웹 스크래핑은 웹 페이지에서 정보를 자동으로 추출하고 분석하는 데 사용되는 강력한 기술입니다. 수동으로도 이 작업을 수행할 수 있지만, 이는 번거롭고 많은 시간을 소모하는 일이 될 수 있습니다. 웹 스크래핑 도구를 사용하면 이러한 프로세스를 더욱 빠르고 효율적으로 처리할 수 있으며, 비용 절감 효과도 있습니다.
놀랍게도 Google 스프레드시트는 IMPORTXML 기능 덕분에 웹 스크래핑 도구로 활용될 수 있는 잠재력을 가지고 있습니다. IMPORTXML을 이용하면 웹 페이지에서 데이터를 쉽게 가져와서 분석, 보고서 작성 또는 기타 데이터 기반 작업에 활용할 수 있습니다.
Google 스프레드시트의 IMPORTXML 함수
Google 스프레드시트에는 XML, HTML, RSS, CSV와 같은 다양한 웹 형식에서 데이터를 가져올 수 있는 IMPORTXML이라는 내장 함수가 있습니다. 복잡한 코딩 없이 웹사이트에서 데이터를 수집하려는 경우, 이 기능은 매우 유용합니다.
IMPORTXML 함수의 기본 구문은 다음과 같습니다.
=IMPORTXML(url, xpath_query)
- url: 스크래핑하려는 웹페이지의 URL 주소입니다.
- xpath_query: 추출하고자 하는 데이터를 정의하는 XPath 쿼리입니다.
XPath(XML Path Language)는 HTML을 포함한 XML 문서 구조를 탐색하는 데 사용되는 언어로, HTML 구조 내에서 데이터 위치를 정확하게 지정할 수 있게 해줍니다. IMPORTXML을 효과적으로 사용하려면 XPath 쿼리에 대한 이해가 필수적입니다.
XPath 이해
XPath는 HTML 문서 내에서 데이터를 탐색하고 필터링하기 위한 여러 기능과 표현식을 제공합니다. 이 글에서는 포괄적인 XML 및 XPath 가이드보다는 몇 가지 필수 XPath 개념을 다루도록 하겠습니다.
- 요소 선택: / 및 // 기호를 사용하여 경로를 표시하고 요소를 선택할 수 있습니다. 예를 들어, /html/body/div는 문서 본문 내의 모든 div 요소를 선택합니다.
- 속성 선택: @ 기호를 사용하여 속성을 선택할 수 있습니다. 예를 들어, //@href는 페이지 내 모든 href 속성을 선택합니다.
- 조건자 필터: 대괄호 ([ ])를 사용하여 조건을 설정하여 요소를 필터링할 수 있습니다. 예를 들어, /div[@class=”container”]는 “container” 클래스를 가진 모든 div 요소를 선택합니다.
- 함수: XPath는 text(), contains(), starts-with()와 같은 다양한 함수를 제공하여 텍스트 내용이나 속성 값 확인과 같은 특정 작업을 수행할 수 있도록 합니다.
지금까지 IMPORTXML의 구문과 웹사이트의 URL, 추출할 요소에 대해 알아보았습니다. 그렇다면 요소의 XPath는 어떻게 알아낼 수 있을까요?
IMPORTXML을 사용하여 데이터를 추출하기 위해 웹사이트의 구조를 전부 암기할 필요는 없습니다. 모든 브라우저에는 각 요소의 XPath를 바로 복사할 수 있는 편리한 도구가 있기 때문입니다.
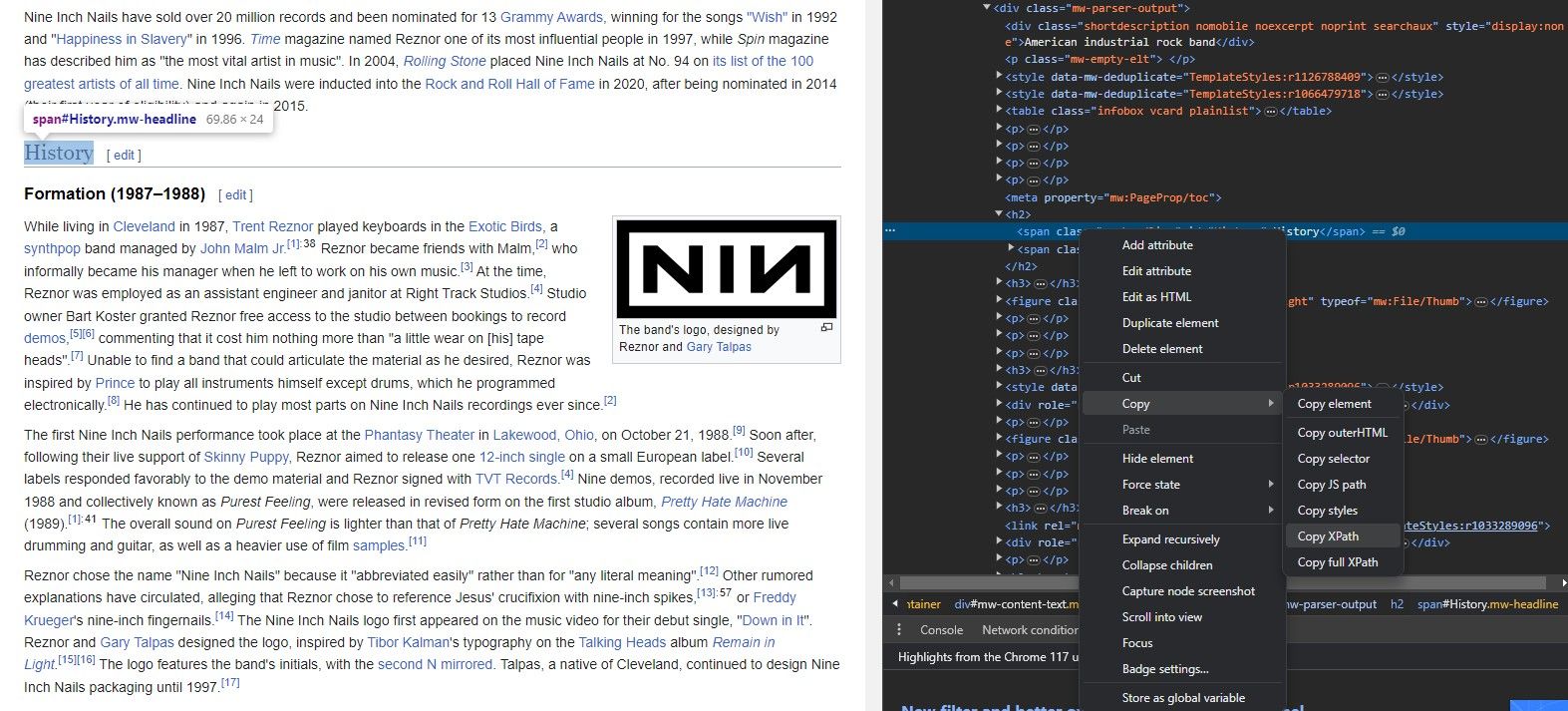
요소 검사 도구를 사용하면 웹사이트 요소에서 XPath를 추출할 수 있습니다. 방법은 다음과 같습니다.
이제 모든 준비가 완료되었으니 IMPORTXML이 어떻게 작동하는지 살펴보고 몇 가지 링크를 스크래핑해 보겠습니다.
IMPORTXML을 사용하여 웹사이트에서 링크를 스크래핑하는 방법
IMPORTXML을 사용하면 웹사이트에서 다양한 종류의 데이터를 스크래핑할 수 있습니다. 여기에는 링크, 비디오, 이미지, 그리고 웹사이트의 거의 모든 요소가 포함됩니다. 링크는 웹 분석에서 가장 중요한 요소 중 하나이며, 링크된 페이지들을 분석하는 것만으로도 웹사이트에 대한 많은 정보를 얻을 수 있습니다.
IMPORTXML을 사용하면 Google 스프레드시트에서 링크를 빠르게 스크래핑한 후 Google 스프레드시트가 제공하는 다양한 기능을 활용하여 추가 분석을 수행할 수 있습니다.
1. 모든 링크 스크래핑
웹페이지에서 모든 링크를 스크래핑하려면 다음 공식을 사용할 수 있습니다.
=IMPORTXML(url, "//a/@href")
이 XPath 쿼리는 요소의 모든 href 속성을 선택하여 페이지의 모든 링크를 추출합니다.
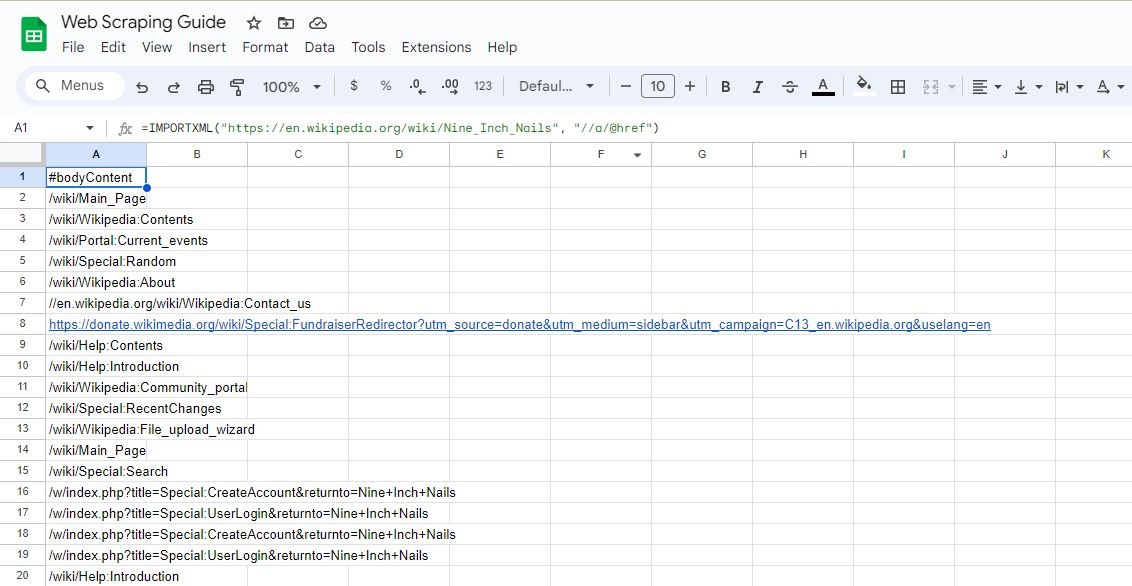
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
위의 공식은 위키피디아 기사의 모든 링크를 스크래핑합니다.
웹페이지의 URL을 별도의 셀에 입력한 후 해당 셀을 참조하는 것이 좋습니다. 이렇게 하면 수식이 너무 길어지거나 복잡해지는 것을 방지할 수 있습니다. XPath 쿼리에도 동일한 방식을 적용할 수 있습니다.
2. 모든 링크 텍스트 스크래핑
URL과 함께 링크 텍스트를 추출하려면 다음을 사용할 수 있습니다.
=IMPORTXML(url, "//a")
이 쿼리는 모든 요소를 선택하고 결과에서 링크 텍스트와 URL을 추출할 수 있습니다.
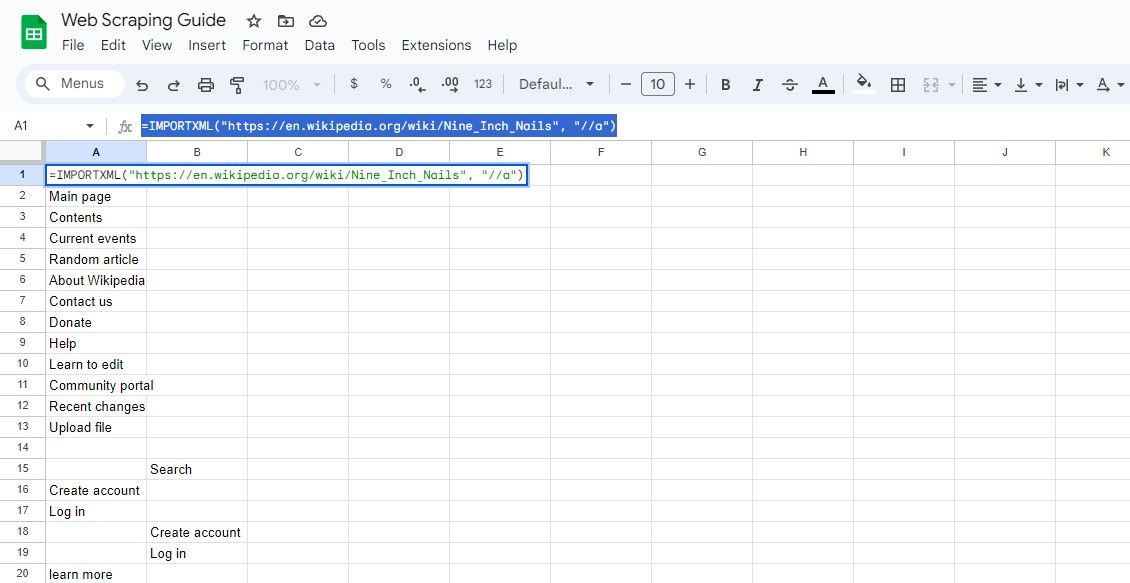
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
위의 공식은 동일한 위키피디아 문서에서 링크 텍스트를 가져옵니다.
IMPORTXML을 사용하여 웹사이트에서 특정 링크를 스크래핑하는 방법
때로는 특정 기준에 따라 링크를 스크래핑해야 할 수도 있습니다. 예를 들어, 특정 키워드가 포함된 링크나 페이지의 특정 섹션에 있는 링크를 추출하고자 할 수 있습니다.
XPath에 대한 적절한 지식을 바탕으로 원하는 요소를 정확하게 식별할 수 있습니다.
1. 키워드가 포함된 링크 스크래핑
특정 키워드가 포함된 링크를 스크래핑하려면 contains() XPath 함수를 사용할 수 있습니다.
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
이 쿼리는 href 속성에 지정된 키워드가 포함된 요소의 href 속성을 선택합니다.
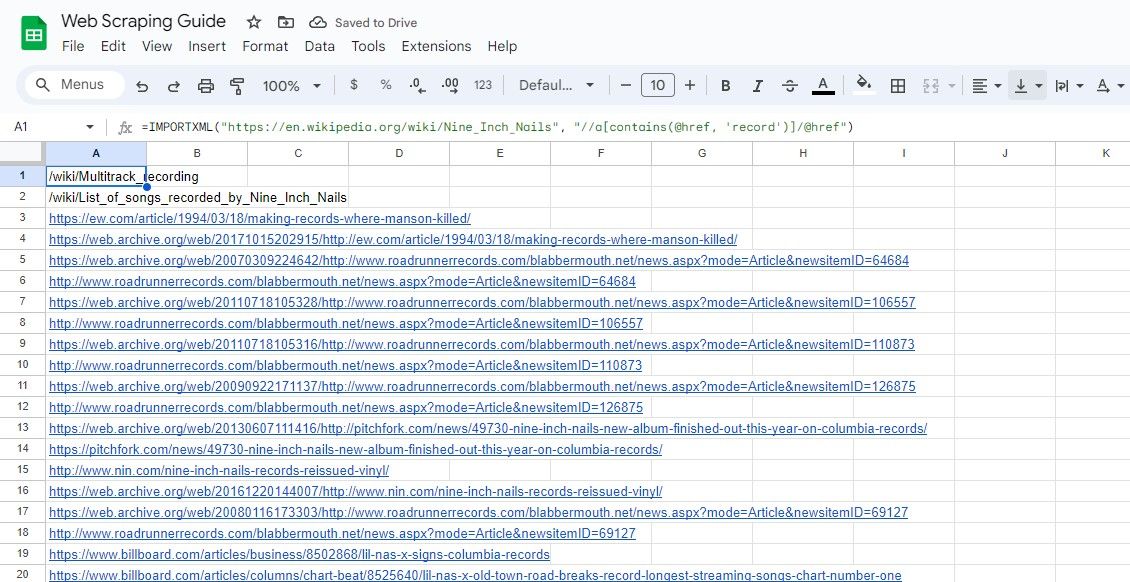
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
위의 공식은 샘플 위키피디아 기사에서 텍스트에 ‘record’라는 단어가 포함된 모든 링크를 스크래핑합니다.
2. 섹션 내 링크 스크래핑
웹페이지의 특정 섹션에서 링크를 스크래핑하려면 해당 섹션의 XPath를 지정하면 됩니다. 예를 들면 다음과 같습니다.
=IMPORTXML(url, "//div[@class="section"]//a/@href")
이 쿼리는 “section” 클래스를 가진 div 요소 내에서 요소의 href 속성을 선택합니다.
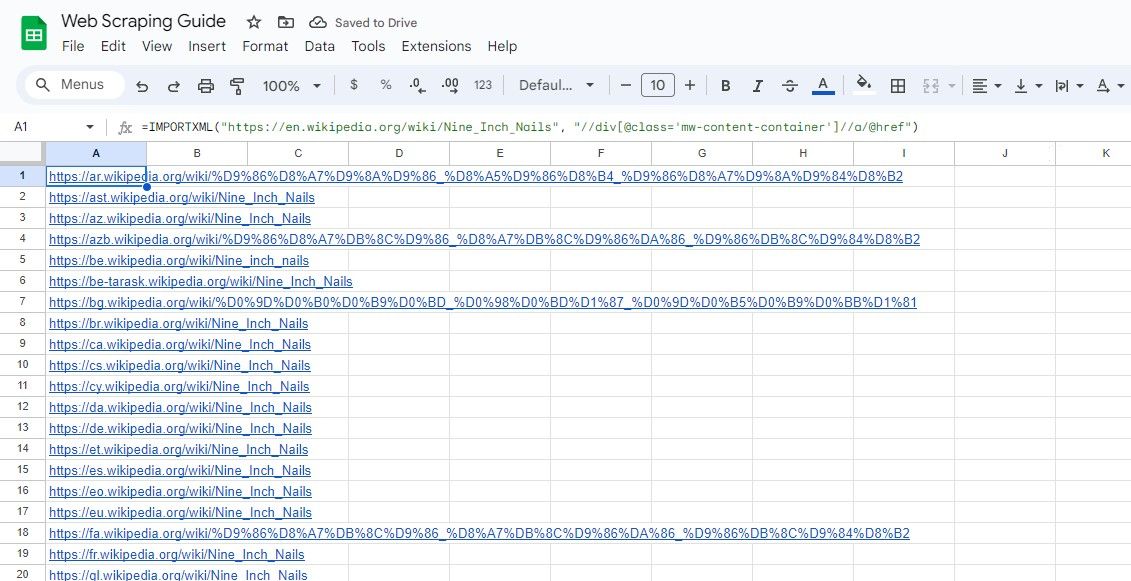
마찬가지로 다음 공식은 “mw-content-container” 클래스를 가진 div 요소 내의 모든 링크를 선택합니다.
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
웹 스크래핑 이상의 용도로 IMPORTXML을 활용할 수 있다는 점을 기억해야 합니다. IMPORT 함수군을 사용하여 웹사이트의 데이터 테이블을 Google 스프레드시트로 가져올 수도 있습니다.
Google 스프레드시트와 Excel은 대부분의 기능을 공유하지만, IMPORT 함수군은 Google 스프레드시트에서만 사용할 수 있습니다. 웹사이트에서 Excel로 데이터를 가져오려면 다른 방법을 고려해야 합니다.
Google 스프레드시트를 활용한 웹 스크래핑 간소화
Google 스프레드시트와 IMPORTXML 기능을 이용한 웹 스크래핑은 웹사이트에서 데이터를 수집하는 다양하고 접근 가능한 방법입니다.
XPath를 숙지하고 효과적인 쿼리 작성법을 이해함으로써 IMPORTXML의 잠재력을 최대한 활용하고 웹 리소스에서 귀중한 통찰력을 얻을 수 있습니다. 이제 스크래핑을 시작하여 웹 분석 능력을 한 단계 더 발전시켜 보세요!