Linux에서 vmstat 명령을 사용하는 방법
Linux나 macOS를 사용하는 컴퓨터는 가상 메모리라는 특별한 기능을 활용합니다. 이 기능이 컴퓨터의 물리적 메모리, CPU, 하드 디스크 자원 사용에 어떤 영향을 주는지 자세히 알아보겠습니다.
가상 메모리란 무엇일까요?
컴퓨터에는 RAM (랜덤 액세스 메모리)이라는 중요한 부품이 있습니다. 이 RAM은 운영체제의 핵심인 커널에 의해 관리되며, 운영체제 자체와 실행 중인 모든 응용 프로그램이 함께 사용합니다. 만약 컴퓨터에 실제로 설치된 RAM 용량보다 더 많은 메모리가 필요한 상황이 발생하면, 커널은 어떻게 대처할까요?
Linux나 macOS와 같은 Unix 계열 운영체제에서는 하드 디스크의 저장 공간을 활용하여 메모리 부족 문제를 해결할 수 있습니다. 하드 드라이브의 특정 영역을 "스왑 공간"으로 지정하여 마치 RAM의 확장처럼 사용합니다. 이것이 바로 가상 메모리입니다.
Linux 커널은 메모리 블록의 데이터를 스왑 공간에 저장하고, RAM 공간을 확보하여 다른 프로세스에서 사용할 수 있도록 합니다. 이를 "스왑 아웃" 또는 "페이지 아웃"이라고 하며, 필요할 때는 스왑 공간에서 데이터를 가져와 RAM으로 다시 복원합니다.
물론, 스왑 아웃된 메모리에 접근하는 속도는 RAM에 저장된 메모리보다 느립니다. 이것 외에도 고려해야 할 다른 요소들이 있습니다. 가상 메모리는 Linux가 메모리 요구를 관리하는 데 도움이 되지만, 동시에 컴퓨터의 다른 부분에 부담을 주기도 합니다.
하드 드라이브는 더 많은 읽기/쓰기 작업을 처리해야 하고, 커널(따라서 CPU)도 메모리 교체 작업과 다른 프로세스의 메모리 요구를 처리하기 위해 더 많은 일을 해야 합니다. 즉, 컴퓨터 전체가 더 많은 자원을 소모하게 됩니다.
Linux에서는 `vmstat` 명령을 통해 이러한 모든 활동을 모니터링할 수 있습니다. 이는 가상 메모리 통계를 제공하는 도구입니다.
`vmstat` 명령어 활용법
`vmstat` 명령어를 매개변수 없이 실행하면 컴퓨터가 마지막으로 재부팅된 이후의 평균적인 통계 값들이 표시됩니다. 현재 시점의 정확한 스냅샷이 아니라 평균적인 수치임을 기억해야 합니다.
vmstat

결과로 짧은 표가 나타납니다.
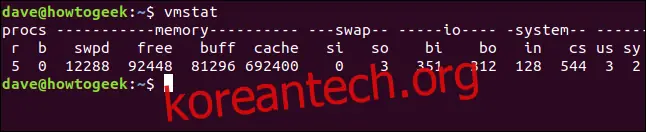
표는 Procs, Memory, Swap, IO, System, CPU의 6개 열로 구성되어 있습니다. 가장 오른쪽 열에는 CPU 관련 데이터가 포함되어 있습니다.
각 열에 대한 데이터 항목은 다음과 같습니다.
Procs
r: 현재 실행 중이거나 CPU 사용 시간을 기다리는 실행 가능한 프로세스의 수입니다.
b: 중단 없이 휴면 상태에 있는 프로세스의 수입니다. 이러한 프로세스는 특정 작업 완료를 기다리며, 보통 장치 드라이버가 리소스를 해제하기를 기다립니다.
Memory
swpd: 현재 사용 중인 가상 메모리의 양, 즉 스왑 아웃된 메모리의 양입니다.
free: 사용되지 않는 유휴 메모리의 양입니다.
buff: 버퍼로 사용되는 메모리의 양입니다.
cache: 캐시로 사용되는 메모리의 양입니다.
Swap
si: 스왑 공간에서 RAM으로 스왑된 가상 메모리의 양입니다.
so: RAM에서 스왑 공간으로 스왑 아웃된 가상 메모리의 양입니다.
IO
bi: 블록 장치에서 받은 데이터 블록 수, 즉 가상 메모리가 RAM으로 스왑될 때 사용되는 데이터 블록 수입니다.
bo: 블록 장치로 전송된 데이터 블록 수, 즉 가상 메모리가 RAM에서 스왑 공간으로 스왑될 때 사용되는 데이터 블록 수입니다.
System
in: 초당 인터럽트 수, 클럭 인터럽트도 포함됩니다.
cs: 초당 컨텍스트 전환 횟수입니다. 컨텍스트 전환은 커널이 시스템 모드 처리에서 사용자 모드 처리로 변경될 때 발생합니다.
CPU
CPU 사용 시간은 백분율로 표시됩니다.
us: 커널 코드가 아닌 사용자 코드를 실행하는 데 소요된 시간입니다.
sy: 커널 코드를 실행하는 데 소요된 시간입니다.
id: CPU가 유휴 상태로 보낸 시간입니다.
wa: 입출력 작업이 완료되기를 기다리는 데 소요된 시간입니다.
st: 가상 머신 환경에서 다른 가상 머신에 의해 CPU 시간이 도난당한 시간입니다.
시간 간격을 설정하여 실시간 모니터링하기
지연 값을 지정하여 `vmstat`가 정기적으로 수치를 업데이트하도록 설정할 수 있습니다. 지연 값은 초 단위로 입력합니다. 예를 들어, 5초마다 통계를 업데이트하려면 다음 명령을 사용합니다.
vmstat 5

이제 `vmstat`는 5초마다 새로운 데이터 행을 표에 추가합니다. 이 과정을 중지하려면 Ctrl+C를 누르면 됩니다.
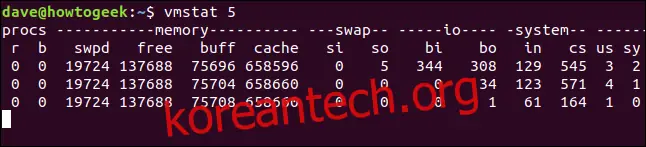
업데이트 횟수 지정하기
지나치게 짧은 지연 값은 시스템에 부담을 줄 수 있습니다. 문제 진단을 위해 빠른 업데이트가 필요하다면 지연 값과 함께 업데이트 횟수를 지정하는 것이 좋습니다.
업데이트 횟수는 `vmstat`가 종료되기 전까지 수행할 업데이트 횟수를 지정합니다. 이 값을 지정하지 않으면 Ctrl+C를 눌러 수동으로 중단해야 합니다.
예를 들어, `vmstat`가 5초마다 업데이트를 제공하도록 설정하고, 총 4번만 업데이트를 수행하려면 다음 명령을 사용합니다.
vmstat 5 4

4번의 업데이트 후 `vmstat`는 자동으로 종료됩니다.
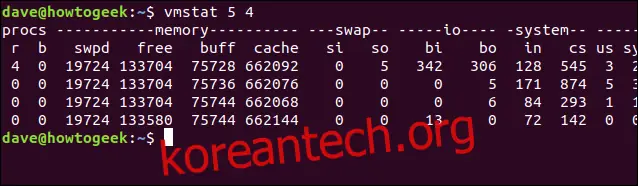
단위 변경하기
`-S` (단위 문자) 옵션을 사용하여 메모리 및 스왑 통계를 킬로바이트 또는 메가바이트 단위로 표시할 수 있습니다. `-S` 뒤에는 `k`, `K`, `m`, `M` 중 하나를 지정해야 하며, 각각 다음과 같은 단위를 나타냅니다.
k: 1000바이트
K: 1024바이트
m: 1000000바이트
M: 1048576바이트
예를 들어, 메모리 및 스왑 통계를 메가바이트 단위로 표시하고 10초마다 업데이트하려면 다음 명령을 사용합니다.
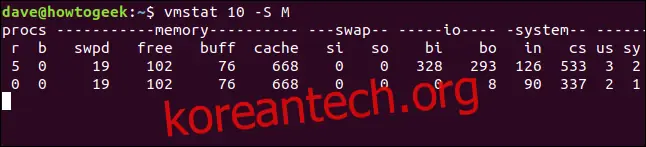
vmstat 10 -S M

이제 메모리 및 스왑 통계가 메가바이트 단위로 표시됩니다. `-S` 옵션은 IO 블록 통계에는 영향을 주지 않으며, 항상 블록 단위로 표시됩니다.
활성 및 비활성 메모리 확인
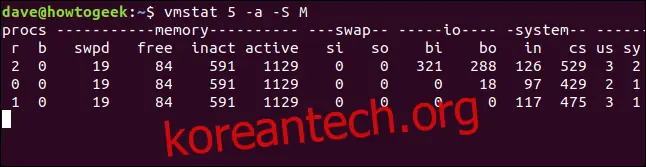
`-a` (활성) 옵션을 사용하면 버퍼 및 캐시 메모리 열이 "inact" 및 "active" 열로 대체됩니다. 이는 각각 비활성 및 활성 메모리의 양을 나타냅니다.
버퍼 및 캐시 열 대신 이 두 열을 표시하려면 다음과 같이 `-a` 옵션을 포함합니다.
vmstat 5 -a -S M

비활성 열과 활성 열은 `-S` (단위 문자) 옵션의 영향을 받습니다.
포크 수 확인
`-f` 스위치는 컴퓨터가 부팅된 이후 발생한 총 포크 수를 표시합니다.
이는 시스템이 부팅된 이후 시작된 (대부분의 경우 종료된) 작업의 수를 나타냅니다. 명령줄에서 시작된 모든 프로세스는 이 수치를 증가시킵니다. 작업이나 프로세스가 새로운 작업을 생성하거나 복제할 때마다 이 수치가 증가합니다.
vmstat -f

포크 수 표시는 업데이트되지 않습니다.
슬랩 정보 확인
커널은 운영체제와 모든 응용 프로그램의 메모리를 관리할 뿐만 아니라 자체적인 메모리 관리도 수행합니다.
커널은 다양한 유형의 데이터 객체에 대해 메모리를 할당하고 해제하는 작업을 지속적으로 수행합니다. 이러한 작업을 효율적으로 처리하기 위해 슬랩이라는 시스템을 사용합니다. 이는 일종의 캐싱 방식입니다.
특정 유형의 커널 데이터 객체에 할당되었다가 더 이상 필요하지 않은 메모리는 할당 해제 및 재할당 과정 없이, 동일한 유형의 다른 데이터 객체에 재사용될 수 있습니다. 슬랩을 커널 자체의 필요에 따라 미리 할당되고 관리되는 RAM 세그먼트라고 생각하면 됩니다.
슬랩 통계를 보려면 `-m` (슬랩) 옵션을 사용해야 합니다. 이 옵션은 관리자 권한이 필요하므로 `sudo` 명령어를 함께 사용해야 합니다. 또한, 출력 결과가 상당히 길 수 있으므로 `less` 명령어를 통해 파이프하여 확인하는 것이 좋습니다.
sudo vmstat -m | less

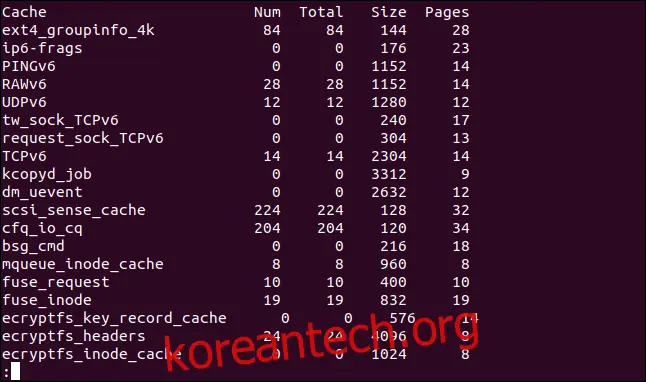
출력 결과에는 다음 5가지 열이 표시됩니다.
Cache: 캐시의 이름입니다.
Num: 현재 캐시에 있는 활성 객체의 수입니다.
Total: 캐시에서 사용 가능한 총 객체 수입니다.
Size: 캐시에 있는 각 객체의 크기입니다.
Pages: 현재 캐시에 연결된 객체가 하나 이상 포함된 총 메모리 페이지 수입니다.
`less`에서 나가려면 `q` 키를 누릅니다.
이벤트 카운터 및 메모리 통계 표시
이벤트 카운터 및 메모리 통계 페이지를 표시하려면 `-s` (통계) 옵션을 사용합니다.
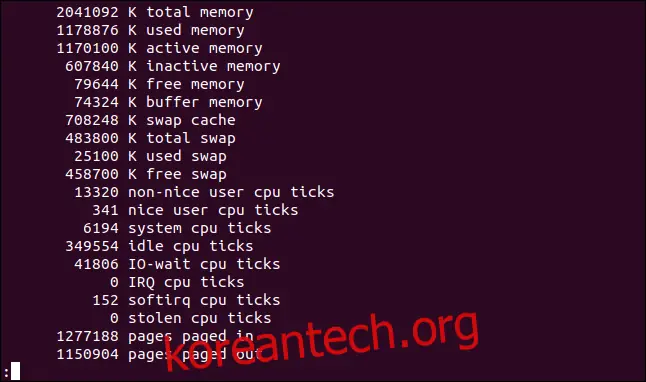
vmstat -s

표시되는 통계는 기본 `vmstat` 출력의 정보와 거의 동일하지만, 일부 정보는 더 세분화되어 있습니다.
예를 들어, 기본 출력에서는 nice와 non-nice 사용자 CPU 시간을 모두 "us" 열에 합쳐서 표시하지만, `-s` (통계) 표시는 이러한 통계를 별도로 나열합니다.
디스크 통계 표시
`-d` (디스크) 옵션을 사용하면 유사한 디스크 통계 목록을 확인할 수 있습니다. 출력 결과가 길어질 수 있으므로 `less` 명령어와 함께 사용하는 것이 좋습니다.
vmstat -d | less

각 디스크에 대해 읽기, 쓰기 및 IO의 세 가지 열이 표시됩니다.
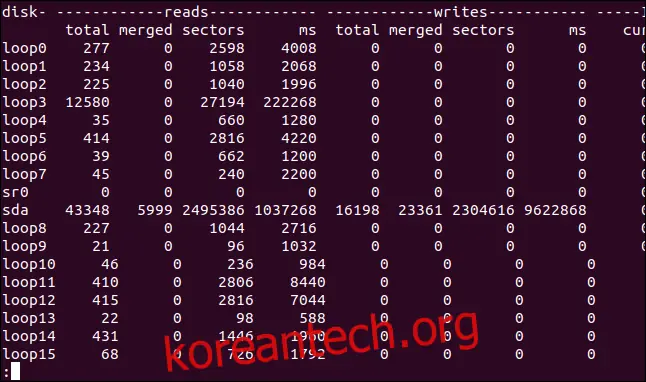
가장 오른쪽 열이 IO 정보입니다. IO의 sec 열은 초 단위로 측정되지만, 읽기 및 쓰기 열의 시간 기반 통계는 밀리초 단위로 측정됩니다.
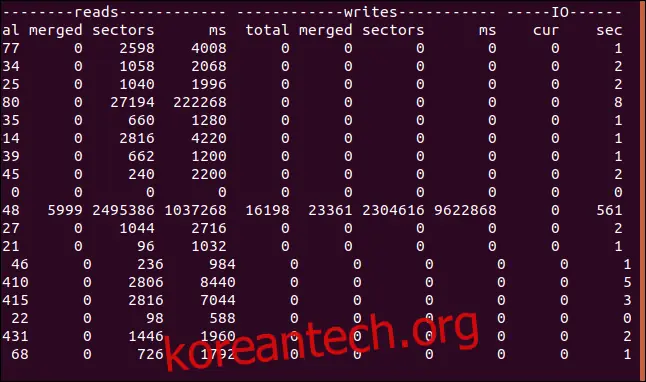
각 열의 의미는 다음과 같습니다.
읽기
total: 디스크 읽기 총 횟수입니다.
merged: 그룹화된 읽기 횟수입니다.
sectors: 읽은 총 섹터 수입니다.
ms: 디스크에서 데이터를 읽는 데 걸린 총 시간 (밀리초)입니다.
쓰기
total: 디스크 쓰기 총 횟수입니다.
merged: 그룹화된 쓰기 횟수입니다.
sectors: 쓴 총 섹터 수입니다.
ms: 디스크에 데이터를 쓰는 데 걸린 총 시간 (밀리초)입니다.
IO
cur: 현재 진행 중인 디스크 읽기 또는 쓰기 횟수입니다.
sec: 진행 중인 읽기 또는 쓰기에 걸린 시간 (초)입니다.
요약된 디스크 통계 표시
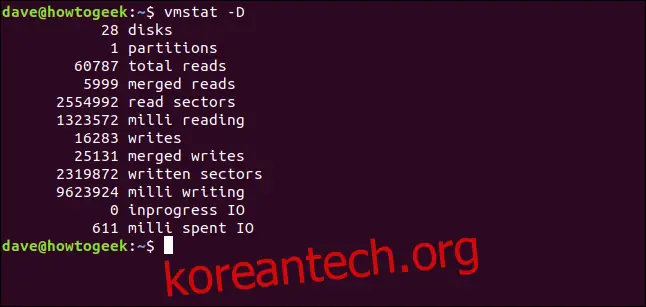
디스크 활동에 대한 요약 통계를 빠르게 확인하려면 `-D` (디스크 합계) 옵션을 사용합니다.
vmstat -D

디스크 수가 비정상적으로 많아 보일 수 있습니다. 이 글을 작성하는 데 사용된 컴퓨터는 Ubuntu를 실행하고 있으며, Ubuntu에서는 Snap을 통해 응용 프로그램을 설치할 때마다 `/dev/loop` 장치에 연결된 squashfs 의사 파일 시스템이 생성됩니다.
불행히도 이러한 장치 항목은 많은 Linux 명령어와 유틸리티에서 하드 드라이브 장치로 간주됩니다.
파티션 통계 표시
특정 파티션과 관련된 통계를 확인하려면 `-p` (파티션) 옵션을 사용하고, 파티션 식별자를 명령줄 매개변수로 제공합니다.
여기서는 `sda1` 파티션을 살펴보겠습니다. 숫자 1은 이 파티션이 이 컴퓨터의 기본 하드 드라이브인 장치 `sda`의 첫 번째 파티션임을 나타냅니다.
vmstat -p sda1

반환되는 정보는 해당 파티션에 대한 총 디스크 읽기 및 디스크 쓰기 횟수와 디스크 읽기 및 쓰기 작업에 포함된 섹터 수를 보여줍니다.

컴퓨터 내부 들여다보기
컴퓨터 내부를 들여다보고 무슨 일이 일어나는지 아는 것은 항상 좋은 경험입니다. 때로는 문제 해결을 위해, 때로는 단순히 컴퓨터가 어떻게 작동하는지 궁금해서 이러한 정보를 찾을 수 있습니다.
`vmstat` 명령어는 유용한 정보를 많이 제공합니다. 이제 여러분은 이 도구를 사용하는 방법과 그 의미를 알게 되었습니다. 필요할 때 `vmstat`을 사용하여 컴퓨터 내부를 진단해 보세요.