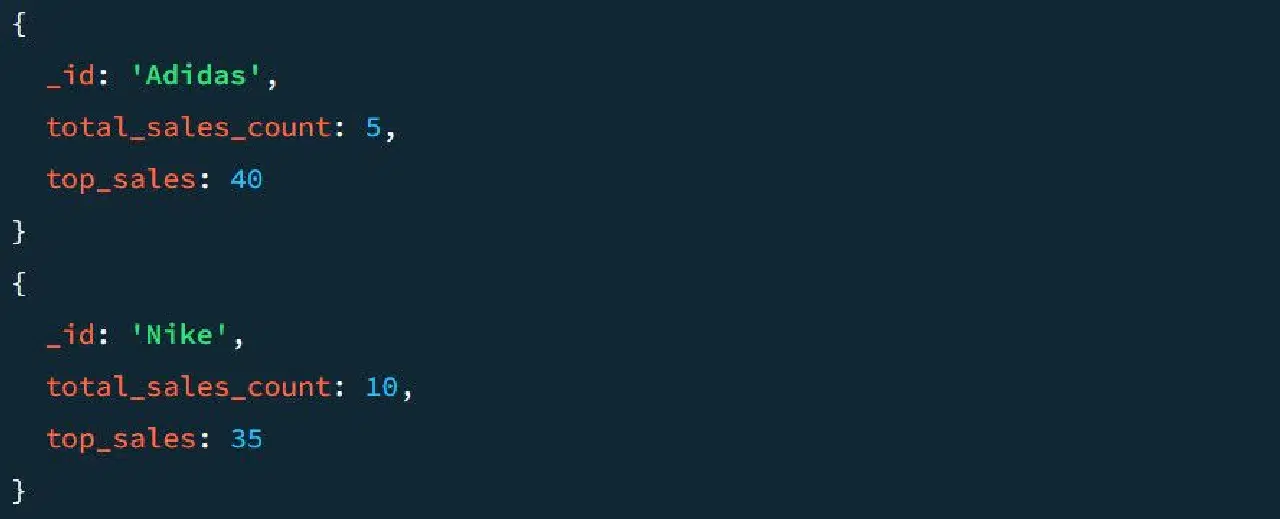
이제 $project 단계를 적용하여 어떻게 달라지는지 살펴보겠습니다. $project를 파이프라인에 추가하는 방법은 다음과 같습니다.
...,
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
이전 단계에서 제품 섹션을 기준으로 데이터를 그룹화했으므로, 위의 출력 문서에는 각 제품 섹션에 대한 정보가 포함됩니다. 또한 집계된 판매량과 최대 판매량이 TotalSold 및 TopSale로 출력되도록 지정합니다.
최종 출력은 이전 출력보다 훨씬 깔끔해졌습니다.

$unwind 단계
$unwind 단계는 문서 내의 배열을 개별 문서로 분해합니다. 예를 들어, 다음 주문 데이터를 살펴보겠습니다.
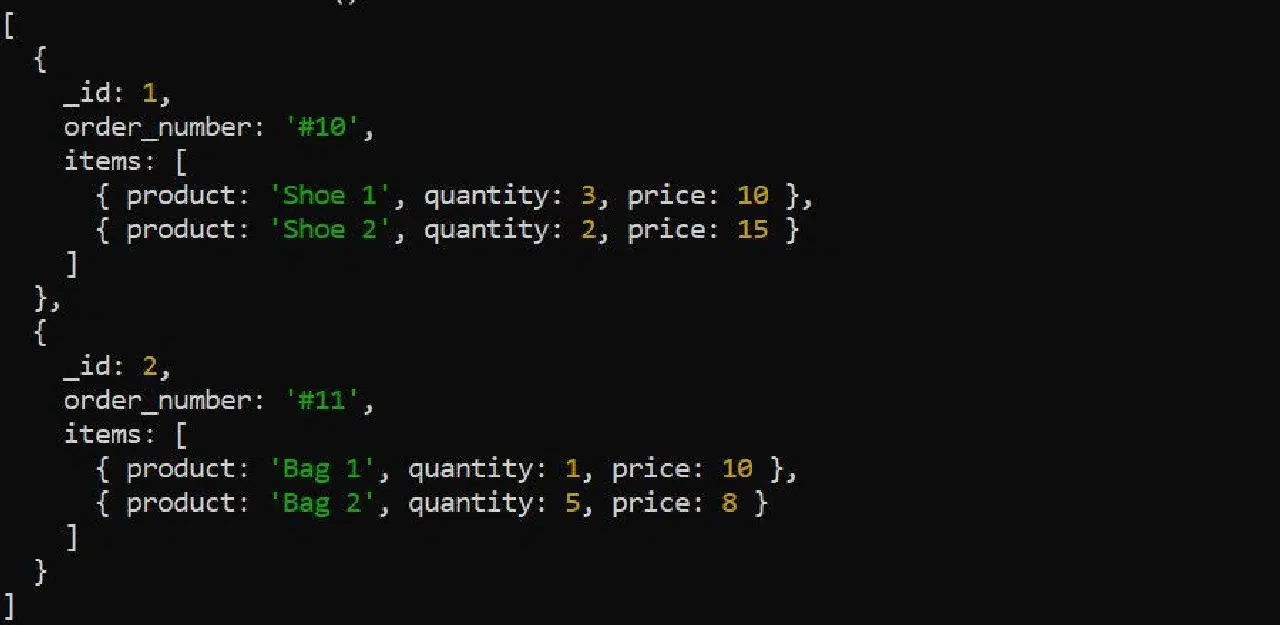
다른 집계 단계를 적용하기 전에 $unwind 단계를 사용하여 항목 배열을 분해합니다. 예를 들어 각 제품별 총 수익을 계산하려는 경우, 항목 배열을 푸는 것이 적합합니다.
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},
{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",
}
}
])
위 집계 쿼리의 결과는 다음과 같습니다.

MongoDB에서 집계 파이프라인 생성 방법
집계 파이프라인은 여러 단계를 거치지만, 이전 단계에서 각 단계를 파이프라인에 적용하는 방법을 설명함으로써, 기본적인 쿼리를 포함하여 파이프라인 구축 방법을 이해하는 데 도움이 되었기를 바랍니다.
이전 판매 데이터 샘플을 사용하여 위에서 설명한 몇 가지 단계를 결합하여 집계 파이프라인을 더 폭넓게 살펴보겠습니다.
db.sales.aggregate([
{
"$match": {
"Sold": { "$gte": 5 }
}
},
{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}
},
{
"$sort": { "top_sales": -1 }
},
{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",
}
}
])
최종 출력은 앞서 살펴본 것과 유사합니다.
집계 파이프라인과 MapReduce 비교
MongoDB 5.0 이전에는 MapReduce가 MongoDB에서 데이터를 집계하는 주요 방법으로 사용되었습니다. MapReduce는 MongoDB 외에도 다양한 환경에서 폭넓게 사용될 수 있지만, 집계 파이프라인보다 효율성이 떨어집니다. Map과 Reduce 함수를 별도로 작성하려면 추가적인 스크립트 작성이 필요합니다.
반면에 집계 파이프라인은 MongoDB에 특화되어 있지만, 복잡한 쿼리를 수행하는 더 효율적인 방법을 제공합니다. 단순성과 쿼리 확장성뿐만 아니라, 주요 파이프라인 단계를 통해 결과를 쉽게 사용자 정의할 수 있다는 장점도 있습니다.
집계 파이프라인과 MapReduce 사이에는 더 많은 차이점이 있으며, MapReduce에서 집계 파이프라인으로 전환하면 그 차이를 체감할 수 있습니다.
MongoDB에서 빅 데이터 쿼리를 효율적으로 실행하는 방법
MongoDB에서 복잡한 데이터에 대한 심층적인 계산을 수행하려면 쿼리가 최대한 효율적으로 실행되어야 합니다. 집계 파이프라인은 고급 쿼리를 실행하는 데 매우 적합합니다. 데이터를 별도의 연산으로 조작하는 대신, 집계를 사용하면 모든 데이터를 단일 파이프라인 내에서 처리하고 한 번에 실행할 수 있으므로 성능을 크게 향상시킬 수 있습니다.
집계 파이프라인은 MapReduce보다 효율적이지만, 데이터에 인덱스를 적용하면 집계 성능을 더욱 향상시킬 수 있습니다. 이는 MongoDB가 각 집계 단계에서 스캔해야 하는 데이터 양을 줄여주기 때문입니다.