
df 및 du 명령은 Linux, macOS 및 기타 많은 Unix 계열 운영 체제에서 사용되는 Bash 셸 내에서 디스크 공간 사용량을 보고합니다. 이 명령을 사용하면 시스템의 스토리지를 사용하고 있는 항목을 쉽게 식별할 수 있습니다.
총, 사용 가능한 디스크 공간 및 사용된 디스크 공간 보기
Bash에는 디스크 공간과 관련된 두 가지 유용한 명령이 포함되어 있습니다. 사용 가능한 디스크 공간과 사용된 디스크 공간을 찾으려면 df(디스크 파일 시스템, 디스크 여유 공간이라고도 함)를 사용하십시오. 사용된 디스크 공간을 차지하는 항목을 찾으려면 du(디스크 사용량)를 사용하십시오.
시작하려면 df를 입력하고 Bash 터미널 창에서 Enter 키를 누릅니다. 아래 스크린샷과 유사한 출력이 많이 표시됩니다. 옵션 없이 df를 사용하면 마운트된 모든 파일 시스템에 사용 가능한 공간과 사용 공간이 표시됩니다. 얼핏 보면 이해가 안 될 것 같지만, 의외로 이해하기 쉽습니다.
df
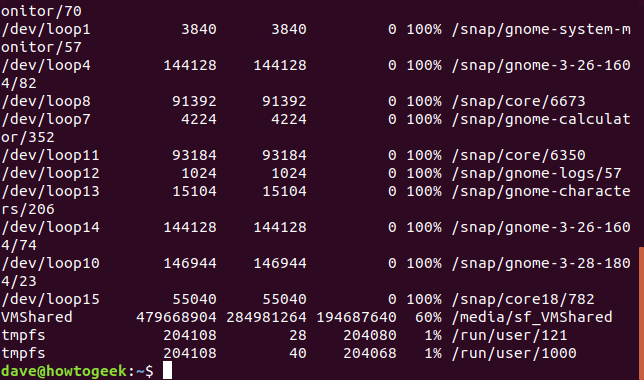
디스플레이의 각 라인은 6개의 열로 구성됩니다.
Fileystem: 이 파일 시스템의 이름입니다.
1K-Blocks: 이 파일 시스템에서 사용할 수 있는 1K 블록 수입니다.
사용됨: 이 파일 시스템에서 사용된 1K 블록의 수입니다.
사용 가능: 이 파일 시스템에서 사용되지 않는 1K 블록 수입니다.
Use%: 이 파일 시스템에서 사용된 공간의 양을 백분율로 표시합니다.
파일: 명령줄에 지정된 경우 파일 시스템 이름입니다.
마운트 위치: 파일 시스템의 마운트 지점입니다.
-B(블록 크기) 옵션을 사용하여 1K 블록 수를 보다 유용한 출력으로 바꿀 수 있습니다. 이 옵션을 사용하려면 df, 공백, -B 및 K, M, G, T, P, E, Z 또는 Y 목록의 문자를 입력합니다. 이러한 문자는 킬로, 메가, 기가, 테라, 1024 스케일의 배수에서 페타, 엑사, 제타 및 요타 값.
예를 들어, 메가바이트 단위의 디스크 사용량 수치를 보려면 다음 명령을 사용합니다. B와 M 사이에는 공백이 없습니다.
df -BM
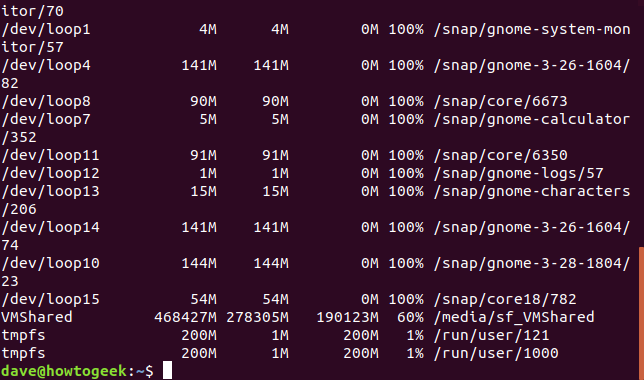
-h(사람이 읽을 수 있음) 옵션은 df가 각 파일 시스템의 크기에 가장 적합한 단위를 사용하도록 지시합니다. 다음 출력에는 기가바이트, 메가바이트 및 킬로바이트 크기의 파일 시스템이 있습니다.
df -h

inode의 수로 표시된 정보를 확인해야 하는 경우 -i(inode) 옵션을 사용합니다. inode는 Linux 파일 시스템에서 파일을 설명하고 파일에 대한 메타데이터를 저장하는 데 사용하는 데이터 구조입니다. Linux에서 inode는 각 파일 및 디렉토리에 대한 이름, 수정 날짜, 하드 드라이브의 위치 등과 같은 데이터를 보유합니다. 이것은 대부분의 사람들에게 유용하지 않을 것이지만 시스템 관리자는 때때로 이러한 유형의 정보를 참조해야 합니다.
df -i
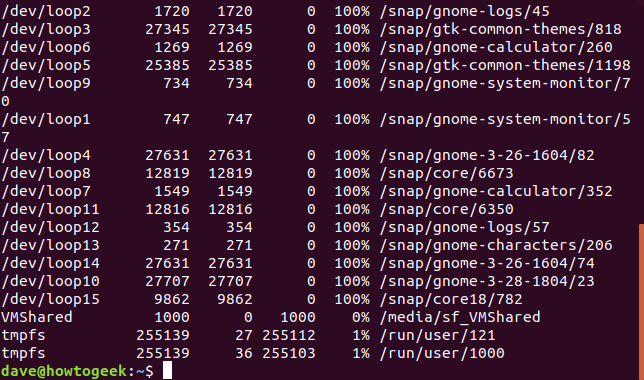
그렇지 않은 경우 df는 마운트된 모든 파일 시스템에 대한 정보를 제공합니다. 이로 인해 출력이 많아 디스플레이가 복잡해질 수 있습니다. 예를 들어, 목록의 /dev/loop 항목은 마치 파티션인 것처럼 파일을 마운트할 수 있는 의사 파일 시스템입니다. 응용 프로그램을 설치하는 새로운 Ubuntu 스냅 방법을 사용하면 이러한 응용 프로그램을 많이 얻을 수 있습니다. 이것들에서 사용 가능한 공간은 실제로 파일 시스템이 아니기 때문에 항상 0이므로 볼 필요가 없습니다.
특정 유형의 파일 시스템을 제외하도록 df에 지시할 수 있습니다. 그렇게 하려면 제외하려는 파일 시스템의 유형을 알아야 합니다. -T(인쇄 유형) 옵션은 해당 정보를 제공합니다. 출력에 파일 시스템 유형을 포함하도록 df에 지시합니다.
df -T

/dev/loop 항목은 모두 squashfs 파일 시스템입니다. 다음 명령으로 제외할 수 있습니다.
df -x squashfs

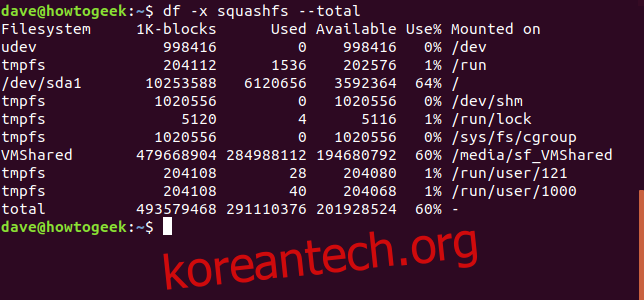
그것은 우리에게 더 관리하기 쉬운 출력을 제공합니다. 합계를 얻으려면 –total 옵션을 추가할 수 있습니다.
df -x squashfs --total
-t(유형) 옵션을 사용하여 df에 특정 유형의 파일 시스템만 포함하도록 요청할 수 있습니다.
df -t ext4

파일 시스템 세트의 크기를 보려면 이름으로 지정할 수 있습니다. Linux의 드라이브 이름은 알파벳순입니다. 첫 번째 드라이브는 /dev/sda, 두 번째 드라이브는 /dev/sdb 등입니다. 파티션에 번호가 매겨져 있습니다. 따라서 /dev/sda1 은 /dev/sda 드라이브의 첫 번째 파티션입니다. 파일 시스템의 이름을 명령 매개변수로 전달하여 특정 파일 시스템에 대한 정보를 반환하도록 df에 지시합니다. 첫 번째 하드 드라이브의 첫 번째 파티션을 살펴보겠습니다.
df /dev/sda1

파일 시스템 이름에 와일드카드를 사용할 수 있습니다. 여기서 *는 임의의 문자 집합을 나타내고 ? 단일 문자를 나타냅니다. 따라서 첫 번째 드라이브의 모든 파티션을 보려면 다음을 사용할 수 있습니다.
df /dev/sda*
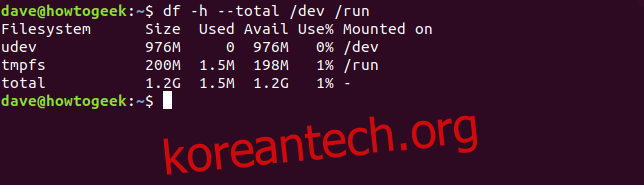
명명된 파일 시스템 집합에 대해 보고하도록 df에 요청할 수 있습니다. 그는 우리가 /dev 및 /run 파일 시스템의 크기를 요청하고 있으며 총계를 원합니다.
df -h --total /dev /run
디스플레이를 추가로 사용자 정의하기 위해 포함할 열을 df에 알릴 수 있습니다. 이렇게 하려면 –output 옵션을 사용하고 필수 열 이름의 쉼표로 구분된 목록을 제공하십시오. 쉼표로 구분된 목록에 공백을 포함하지 않도록 하십시오.
소스: 파일 시스템의 이름.
fstype: 파일 시스템의 유형입니다.
itotal: inode에 있는 파일 시스템의 크기입니다.
사용됨: inode에서 파일 시스템에 사용된 공간입니다.
iavail: inode의 파일 시스템에서 사용 가능한 공간입니다.
ipcent: inode의 파일 시스템에서 사용된 공간의 백분율(백분율)입니다.
크기: 기본적으로 1K 블록 단위의 파일 시스템 크기입니다.
used: 파일 시스템에서 사용되는 공간으로 기본적으로 1K 블록 단위입니다.
avail: 기본적으로 1K 블록 단위의 파일 시스템에서 사용 가능한 공간입니다.
pcent: 기본적으로 1K 블록 단위의 inode 단위 파일 시스템에서 사용된 공간의 백분율입니다.
file: 명령줄에 지정된 경우 파일 시스템 이름입니다.
target: 파일 시스템의 마운트 지점입니다.
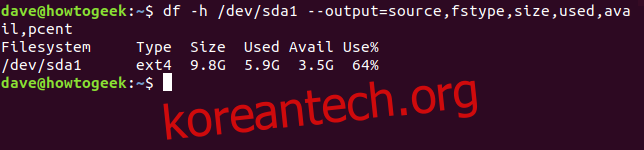
사람이 읽을 수 있는 숫자와 소스, fstype, size, used, avail, pcent 열을 사용하여 첫 번째 드라이브의 첫 번째 파티션에 대해 보고하도록 df에 요청해 보겠습니다.
df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent
긴 명령은 별칭으로 전환하기에 완벽한 후보입니다. 다음을 입력하고 Enter 키를 눌러 별칭 dfc( df custom )를 만들 수 있습니다.
alias dfc="df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent"
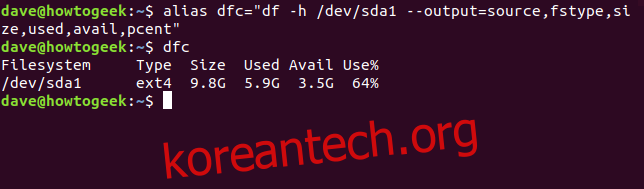
dfc를 입력하고 Enter 키를 누르면 긴 명령을 입력하는 것과 같은 효과가 나타납니다. 이 별명을 영구적으로 만들려면 .bashrc 또는 .bash_aliases 파일에 추가하십시오.
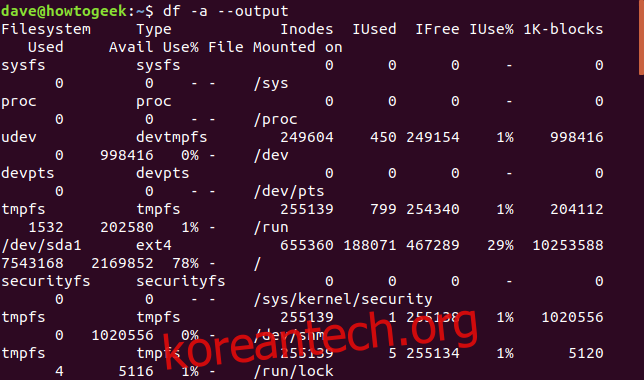
우리는 df가 표시하는 정보가 요구 사항과 일치하도록 df의 출력을 개선하는 방법을 찾고 있습니다. 반대 접근 방식을 취하고 df가 모든 정보를 반환하도록 하려면 아래와 같이 -a(all) 옵션과 –output 옵션을 사용할 수 있습니다. -a(all) 옵션은 df에 모든 파일 시스템을 포함하도록 요청하고 쉼표로 구분된 열 목록 없이 –output 옵션을 사용하면 df가 모든 열을 포함합니다.
df -a --output
less 명령을 통해 df의 출력을 파이프하는 것은 이것이 생성할 수 있는 많은 양의 출력을 검토하는 편리한 방법입니다.
df -a --output | less
사용된 디스크 공간을 차지하는 항목 찾기
조사를 하고 이 PC의 공간을 차지하는 것이 무엇인지 알아보겠습니다. df 명령 중 하나부터 시작하겠습니다.
df -h -t ext4

첫 번째 하드 드라이브의 첫 번째 파티션에 78%의 디스크 공간이 사용되었습니다. du 명령을 사용하여 가장 많은 데이터를 보유하고 있는 폴더를 표시할 수 있습니다. 옵션 없이 du 명령을 실행하면 du 명령이 실행된 디렉터리 아래의 모든 디렉터리와 하위 디렉터리 목록이 표시됩니다. 홈 폴더에서 이 작업을 수행하면 목록이 매우 길어집니다.
du

출력 형식은 매우 간단합니다. 각 줄은 디렉토리의 크기와 이름을 보여줍니다. 기본적으로 크기는 1K 블록으로 표시됩니다. du가 다른 블록 크기를 사용하도록 하려면 -B(블록 크기) 옵션을 사용하십시오. 이 옵션을 사용하려면 위에서 df에 대해 수행한 것처럼 du, 공백, -B 및 K, M, G, T, P, E, Z 및 Y 목록의 문자를 입력합니다. 1M 블록을 사용하려면 다음 명령을 사용하십시오.
du -BM

df와 마찬가지로 du에는 사람이 읽을 수 있는 옵션인 -h가 있습니다. 이 옵션은 각 디렉토리의 크기에 따라 다양한 블록 크기를 사용합니다.
du -h

-s(요약) 옵션은 각 디렉토리 내의 하위 디렉토리를 표시하지 않고 각 디렉토리에 대한 합계를 제공합니다. 다음 명령은 du에게 모든 디렉토리에 대해 사람이 읽을 수 있는 숫자로 요약 형식의 정보를 반환하도록 요청합니다.
du -h -s *

현재 작업 디렉토리 아래에 있습니다.
du -sm Pictures/* | sort -nr

Picture 폴더는 지금까지 가장 많은 데이터를 보유하고 있습니다. 우리는 du에게 폴더 크기를 가장 큰 것부터 작은 것 순으로 정렬하도록 요청할 수 있습니다.
df 및 du에서 반환된 정보를 수정하면 사용 중인 하드 디스크 공간의 양과 해당 공간을 차지하는 것이 무엇인지 쉽게 알 수 있습니다. 그런 다음 일부 데이터를 다른 저장소로 이동하거나 컴퓨터에 다른 하드 드라이브를 추가하거나 중복 데이터를 삭제하는 것에 대해 정보에 입각한 결정을 내릴 수 있습니다. 이러한 명령에는 많은 옵션이 있습니다. 여기에서 가장 유용한 옵션에 대해 설명했지만 해당 옵션의 전체 목록을 볼 수 있습니다. df 명령 그리고 위해 뒤 명령
Linux 매뉴얼 페이지에서.