Linux에서 join 명령을 사용하는 방법
리눅스 join 명령어는 두 개의 텍스트 파일에서 공통 필드를 찾아 데이터를 병합하는 강력한 도구입니다. 이 명령어는 정적인 데이터 파일에 동적인 기능을 부여하며, 데이터 통합 및 분석 과정을 간소화합니다. 지금부터 join 명령어의 사용법을 자세히 알아보겠습니다.
데이터 파일 간의 일치
데이터는 현대 사회에서 매우 중요한 자산입니다. 기업, 조직, 개인 모두 데이터를 활용하고 관리합니다. 하지만 데이터가 여러 파일에 나뉘어 저장되고, 각 파일마다 형식이 다르면 정보를 통합하고 분석하는 데 어려움을 겪을 수 있습니다. 또한, 업데이트, 백업, 보관해야 할 파일이 많아질수록 데이터 관리는 더욱 복잡해집니다.
데이터를 통합하거나 전체 데이터 세트에 대한 분석을 수행해야 할 때 이러한 문제는 더욱 심각해집니다. 여러 파일에 흩어져 있는 데이터를 효율적으로 정리하고 분석에 활용할 수 있는 방법이 필요합니다. 이때, 리눅스의 join 명령어가 효과적인 해결책을 제시합니다.
두 개 이상의 파일이 공통된 데이터 요소를 공유하는 경우, join 명령어를 사용하여 데이터를 통합하고 필요한 정보를 추출할 수 있습니다.
예시 데이터 파일
join 명령어 사용법을 설명하기 위해 가상의 데이터 파일 두 개를 준비했습니다.
cat file-1.txt
cat file-2.txt
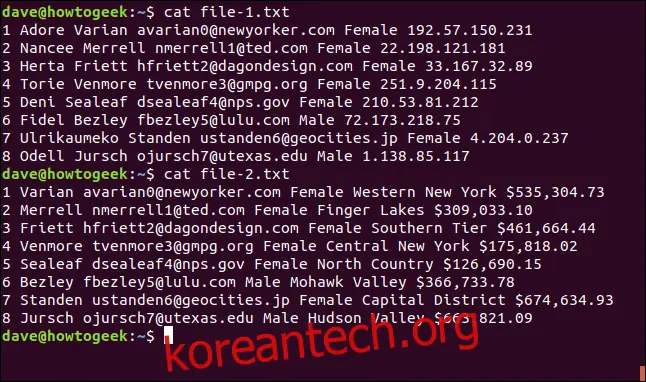
file-1.txt 파일의 내용은 다음과 같습니다.
1 Adore Varian [email protected] Female 192.57.150.231 2 Nancee Merrell [email protected] Female 22.198.121.181 3 Herta Friett [email protected] Female 33.167.32.89 4 Torie Venmore [email protected] Female 251.9.204.115 5 Deni Sealeaf [email protected] Female 210.53.81.212 6 Fidel Bezley [email protected] Male 72.173.218.75 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 8 Odell Jursch [email protected] Male 1.138.85.117
각 줄은 다음 정보를 포함합니다.
번호
이름
성
이메일 주소
성별
IP 주소
file-2.txt 파일의 내용은 다음과 같습니다.
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93 8 Jursch [email protected] Male Hudson Valley $663,821.09
각 줄은 다음 정보를 포함합니다.
번호
성
이메일 주소
성별
뉴욕 지역
달러 가치
join 명령어는 공백으로 구분된 "필드"를 기준으로 작동합니다. 두 파일 사이의 행을 일치시키려면 각 행에 공통 필드가 있어야 합니다. 파일에 모두 나타나는 필드만 일치시킬 수 있습니다. IP 주소와 이름은 한 파일에만 나타나므로 사용할 수 없습니다. 성은 두 파일에 모두 있지만, 여러 사람이 같은 성을 사용하므로 좋은 선택이 아닙니다.
성별은 두 파일에 모두 있지만, 데이터가 너무 모호해서 정확한 연결을 보장할 수 없습니다. 뉴욕 지역과 달러 값은 한 파일에만 존재합니다. 하지만 이메일 주소는 두 파일에 모두 있고 각 개인에게 고유하므로 일치시킬 수 있는 필드로 사용할 수 있습니다. 또한, 각 행의 번호도 일치하는 필드로 사용할 수 있습니다.
두 파일은 필드 수가 다르지만 문제없이 join 명령어를 사용할 수 있습니다. 중요한 것은 각 파일에서 사용할 필드를 지정하는 것입니다.
뉴욕 지역과 같은 필드는 공백으로 구분되어 있어 여러 단어가 하나의 필드로 처리될 수 있습니다. 하지만 일치하는 기준만 만족한다면 문제없이 처리할 수 있습니다.
join 명령어 실행
먼저 일치시킬 필드를 기준으로 정렬해야 합니다. 두 파일 모두 번호가 오름차순으로 정렬되어 있으므로 이 기준을 충족합니다. 기본적으로 join 명령어는 각 파일의 첫 번째 필드를 사용합니다. 또한, 필드 구분 기호로 공백을 사용합니다. 따라서 다음과 같이 간단하게 명령어를 실행할 수 있습니다.
join file-1.txt file-2.txt
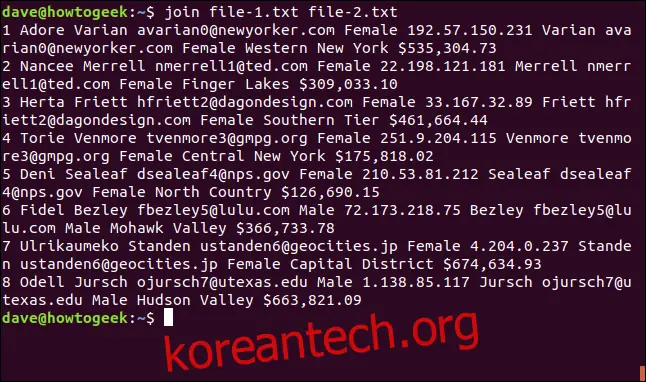
join 명령어는 명령줄에 나열된 순서대로 파일을 "파일 1"과 "파일 2"로 간주합니다.
출력 결과는 다음과 같습니다.
1 Adore Varian [email protected] Female 192.57.150.231 Varian [email protected] Female Western New York $535,304.73 2 Nancee Merrell [email protected] Female 22.198.121.181 Merrell [email protected] Female Finger Lakes $309,033.10 3 Herta Friett [email protected] Female 33.167.32.89 Friett [email protected] Female Southern Tier $461,664.44 4 Torie Venmore [email protected] Female 251.9.204.115 Venmore [email protected] Female Central New York $175,818.02 5 Deni Sealeaf [email protected] Female 210.53.81.212 Sealeaf [email protected] Female North Country $126,690.15 6 Fidel Bezley [email protected] Male 72.173.218.75 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 Standen [email protected] Female Capital District $674,634.93 8 Odell Jursch [email protected] Male 1.138.85.117 Jursch [email protected] Male Hudson Valley $663,821.09
출력 형식은 다음과 같습니다. 일치하는 필드가 먼저 인쇄되고, 그 다음 파일 1의 나머지 필드, 마지막으로 일치 필드가 없는 파일 2의 필드가 인쇄됩니다.
정렬되지 않은 필드
이번에는 의도적으로 정렬되지 않은 파일을 사용하여 join 명령어가 어떻게 동작하는지 살펴보겠습니다. file-3.txt는 file-2.txt와 동일하지만, 8번째 행이 5번째와 6번째 행 사이에 위치합니다.
file-3.txt의 내용은 다음과 같습니다.
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 8 Jursch [email protected] Male Hudson Valley $663,821.09 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
file-3.txt와 file-1.txt를 결합하기 위해 다음 명령어를 실행합니다.
join file-1.txt file-3.txt
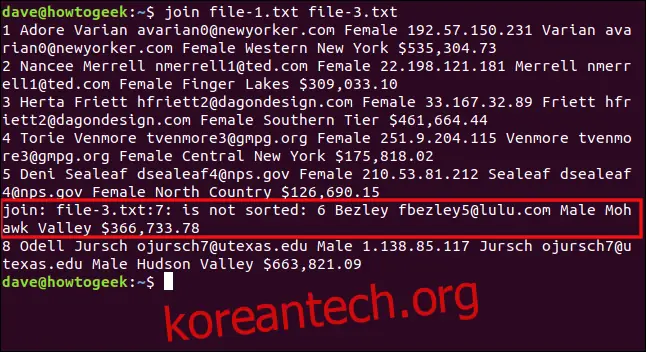
join 명령어는 file-3.txt의 일곱 번째 줄이 순서가 맞지 않아 처리할 수 없다고 알려줍니다. 7번째 행은 숫자 6으로 시작하며, 정렬된 목록에서 8보다 먼저 와야 합니다. 파일의 6번째 줄(‘8 Odell’로 시작)이 마지막으로 처리되어 출력이 표시됩니다.
파일이 올바르게 정렬되었는지 확인하려면 ‘--check-order’ 옵션을 사용할 수 있습니다. 이 옵션을 사용하면 병합을 시도하지 않고 순서 오류를 확인할 수 있습니다.
다음 명령어를 실행해 보겠습니다.
join --check-order file-1.txt file-3.txt
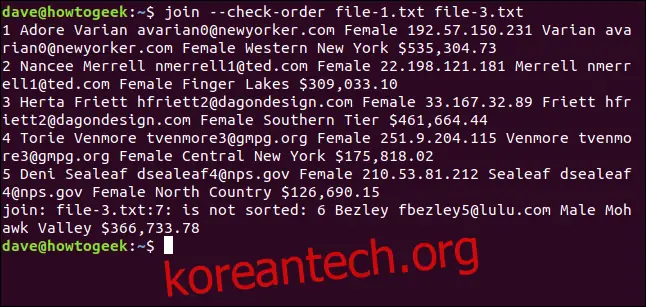
join 명령어는 file-3.txt 파일의 7번째 행에 문제가 있다는 것을 미리 알려줍니다.
누락된 행이 있는 파일
file-4.txt에서 마지막 행(8번째 행)을 제거했습니다. 내용은 다음과 같습니다.
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
다음 명령어를 실행하면 join 명령어는 모든 행을 처리합니다.
join file-1.txt file-4.txt
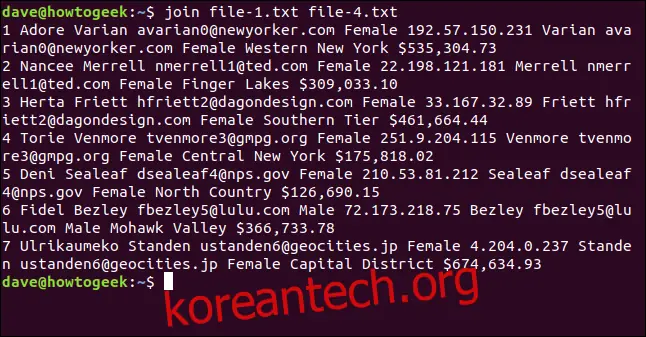
출력에는 7개의 병합된 행이 표시됩니다.
'-a' 옵션은 결합에 일치하지 않는 행도 출력하도록 지시합니다.
파일 2의 행과 일치하지 않는 파일 1의 행을 인쇄하도록 하려면 다음 명령어를 입력합니다.
join -a 1 file-1.txt file-4.txt
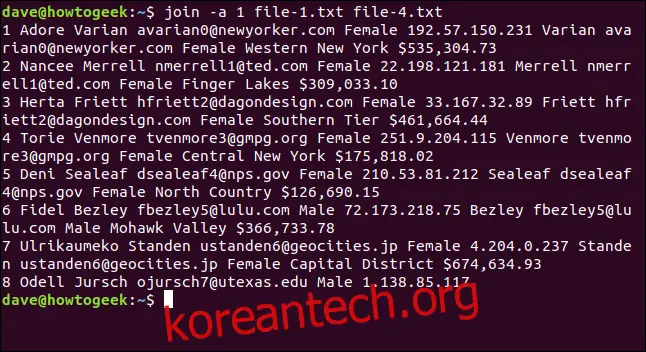
7개의 행이 일치하고 파일 1의 8번째 행이 일치하지 않아 출력에 포함됩니다. 파일 4에는 일치하는 8번째 행이 없으므로 병합된 정보는 없습니다. 하지만 적어도 출력에 표시되어 파일 4에 일치하는 항목이 없다는 것을 알 수 있습니다.
일치하지 않는 행만 출력하려면 다음 ‘-v’ 옵션을 사용합니다.
join -v file-1.txt file-4.txt

파일 2에서 일치하는 항목이 없는 것은 8번째 행뿐입니다.
다른 필드 일치
기본 필드(필드 1)가 아닌 다른 필드를 사용하여 두 개의 새 파일을 일치시켜 보겠습니다. 다음은 file-7.txt의 내용입니다.
[email protected] Female 192.57.150.231 [email protected] Female 210.53.81.212 [email protected] Male 72.173.218.75 [email protected] Female 33.167.32.89 [email protected] Female 22.198.121.181 [email protected] Male 1.138.85.117 [email protected] Female 251.9.204.115 [email protected] Female 4.204.0.237
다음은 file-8.txt의 내용입니다.
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
결합에 사용할 수 있는 유일한 필드는 이메일 주소입니다. 이메일 주소는 첫 번째 파일의 첫 번째 필드이고, 두 번째 파일의 두 번째 필드입니다. 이를 지정하기 위해 '-1' 옵션(파일 1의 필드)과 '-2' 옵션(파일 2의 필드)을 사용합니다. 각 파일에서 어떤 필드를 결합에 사용해야 하는지 나타내는 숫자를 사용합니다.
파일 1의 첫 번째 필드와 파일 2의 두 번째 필드를 사용하도록 join 명령어에 지시하려면 다음 명령어를 입력합니다.
join -1 1 -2 2 file-7.txt file-8.txt
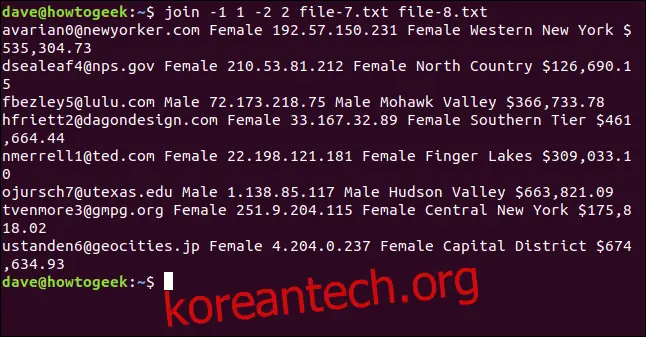
이메일 주소가 출력 결과에서 각 행의 첫 번째 필드로 표시되어 파일이 결합됩니다.
다른 필드 구분 기호 사용
필드가 공백이 아닌 다른 문자로 구분된 파일의 경우 어떻게 해야 할까요? 다음 두 파일은 쉼표로 구분되어 있습니다. 공백은 여러 단어로 구성된 지명 사이에 사용됩니다.
cat file-5.txt
cat file-6.txt

필드 구분 기호로 사용할 문자를 join 명령어에 알리려면 '-t' 옵션을 사용할 수 있습니다. 이 경우 쉼표이므로 다음 명령어를 입력합니다.
join -t, file-5.txt file-6.txt
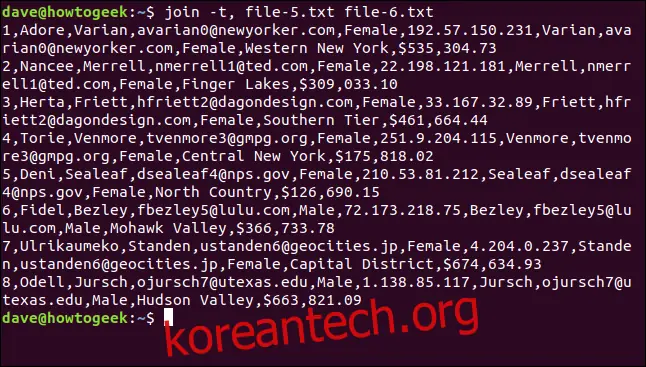
모든 행이 일치하고 장소 이름에 공백이 유지됩니다.
대소문자 무시
file-9.txt 파일은 file-8.txt와 거의 동일합니다. 유일한 차이점은 일부 이메일 주소에 대문자가 있다는 것입니다. 내용은 다음과 같습니다.
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
file-7.txt와 file-8.txt를 결합했을 때는 완벽하게 작동했지만, file-7.txt와 file-9.txt에서 어떤 일이 발생하는지 확인해 보겠습니다.
다음 명령어를 실행합니다.
join -1 1 -2 2 file-7.txt file-9.txt
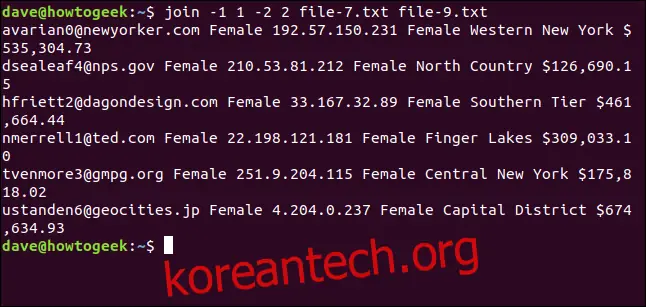
6개 행만 일치합니다. 대문자와 소문자의 차이로 인해 다른 두 이메일 주소가 결합되지 않습니다.
'-i' 옵션(대소문자 무시)을 사용하면 join 명령어는 이러한 차이점을 무시하고 대소문자에 관계없이 동일한 텍스트가 포함된 필드를 일치시킬 수 있습니다.
다음 명령어를 실행합니다.
join -1 1 -2 2 -i file-7.txt file-9.txt
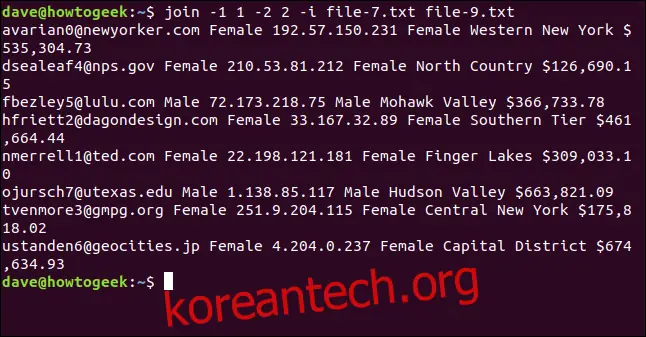
8개의 행이 모두 일치하고 성공적으로 결합됩니다.
결론
join 명령어는 복잡한 데이터 준비 과정에서 매우 유용한 도구입니다. 데이터를 분석하거나 다른 시스템으로 가져오기 위해 데이터를 변환해야 할 때 강력한 해결책을 제공합니다. 어떤 상황에서든 join 명령어는 데이터 처리 작업을 훨씬 쉽게 만들어 줄 것입니다.