`df` 및 `du` 명령어는 Linux, macOS 및 다양한 Unix 계열 운영체제에서 Bash 셸 환경 내에서 디스크 공간 사용량을 파악하는 데 사용됩니다. 이러한 명령들을 통해 시스템의 저장 공간을 점유하고 있는 항목들을 쉽게 확인하고 관리할 수 있습니다.
총 디스크 공간, 사용 가능한 공간 및 사용 중인 공간 확인하기
Bash 셸에는 디스크 공간 관련 정보를 제공하는 두 가지 핵심 명령어가 있습니다.
`df`(디스크 파일 시스템) 명령어는 사용 가능한 디스크 공간과 사용된 공간을 확인하는 데 사용됩니다.
반면, `du`(디스크 사용량) 명령어는 디스크 공간을 실제로 점유하고 있는 항목들을 찾는 데 활용됩니다.
먼저, Bash 터미널에서 `df` 명령어를 입력하고 Enter 키를 누르면, 현재 시스템에 마운트된 모든 파일 시스템의 사용 가능 공간과 사용 중인 공간에 대한 정보가 표시됩니다.
이러한 정보는 처음에는 복잡해 보일 수 있지만, 자세히 살펴보면 쉽게 이해할 수 있습니다.
df
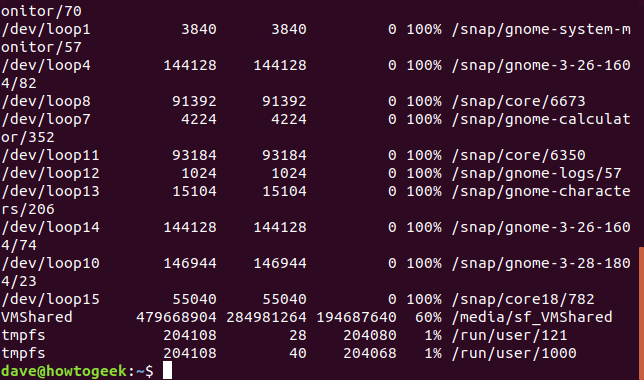
표시되는 각 행은 6개의 열로 구성되어 있으며, 각 열은 다음과 같은 정보를 제공합니다.
Fileystem: 해당 파일 시스템의 이름입니다.
1K-Blocks: 해당 파일 시스템에서 사용 가능한 1KB 블록의 총 개수입니다.
사용됨: 해당 파일 시스템에서 현재 사용 중인 1KB 블록의 개수입니다.
사용 가능: 해당 파일 시스템에서 아직 사용되지 않은 1KB 블록의 개수입니다.
Use%: 해당 파일 시스템에서 사용 중인 공간의 비율을 백분율로 나타냅니다.
파일: 명령줄에서 특정 파일 시스템이 지정된 경우 해당 파일 시스템 이름입니다.
마운트 위치: 해당 파일 시스템이 마운트된 경로입니다.
`-B`(블록 크기) 옵션을 사용하여 1KB 단위의 블록 수를 다른 단위로 변경하여 보다 이해하기 쉬운 형태로 출력할 수 있습니다. 예를 들어, 메가바이트 단위로 디스크 사용량을 확인하고 싶다면 `df -BM` 명령어를 사용할 수 있습니다. `B`와 `M` 사이에는 공백이 없어야 합니다.
df -BM
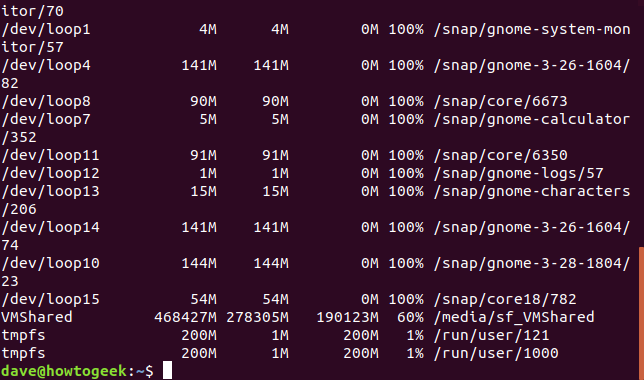
`-h`(사람이 읽을 수 있는) 옵션을 사용하면 `df` 명령어가 각 파일 시스템의 크기에 따라 가장 적합한 단위를 자동으로 선택하여 표시합니다.
이 옵션을 사용하면 기가바이트, 메가바이트, 킬로바이트 등 다양한 단위로 혼합된 결과를 편리하게 확인할 수 있습니다.
df -h

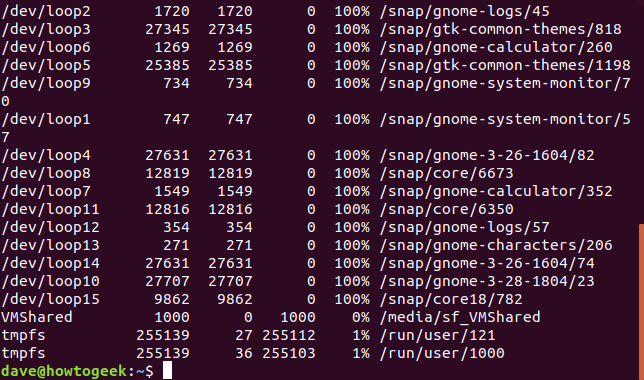
`-i`(inode) 옵션은 파일 시스템의 inode 정보를 확인하는 데 사용됩니다.
inode는 파일 시스템 내에서 파일이나 디렉토리를 관리하기 위한 메타데이터를 저장하는 데이터 구조입니다.
일반 사용자에게는 유용하지 않을 수 있지만, 시스템 관리자는 이러한 정보를 참조해야 할 때가 있습니다.
df -i
`df` 명령어는 기본적으로 마운트된 모든 파일 시스템에 대한 정보를 제공하므로 출력 결과가 매우 길어질 수 있습니다.
예를 들어, `/dev/loop` 항목은 파일 시스템처럼 마운트될 수 있는 의사 파일 시스템으로, snap 패키지를 설치하면 이러한 항목들이 많이 나타납니다.
이러한 항목들은 실제 파일 시스템이 아니므로 사용 가능한 공간이 항상 0으로 표시되어 불필요할 수 있습니다.
`-T`(인쇄 유형) 옵션을 사용하여 출력 결과에 파일 시스템의 유형을 포함시키면, 특정 유형의 파일 시스템을 제외하는 것이 가능합니다.
예를 들어, `/dev/loop` 항목들은 모두 `squashfs` 파일 시스템이므로, `df -x squashfs` 명령어를 사용하여 이를 제외할 수 있습니다.
df -T

df -x squashfs

이렇게 하면 보다 관리하기 쉬운 결과를 얻을 수 있습니다.
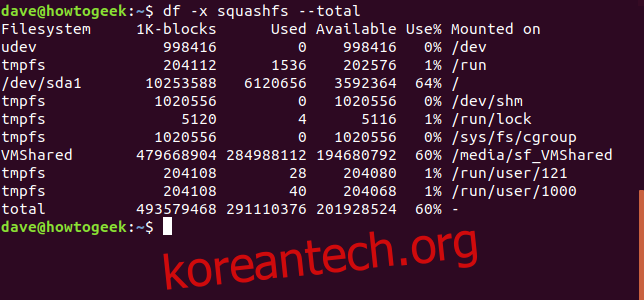
전체 합계를 보고 싶다면, `–total` 옵션을 추가하여 모든 파일 시스템의 총 사용량과 여유 공간을 확인할 수 있습니다.
df -x squashfs --total
반대로, `-t`(유형) 옵션을 사용하여 특정 파일 시스템 유형만 포함하도록 할 수도 있습니다. 예를 들어, `ext4` 파일 시스템만 보고 싶다면 `df -t ext4` 명령어를 사용합니다.
df -t ext4

특정 파일 시스템 집합의 크기를 확인하기 위해 파일 시스템 이름을 직접 지정할 수 있습니다.
Linux에서 드라이브 이름은 일반적으로 알파벳 순서대로 지정되며, 첫 번째 드라이브는 `/dev/sda`, 두 번째 드라이브는 `/dev/sdb` 등으로 표시됩니다.
파티션은 숫자로 구분되므로 `/dev/sda1`은 `/dev/sda` 드라이브의 첫 번째 파티션을 의미합니다.
`df` 명령어에 특정 파일 시스템 이름을 매개변수로 전달하면 해당 파일 시스템에 대한 정보를 얻을 수 있습니다.
예를 들어, 첫 번째 하드 드라이브의 첫 번째 파티션 정보를 확인하려면 `df /dev/sda1` 명령어를 사용합니다.
df /dev/sda1

파일 시스템 이름에 와일드카드를 사용하여 여러 파일 시스템에 대한 정보를 한 번에 확인할 수도 있습니다.
`*`는 임의의 문자 집합을 나타내고 `?`는 단일 문자를 나타냅니다. 예를 들어, 첫 번째 드라이브의 모든 파티션을 보려면 `df /dev/sda*` 명령어를 사용할 수 있습니다.
df /dev/sda*
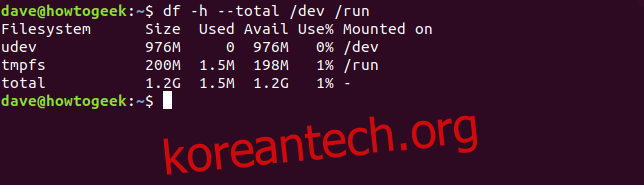
`/dev` 및 `/run` 파일 시스템의 크기를 합계와 함께 확인하려면 다음과 같은 명령어를 사용합니다.
df -h --total /dev /run
출력 결과를 보다 세밀하게 제어하려면 `–output` 옵션을 사용하여 원하는 열만 선택하여 표시할 수 있습니다. 필요한 열 이름을 쉼표로 구분하여 지정할 수 있습니다.
쉼표로 구분된 목록에는 공백을 포함하지 않도록 주의해야 합니다.
다음은 `–output` 옵션에서 사용할 수 있는 열 이름과 그 의미입니다.
source: 파일 시스템의 이름입니다.
fstype: 파일 시스템의 유형입니다.
itotal: inode에서 파일 시스템의 총 크기입니다.
used: inode에서 파일 시스템에서 사용 중인 공간입니다.
iavail: inode에서 파일 시스템에서 사용 가능한 공간입니다.
ipcent: inode에서 파일 시스템에서 사용 중인 공간의 비율입니다.
size: 기본적으로 1K 블록 단위의 파일 시스템 크기입니다.
used: 기본적으로 1K 블록 단위의 파일 시스템에서 사용 중인 공간입니다.
avail: 기본적으로 1K 블록 단위의 파일 시스템에서 사용 가능한 공간입니다.
pcent: 기본적으로 1K 블록 단위의 파일 시스템에서 사용 중인 공간의 비율입니다.
file: 명령줄에서 지정된 경우 파일 시스템 이름입니다.
target: 파일 시스템의 마운트 지점입니다.
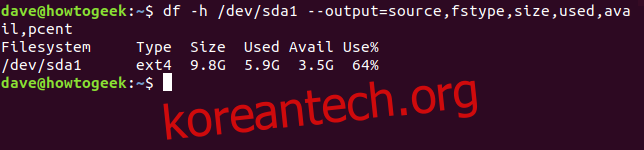
예를 들어, 사람이 읽기 쉬운 형식으로 첫 번째 드라이브의 첫 번째 파티션에 대한 소스, 파일 시스템 유형, 크기, 사용 공간, 사용 가능 공간, 사용 비율 정보를 확인하려면 다음 명령어를 사용합니다.
df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent
자주 사용하는 긴 명령은 별칭으로 만들어서 편리하게 사용할 수 있습니다.
예를 들어, 위에서 사용한 `df` 명령어를 `dfc`라는 별칭으로 만들려면 다음 명령어를 입력합니다.
alias dfc="df -h /dev/sda1 --output=source,fstype,size,used,avail,pcent"
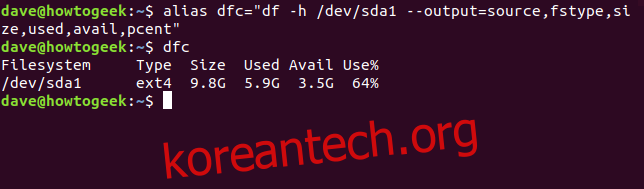
이제 `dfc`를 입력하고 Enter 키를 누르면 긴 명령어를 입력한 것과 동일한 결과를 얻을 수 있습니다. 이 별칭을 영구적으로 사용하려면 `~/.bashrc` 또는 `~/.bash_aliases` 파일에 추가해야 합니다.
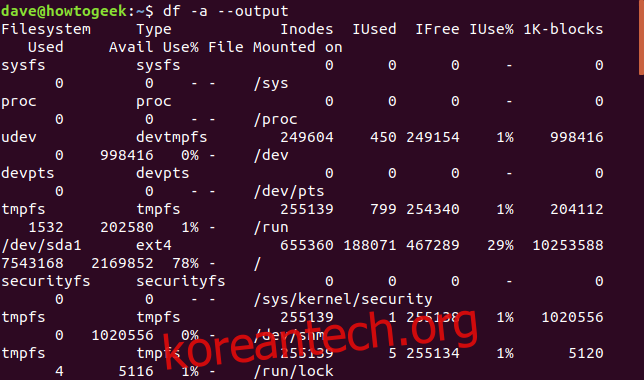
필요에 따라 `df` 명령어의 출력을 사용자 정의하여 원하는 정보를 표시할 수 있습니다. 반대로, 모든 정보를 출력하고 싶다면 `-a`(all) 옵션과 함께 `–output` 옵션을 사용하면 됩니다.
`-a` 옵션은 모든 파일 시스템을 포함하도록 하고, `–output` 옵션에 열 이름을 지정하지 않으면 모든 열이 표시됩니다.
df -a --output
`less` 명령어를 사용하여 `df` 명령어의 출력을 파이프하면 많은 양의 결과를 편리하게 검토할 수 있습니다.
df -a --output | less
사용된 디스크 공간을 차지하는 항목 찾기
이제, 실제로 디스크 공간을 많이 사용하고 있는 항목이 무엇인지 알아보겠습니다.
먼저, 위에서 사용한 `df` 명령어를 사용하여 첫 번째 하드 드라이브 파티션의 사용률을 확인해 보겠습니다.
df -h -t ext4

위의 결과에서 첫 번째 하드 드라이브의 첫 번째 파티션이 78%나 사용되고 있음을 확인할 수 있습니다.
이제 `du` 명령어를 사용하여 어떤 폴더가 가장 많은 데이터를 차지하고 있는지 확인해 보겠습니다.
`du` 명령어를 옵션 없이 실행하면 현재 디렉터리 아래의 모든 디렉터리와 하위 디렉터리 목록이 표시됩니다.
만약 홈 폴더에서 `du` 명령어를 실행하면 결과가 매우 길어질 수 있습니다.
du

`du` 명령어의 출력 형식은 매우 간단하며, 각 행은 디렉토리의 크기와 이름을 보여줍니다.
기본적으로 크기는 1KB 블록 단위로 표시됩니다.
`du` 명령어가 다른 블록 크기를 사용하도록 하려면 `-B`(블록 크기) 옵션을 사용하십시오.
예를 들어, 1MB 블록 단위를 사용하려면 `du -BM` 명령어를 사용합니다.
du -BM

`df` 명령어와 마찬가지로 `du` 명령어에도 사람이 읽을 수 있는 옵션인 `-h`가 있습니다.
이 옵션은 각 디렉토리의 크기에 따라 다양한 블록 크기를 사용하여 결과를 표시합니다.
du -h

`-s`(요약) 옵션은 각 디렉토리 내의 하위 디렉토리를 표시하지 않고 각 디렉토리에 대한 총 크기만 표시합니다.
다음 명령어는 현재 디렉터리에 있는 모든 디렉토리에 대해 사람이 읽을 수 있는 형식으로 요약된 정보를 요청합니다.
du -h -s *

특정 디렉토리 내의 폴더들을 크기 순으로 정렬하여 확인하고 싶다면 다음과 같은 명령어를 사용할 수 있습니다.
예를 들어, “Pictures” 폴더 내의 하위 폴더들을 크기 순으로 정렬하여 확인하려면 다음과 같은 명령어를 사용합니다.
du -sm Pictures/* | sort -nr

`du` 명령어와 `sort` 명령어를 함께 사용하면 특정 폴더 내에서 가장 큰 폴더를 쉽게 식별할 수 있습니다.
`df` 및 `du` 명령어를 통해 얻은 정보를 바탕으로, 사용 중인 하드 디스크 공간의 양과 해당 공간을 차지하는 항목을 쉽게 파악할 수 있습니다.
이를 통해 데이터를 다른 저장소로 이동하거나, 하드 드라이브를 추가하거나, 중복된 데이터를 삭제하는 등의 정보에 근거한 결정을 내릴 수 있습니다.
`df` 및 `du` 명령어에는 다양한 옵션이 있습니다. 여기서는 가장 유용한 옵션들을 소개했지만, 매뉴얼 페이지에서 전체 옵션 목록을 확인할 수 있습니다.
`df` 명령어에 대한 자세한 내용은 여기, `du` 명령어에 대한 자세한 내용은 여기에서 확인하세요.
Linux 매뉴얼 페이지를 참고하세요.