

이전 기사에서는 ChatGPT API로 AI 챗봇을 구축하고 역할을 할당하여 개인화하는 방법을 시연했습니다. 하지만 자신의 데이터로 AI를 훈련시키려면 어떻게 해야 할까요? 예를 들어, 책, 재무 데이터 또는 대규모 데이터베이스 집합이 있고 쉽게 검색하고 싶을 수 있습니다. 이 기사에서는 LangChain 및 ChatGPT API를 사용하여 사용자 지정 지식 기반으로 AI 챗봇을 교육하는 방법에 대한 따라하기 쉬운 자습서를 제공합니다. OpenAI의 LLM(Large Language Model)을 사용하여 AI 챗봇을 교육하기 위해 LangChain, GPT Index 및 기타 강력한 라이브러리를 배포하고 있습니다. 따라서 자신의 데이터 세트를 사용하여 AI Chatbot을 훈련하고 생성하는 방법을 확인하십시오.
목차
ChatGPT API, LangChain 및 GPT Index(2023)를 사용하여 맞춤형 기술 자료로 AI Chatbot 교육
이 기사에서는 자신의 데이터로 AI 챗봇을 가르치는 단계를 자세히 설명했습니다. 도구 및 소프트웨어 설정에서 AI 모델 교육에 이르기까지 모든 지침을 이해하기 쉬운 언어로 포함했습니다. 어떤 부분도 건너뛰지 않고 위에서 아래로 지침을 따르는 것이 좋습니다.
자신의 데이터로 AI를 훈련시키기 전에 주목해야 할 사항
1. Windows, macOS, Linux 또는 ChromeOS 등 모든 플랫폼에서 AI 챗봇을 교육할 수 있습니다. 이 문서에서는 Windows 11을 사용하고 있지만 단계는 다른 플랫폼과 거의 동일합니다.
2. 본 가이드는 일반 사용자를 대상으로 하며, 간단한 언어로 설명이 되어 있습니다. 따라서 컴퓨터에 대한 대략적인 지식이 있고 코딩 방법을 모르더라도 몇 분 안에 쉽게 Q&A AI 챗봇을 훈련하고 만들 수 있습니다. 이전 ChatGPT 봇 기사를 따라했다면 프로세스를 이해하기가 훨씬 쉬울 것입니다.
3. 자체 데이터를 기반으로 AI 챗봇을 훈련시킬 예정이므로 성능이 좋은 CPU와 GPU를 갖춘 컴퓨터를 사용하는 것이 좋습니다. 그러나 테스트 목적으로 저가형 컴퓨터를 사용할 수 있으며 문제 없이 작동합니다. 크롬북을 사용하여 100페이지(~100MB)의 책을 사용하여 AI 모델을 교육했습니다. 그러나 수천 페이지에 달하는 대규모 데이터 세트를 학습시키려면 강력한 컴퓨터를 사용하는 것이 좋습니다.
4. 마지막으로 최상의 결과를 얻으려면 데이터 세트가 영어로 되어 있어야 하지만 OpenAI에 따르면 프랑스어, 스페인어, 독일어 등과 같은 널리 사용되는 국제 언어에서도 작동합니다. 언어.
AI 챗봇 훈련을 위한 소프트웨어 환경 설정
이전 기사와 마찬가지로 여러 라이브러리와 함께 Python 및 Pip를 설치해야 합니다. 이 기사에서는 새로운 사용자도 설정 프로세스를 이해할 수 있도록 모든 것을 처음부터 설정합니다. 간략한 아이디어를 제공하기 위해 Python과 Pip을 설치합니다. 그런 다음 OpenAI, GPT Index, Gradio 및 PyPDF2를 포함하는 Python 라이브러리를 설치합니다. 그 과정에서 각 라이브러리가 수행하는 작업을 배우게 됩니다. 다시 말하지만, 설치 과정에 초조해하지 마십시오. 매우 간단합니다. 그런 점에서 바로 시작하겠습니다.
파이썬 설치
1. 먼저 컴퓨터에 Python(Pip)을 설치해야 합니다. 열려 있는 이 링크 플랫폼용 설치 파일을 다운로드합니다.
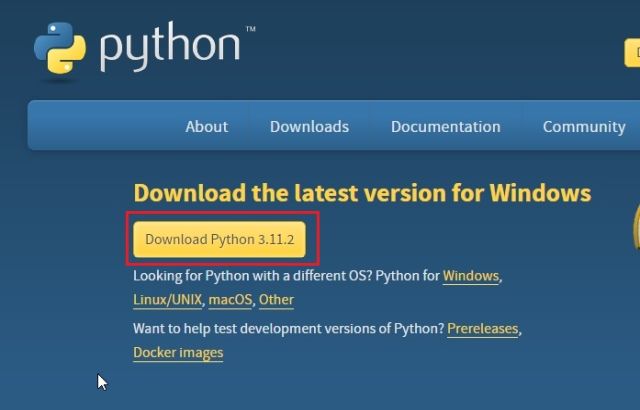
2. 다음으로 설치 파일을 실행하고 “Add Python.exe to PATH” 확인란을 선택했는지 확인합니다. 이것은 매우 중요한 단계입니다. 그런 다음 “지금 설치”를 클릭하고 일반적인 단계에 따라 Python을 설치합니다.
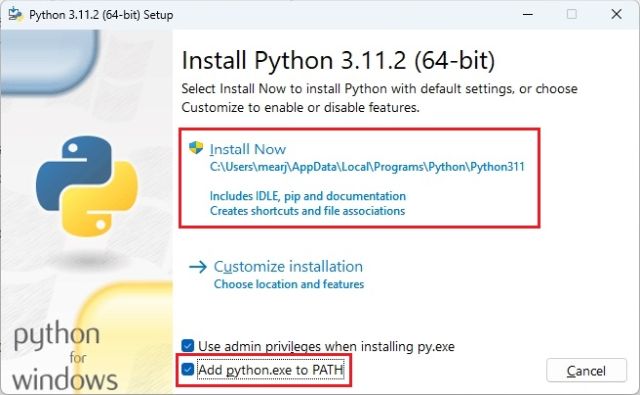
3. Python이 제대로 설치되었는지 확인하려면 컴퓨터에서 터미널을 엽니다. Windows에서 Windows 터미널을 사용하고 있지만 명령 프롬프트를 사용할 수도 있습니다. 여기에서 아래 명령을 실행하면 Python 버전이 출력됩니다. Linux 및 macOS에서는 python –version 대신 python3 –version을 사용해야 할 수 있습니다.
python --version
업그레이드 핍
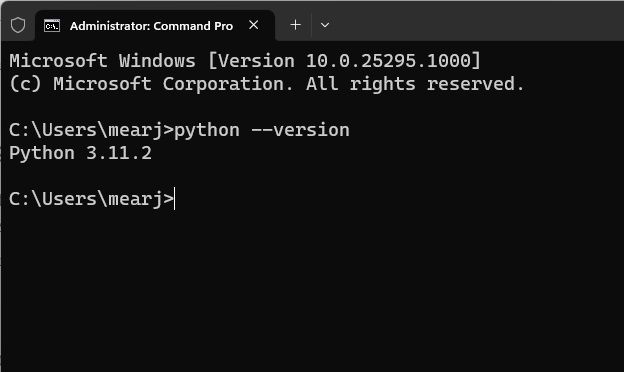
Python을 설치하면 Pip이 시스템에 동시에 설치됩니다. 그럼 최신버전으로 업그레이드 해보겠습니다. 모르는 사람들을 위해 Pip은 Python의 패키지 관리자입니다. 기본적으로 터미널에서 수천 개의 Python 라이브러리를 설치할 수 있습니다. Pip을 사용하여 OpenAI, gpt_index, gradio 및 PyPDF2 라이브러리를 설치할 수 있습니다. 따라야 할 단계는 다음과 같습니다.
1. 컴퓨터에서 원하는 터미널을 엽니다. 저는 Windows 터미널을 사용하고 있지만 명령 프롬프트를 사용할 수도 있습니다. 이제 아래 명령을 실행하여 Pip을 업데이트합니다. 다시 말하지만 Linux 및 macOS에서는 python3 및 pip3를 사용해야 할 수 있습니다.
python -m pip install -U pip
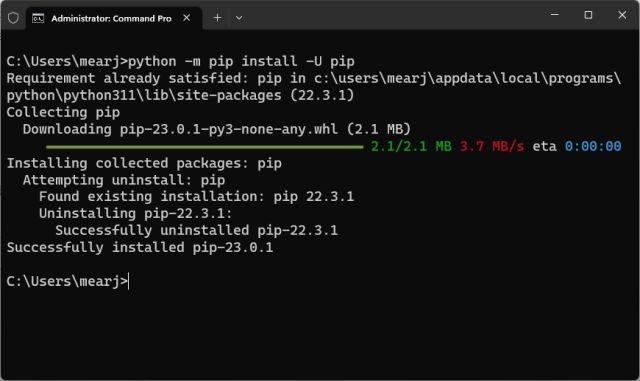
2. Pip이 제대로 설치되었는지 확인하려면 아래 명령을 실행합니다. 버전 번호를 출력합니다. 오류가 발생하면 Windows에 Pip를 설치하여 PATH 관련 문제를 해결하는 방법에 대한 전용 가이드를 따르십시오.
pip --version
OpenAI, GPT 인덱스, PyPDF2 및 Gradio 라이브러리 설치
Python과 Pip을 설정했으면 맞춤형 지식 기반으로 AI 챗봇을 교육하는 데 도움이 되는 필수 라이브러리를 설치할 차례입니다. 따라야 할 단계는 다음과 같습니다.
1. 터미널을 열고 아래 명령을 실행하여 OpenAI 라이브러리를 설치합니다. LLM(Large Language Model)으로 사용하여 AI 챗봇을 훈련하고 생성합니다. 또한 OpenAI에서 LangChain 프레임워크를 가져올 것입니다. Linux 및 macOS 사용자는 pip 대신 pip3를 사용해야 할 수 있습니다.
pip install openai
2. 다음으로 LlamaIndex라고도 하는 GPT Index를 설치합니다. 이를 통해 LLM은 지식 기반인 외부 데이터에 연결할 수 있습니다.
pip install gpt_index
3. 그런 다음 PyPDF2를 설치하여 PDF 파일을 구문 분석합니다. 데이터를 PDF 형식으로 제공하려는 경우 이 라이브러리는 프로그램이 데이터를 쉽게 읽을 수 있도록 도와줍니다.
pip install PyPDF2
4. 마지막으로 Gradio 라이브러리를 설치합니다. 이것은 훈련된 AI 챗봇과 상호 작용하기 위한 간단한 UI를 만들기 위한 것입니다. 이제 AI 챗봇 훈련에 필요한 모든 라이브러리 설치가 완료되었습니다.
pip install gradio
코드 편집기 다운로드
마지막으로 일부 코드를 편집하려면 코드 편집기가 필요합니다. Windows에서는 Notepad++(다운로드). 첨부된 링크를 통해 프로그램을 다운로드하여 설치하기만 하면 됩니다. 강력한 IDE에 익숙한 경우 모든 플랫폼에서 VS Code를 사용할 수도 있습니다. VS Code 외에 Sublime Text(다운로드) macOS 및 Linux에서.
ChromeOS의 경우 뛰어난 Caret 앱(다운로드) 코드를 편집합니다. 소프트웨어 환경 설정이 거의 완료되었으며 OpenAI API 키를 가져올 시간입니다.
무료로 OpenAI API 키 받기
이제 맞춤형 지식 기반을 기반으로 AI 챗봇을 훈련하고 생성하려면 OpenAI에서 API 키를 가져와야 합니다. API 키를 사용하면 OpenAI의 모델을 LLM으로 사용하여 사용자 정의 데이터를 연구하고 추론을 도출할 수 있습니다. 현재 OpenAI는 처음 3개월 동안 신규 사용자에게 $5 상당의 무료 크레딧이 포함된 무료 API 키를 제공하고 있습니다. 이전에 OpenAI 계정을 만든 경우 계정에 $18의 무료 크레딧이 있을 수 있습니다. 무료 크레딧이 소진되면 API 액세스 비용을 지불해야 합니다. 하지만 지금은 모든 사용자가 무료로 사용할 수 있습니다.
1. 다음으로 이동 platform.openai.com/signup 그리고 무료 계정을 만드세요. 이미 OpenAI 계정이 있는 경우 로그인하기만 하면 됩니다.
2. 그런 다음 오른쪽 상단 모서리에 있는 프로필을 클릭하고 드롭다운 메뉴에서 “API 키 보기”를 선택합니다.
3. 여기에서 “새 비밀 키 만들기”를 클릭하고 API 키를 복사합니다. 나중에 전체 API 키를 복사하거나 볼 수 없습니다. 따라서 API 키를 즉시 복사하여 메모장 파일에 붙여넣는 것이 좋습니다.
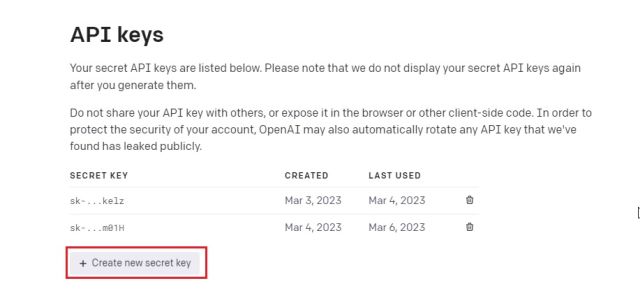
4. 또한 공개적으로 API 키를 공유하거나 표시하지 마십시오. 귀하의 계정에 액세스하기 위한 개인 키입니다. 또한 API 키를 삭제하고 여러 개인 키(최대 5개)를 생성할 수 있습니다.
맞춤형 기술 자료로 AI 챗봇 훈련 및 생성
이제 소프트웨어 환경을 설정하고 OpenAI에서 API 키를 얻었으니 AI 챗봇을 훈련시켜 봅시다. 여기에서는 Davinci가 텍스트 완성에 훨씬 더 잘 작동하기 때문에 최신 “gpt-3.5-turbo” 모델 대신 “text-davinci-003” 모델을 사용합니다. 원하는 경우 모델을 Turbo로 변경하여 비용을 줄일 수 있습니다. 이상으로 지침으로 넘어가겠습니다.
AI 챗봇 훈련을 위한 문서 추가
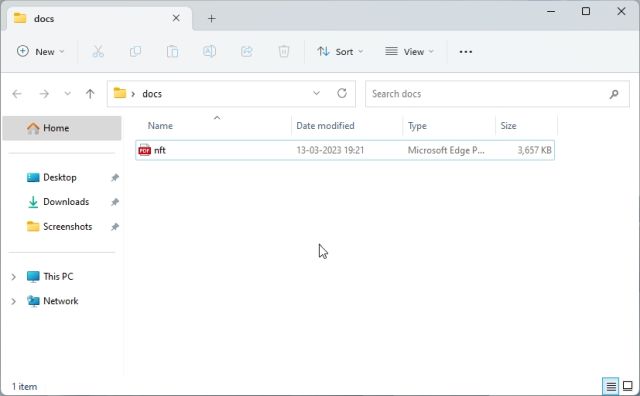
1. 먼저 데스크톱과 같이 액세스 가능한 위치에 docs라는 새 폴더를 만듭니다. 선호도에 따라 다른 위치를 선택할 수도 있습니다. 그러나 폴더 이름은 docs로 유지하십시오.

2. 다음으로 AI 훈련에 사용할 문서를 “docs” 폴더로 이동합니다. 여러 텍스트 또는 PDF 파일(스캔 파일 포함)을 추가할 수 있습니다. Excel에 큰 테이블이 있는 경우 CSV 또는 PDF 파일로 가져온 다음 “docs” 폴더에 추가할 수 있습니다. 이 설명에 따라 SQL 데이터베이스 파일을 추가할 수도 있습니다. 랭체인 AI 트윗. 언급된 파일 형식 외에 많은 파일 형식을 시도하지는 않았지만 직접 추가하고 확인할 수 있습니다. 이 기사에서는 NFT에 대한 내 기사 중 하나를 PDF 형식으로 추가하고 있습니다.
참고: 문서가 큰 경우 CPU 및 GPU에 따라 데이터를 처리하는 데 시간이 더 오래 걸립니다. 또한 무료 OpenAI 토큰을 빠르게 사용합니다. 따라서 처음에는 프로세스를 이해하기 위해 작은 문서(30-50페이지 또는 < 100MB 파일)로 시작하십시오.
코드 준비
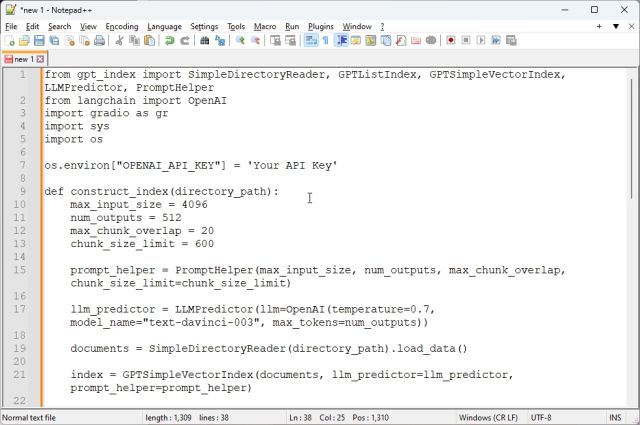
1. 이제 Notepad++(또는 선택한 코드 편집기)를 시작하고 아래 코드를 새 파일에 붙여넣습니다. 이번에도 큰 도움을 받았습니다 Google Colab의 armrrs PDF 파일과 호환되도록 코드를 수정하고 그 위에 Gradio 인터페이스를 만들었습니다.
from gpt_index import SimpleDirectoryReader, GPTListIndex, GPTSimpleVectorIndex, LLMPredictor, PromptHelper
from langchain import OpenAI
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = 'Your API Key'
def construct_index(directory_path):
max_input_size = 4096
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0.7, model_name="text-davinci-003", max_tokens=num_outputs))
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index.save_to_disk('index.json')
return index
def chatbot(input_text):
index = GPTSimpleVectorIndex.load_from_disk('index.json')
response = index.query(input_text, response_mode="compact")
return response.response
iface = gr.Interface(fn=chatbot,
inputs=gr.inputs.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Custom-trained AI Chatbot")
index = construct_index("docs")
iface.launch(share=True)
2. 코드 편집기에서 코드는 다음과 같습니다.
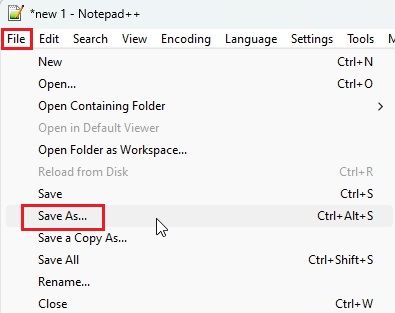
3. 그런 다음 상단 메뉴에서 “파일”을 클릭하고 드롭다운 메뉴에서 “다른 이름으로 저장…”을 선택합니다.
4. 그런 다음 파일 이름을 app.py로 설정하고 드롭다운 메뉴에서 “파일 형식”을 “모든 형식”으로 변경합니다. 그런 다음 “docs” 폴더를 만든 위치에 파일을 저장합니다(제 경우에는 데스크톱). 원하는 대로 이름을 변경할 수 있지만 .py가 추가되었는지 확인하십시오.
5. 아래 스크린샷과 같이 “docs” 폴더와 “app.py”가 같은 위치에 있는지 확인합니다. “app.py” 파일은 내부가 아닌 “docs” 폴더 외부에 있습니다.
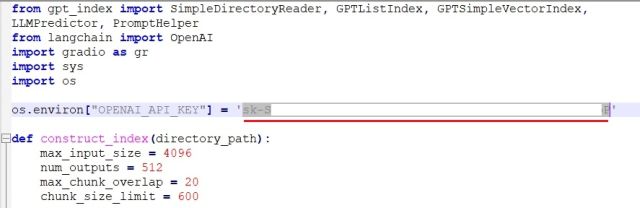
6. Notepad++에서 다시 코드로 돌아갑니다. 여기에서 귀하의 API 키를 위의 OpenAI 웹 사이트에서 생성된 것으로 교체하십시오.
7. 마지막으로 “Ctrl + S”를 눌러 코드를 저장합니다. 이제 코드를 실행할 준비가 되었습니다.
맞춤형 기술 자료로 ChatGPT AI 봇 만들기
1. 먼저 터미널을 열고 아래 명령어를 실행하여 바탕화면으로 이동합니다. 여기에 “docs” 폴더와 “app.py” 파일을 저장했습니다. 두 항목을 다른 위치에 저장한 경우 터미널을 통해 해당 위치로 이동하십시오.
cd Desktop
2. 이제 아래 명령을 실행하십시오. Linux 및 macOS 사용자는 python3을 사용해야 할 수 있습니다.
python app.py
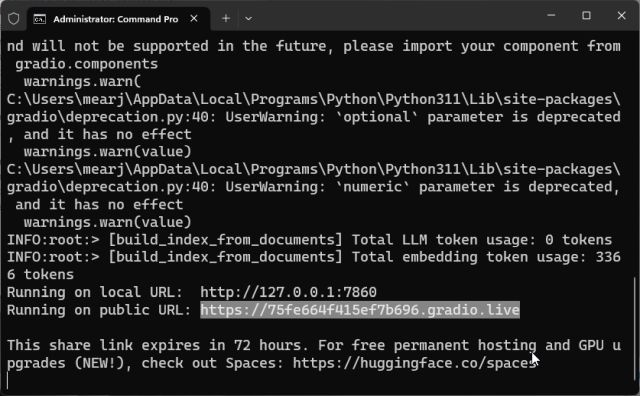
3. 이제 OpenAI LLM 모델을 사용하여 문서 분석을 시작하고 정보 색인 생성을 시작합니다. 파일 크기와 컴퓨터의 성능에 따라 문서를 처리하는 데 약간의 시간이 걸립니다. 완료되면 바탕 화면에 “index.json” 파일이 생성됩니다. 터미널에 출력이 표시되지 않더라도 걱정하지 마십시오. 여전히 데이터를 처리하고 있을 수 있습니다. 참고로 30MB 문서를 처리하는 데 걸리는 시간은 약 10초입니다.
4. LLM이 데이터를 처리하면 안전하게 무시할 수 있는 몇 가지 경고가 표시됩니다. 마지막으로 하단에 로컬 URL이 있습니다. 그것을 복사하십시오.
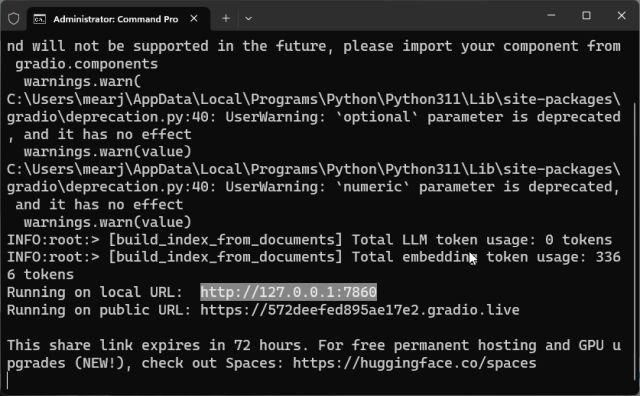
5. 이제 복사한 URL을 웹 브라우저에 붙여넣으면 됩니다. 맞춤형 학습 ChatGPT 기반 AI 챗봇이 준비되었습니다. 시작하려면 AI 챗봇에게 문서가 무엇인지 물어볼 수 있습니다.
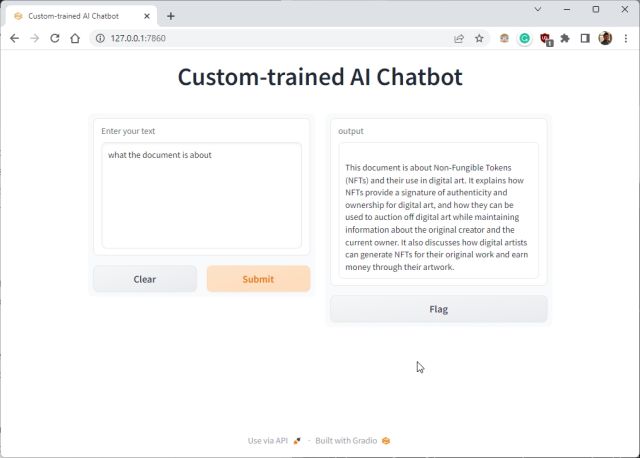
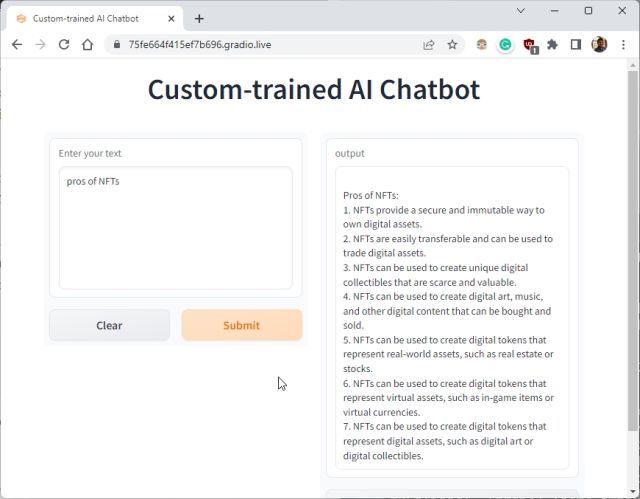
6. 추가 질문을 하면 ChatGPT 봇이 AI에 제공한 데이터에서 답변합니다. 이것이 자신의 데이터 세트로 맞춤형 학습 AI 챗봇을 구축하는 방법입니다. 이제 원하는 모든 종류의 정보를 기반으로 AI 챗봇을 훈련하고 생성할 수 있습니다. 가능성은 무한합니다.
7. 공개 URL을 복사하여 친구 및 가족과 공유할 수도 있습니다. 링크는 72시간 동안 작동하지만 서버 인스턴스가 컴퓨터에서 실행 중이므로 컴퓨터를 계속 켜두어야 합니다.
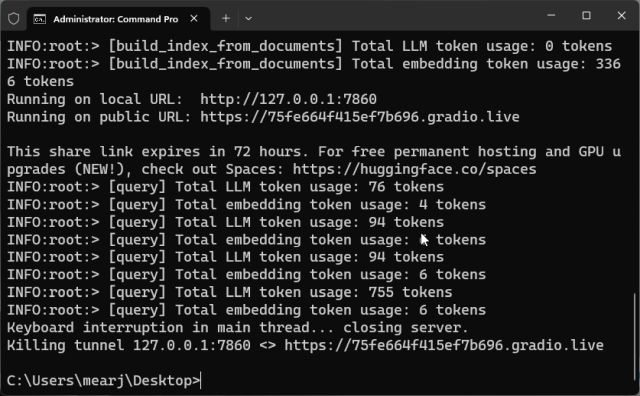
8. 맞춤형 학습 AI 챗봇을 중지하려면 터미널 창에서 “Ctrl + C”를 누릅니다. 작동하지 않으면 “Ctrl + C”를 다시 누르십시오.
9. AI 챗봇 서버를 다시 시작하려면 데스크톱 위치로 다시 이동하여 아래 명령을 실행하면 됩니다. 로컬 URL은 동일하지만 공용 URL은 서버를 다시 시작할 때마다 변경됩니다.
python app.py
10. 새로운 데이터로 AI 챗봇을 훈련시키려면 “docs” 폴더 내의 파일을 삭제하고 새 파일을 추가하십시오. 여러 파일을 추가할 수도 있지만 동일한 주제에 대한 정보를 제공하지 않으면 일관되지 않은 응답을 받을 수 있습니다.
11. 이제 터미널에서 코드를 다시 실행하면 새로운 “index.json” 파일이 생성됩니다. 여기에서 이전 “index.json” 파일이 자동으로 대체됩니다.
python app.py
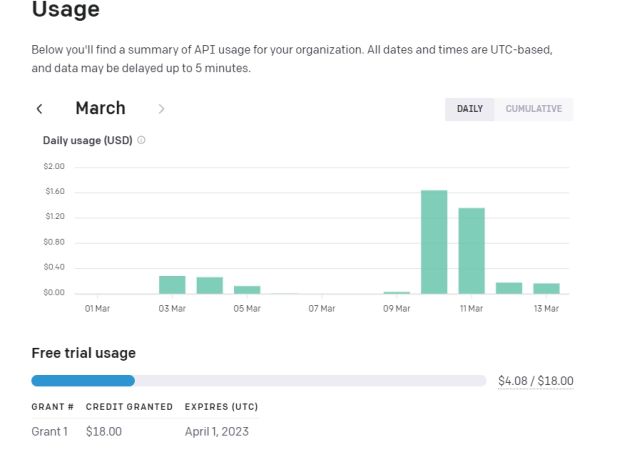
12. 토큰을 추적하려면 OpenAI의 온라인으로 이동하십시오. 계기반 무료 크레딧이 얼마나 남았는지 확인하세요.
13. 마지막으로 추가 사용자 지정을 위해 API 키 또는 OpenAI 모델을 변경하려는 경우가 아니면 코드를 건드릴 필요가 없습니다.
자신의 데이터를 사용하여 맞춤형 AI 챗봇 구축
이것이 맞춤형 지식 기반으로 AI 챗봇을 훈련시키는 방법입니다. 나는 이 코드를 사용하여 의학 서적, 기사, 데이터 테이블 및 오래된 기록 보관소의 보고서에 대해 AI를 훈련시켰으며 완벽하게 작동했습니다. 이제 OpenAI의 대규모 언어 모델과 ChatGPY를 사용하여 나만의 AI 챗봇을 만들어 보세요. 어쨌든 그것은 우리에게서 온 것입니다. 최고의 ChatGPT 대안을 찾고 있다면 링크된 기사로 이동하십시오. 그리고 Apple Watch에서 ChatGPT를 사용하려면 심층 튜토리얼을 따르십시오. 마지막으로 어떤 종류의 문제에 직면한 경우 아래 의견란에 알려주십시오. 우리는 확실히 당신을 돕기 위해 노력할 것입니다.