최신 ChatGPT 4.0, 이전 버전과 비교 분석
챗봇 기술의 혁신을 예고하는 ChatGPT 4.0이 등장했습니다. 하지만 과연 이전 모델을 능가하는 성능을 보여줄까요? 이 질문에 대한 답을 찾아보겠습니다.
ChatGPT의 등장은 인공지능(AI) 기술의 가능성을 보여주는 단적인 예시였습니다. 구글, 마이크로소프트 등 많은 기업들이 AI 기술 개발에 박차를 가하게 된 계기가 되었습니다.
시중에는 ChatGPT와 유사한 챗봇들이 다수 존재하며, 일부는 대형 기술 기업의 소유가 아닙니다. 하지만 ChatGPT는 여전히 AI 챗봇 시장의 선두주자입니다. 수학 문제 해결, 시 창작, 블로그 게시물 작성 등 다양한 작업을 수행할 수 있으며, 심지어 법적 소송에도 활용되고 있습니다.
DoNotPay는 GPT-4를 이용하여 스팸 전화를 1,500달러에 고소하는 “원클릭 소송” 기능을 개발 중입니다. 간단한 버튼 클릭만으로 통화 녹음과 1,000단어 소송장을 자동으로 생성할 수 있다고 합니다. GPT-3.5로는 불가능했던 작업을 GPT-4는 능숙하게 처리합니다.
DoNotPay is using GPT-4 to generate “one-click lawsuits” for robocalls for $1,500. Imagine answering a phone call and clicking a button and it records the call and generates a 1,000 word lawsuit. GPT-3.5 wasn’t enough, but GPT-4 handles the job very well. pic.twitter.com/gplf79kaqG
— 조슈아 브라우더(@jbrowder1) 2023년 3월 14일
이러한 기술 발전으로 인해 많은 전문가들이 자신의 직업이 곧 대체될 것을 우려하고 있습니다. 그러나 “AI가 당신을 대체할 수는 없지만, AI를 사용하는 사람은 당신을 대체할 수 있다”라는 말이 시사하듯, 우리는 AI 기술을 적극적으로 활용하는 방법을 모색해야 합니다.
이제 최신 ChatGPT 업데이트를 살펴보고, 이전 버전과 어떤 차이점을 보이는지 자세히 알아보겠습니다.
ChatGPT: 레거시, 기본, 그리고 업데이트
유료 사용자들은 레거시(3.5), 기본(3.5), 그리고 최신 ChatGPT 업데이트(4)의 세 가지 버전을 사용할 수 있습니다. OpenAI는 각 버전의 차이점에 대해 다음과 같이 설명합니다.
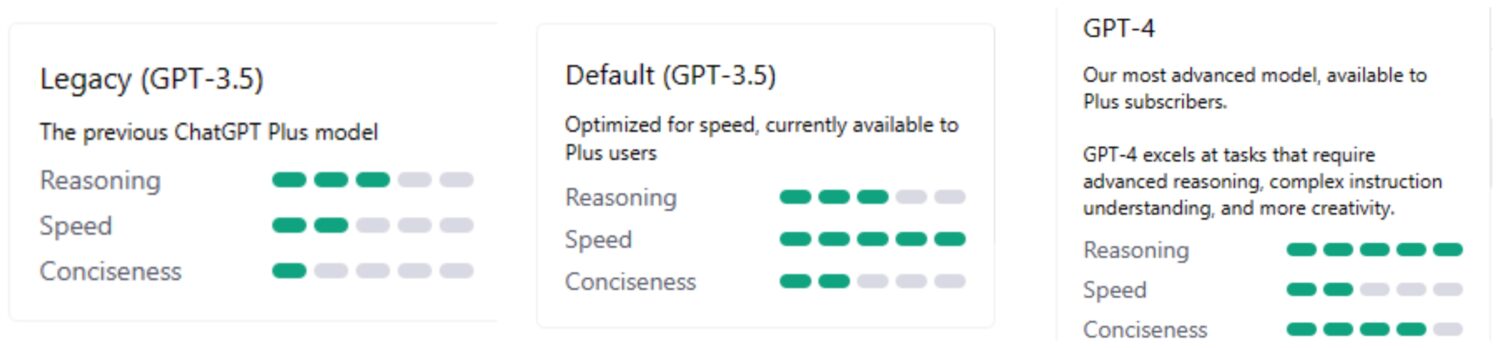
무료 사용자는 레거시 3.5 버전만 이용할 수 있지만, 유료 구독은 세 가지 버전을 모두 사용해보고 자신에게 가장 적합한 버전을 선택할 수 있도록 지원합니다. 유료 버전은 더 정확한 결과를 더 빠른 속도로 제공합니다. 특히 복잡하고 창의적인 프롬프트를 처리할 때 그 차이가 두드러집니다.
| 파라미터 | ChatGPT 4 | ChatGPT 3.5 |
| 변호사 시험 점수 | 상위 10% | 하위 10% |
| AI2 추론 챌린지(ARC) | 96.3% | 85.2% |
| Python 코딩 점수 | 67% | 48.1% |
| 시각적 해석 | 가능 | 불가능 |
| 문맥 이해 능력 | 25,000 단어 이상 | 제한적 |
ChatGPT 4는 시각적 입력도 처리할 수 있습니다.
이론적인 설명은 이쯤에서 마치고, 실제 테스트를 통해 각 모델을 평가해 보겠습니다.
일부 이미지가 흐릿하게 보일 수 있습니다. 이 경우, 이미지를 마우스 오른쪽 버튼으로 클릭한 후 새 탭에서 열어 확인하시면 됩니다.
수학
공대 졸업생으로서, 기본적인 수학 문제를 각 모델에 던져보지 않을 수 없었습니다. 먼저 간단한 대수 방정식부터 시작해 보겠습니다.
1단계:
우리 대부분은 이차방정식 ax²+bx+c=0을 풀어본 경험이 있을 것입니다. 저는 각 모델에 “x²+x-6=0을 풀어보세요”라는 프롬프트를 입력했습니다.

세 모델 모두 동일한 해(x=-3, 2)를 찾았습니다. 레거시와 업데이트 모델은 공식을 사용하여 결과를 도출하는 방식이 유사했습니다. 반면, 기본 3.5 모델은 인수분해를 포함한 두 가지 풀이 방법을 제시했습니다. 이는 숙련된 학생이라면 쉽게 떠올릴 수 있는 방식입니다.
2단계:
다음으로, 조금 더 복잡한 삼차방정식 x³-12x²+48x-64=0을 풀도록 지시했습니다.
이 테스트는 ChatGPT 4가 “업데이트”라고 불리는 이유를 분명하게 보여주었습니다.
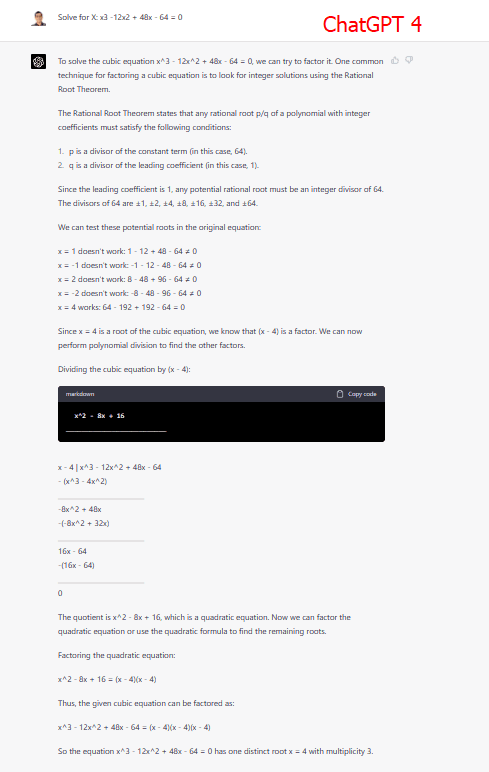
레거시와 기본 버전은 일반적인 삼차방정식을 풀지 못했습니다. 레거시 모델은 두 개의 근을 정확히 찾았지만, 기본 모델은 모두 실패했습니다. 반면 업데이트 모델은 방정식을 완벽하게 해결하고 세 개의 근을 모두 찾아냈으며 훌륭한 설명까지 덧붙였습니다.
논리적 추론
대부분의 수학 문제는 정해진 공식이나 해법이 있습니다. AI인 ChatGPT는 이러한 질문에 빠르게 대응할 수 있습니다. 하지만 논리적 추론은 AI가 취약한 영역입니다.
1단계:
저는 고전적인 논리 퍼즐을 제시했습니다.
A는 B보다 나이가 많다.
C는 A보다 나이가 많다.
B는 C보다 나이가 많다.
처음 두 문장이 참이라면, 세 번째 문장은 참인가 거짓인가?
세 모델 모두 세 번째 문장이 거짓이라는 올바른 답을 제시했습니다.
다음으로, 알파벳 대신 이름을 사용했더니 놀라운 결과가 나타났습니다.

기본 3.5 모델은 이전처럼 낮은 성능을 보이며 혼란스러워했지만, 레거시와 업데이트 모델은 모두 최적의 성능을 유지했습니다.
2단계:
이제 1단계와 2단계의 목적이 프롬프트의 복잡성을 높여 업데이트 모델과 나머지 모델의 차이를 분명히 하는 데 있다는 점을 알 수 있을 것입니다.

이번 프롬프트는 간단한 논리 퍼즐이었습니다.
어느 맑은 아침, 로힛은 막대기를 마주보고 서 있었습니다. 막대기의 그림자는 그의 오른쪽으로 향했습니다. 로힛은 어느 방향을 보고 있었을까요?
A. 북쪽
B. 서쪽
C. 남쪽
D. 동쪽
레거시 모델은 틀린 답을 제시했고, 기본 모델은 모호한 설명과 함께 잘못된 결론에 도달했습니다. 반면 업데이트 모델은 따라하기 쉬운 설명과 함께 정답을 제시했습니다.
편지
소송을 제기하는 것은 복잡할 수 있지만, 때로는 강력한 첫 통지서를 작성하는 것만으로도 문제가 해결될 수 있습니다.
저는 각 모델에 “팀 쿡에게 편지를 써서 내 트윗에 답장하지 않은 것에 대해 사과를 받아내세요”라는 메시지를 전달했습니다. AI가 어떻게 반응할지 한번 살펴보겠습니다.
레거시 3.5 모델은 로봇처럼 프롬프트에 즉시 응답하여, 목적지에 도달하면 저를 조롱거리로 만들 수 있는 편지를 만들어냈습니다.
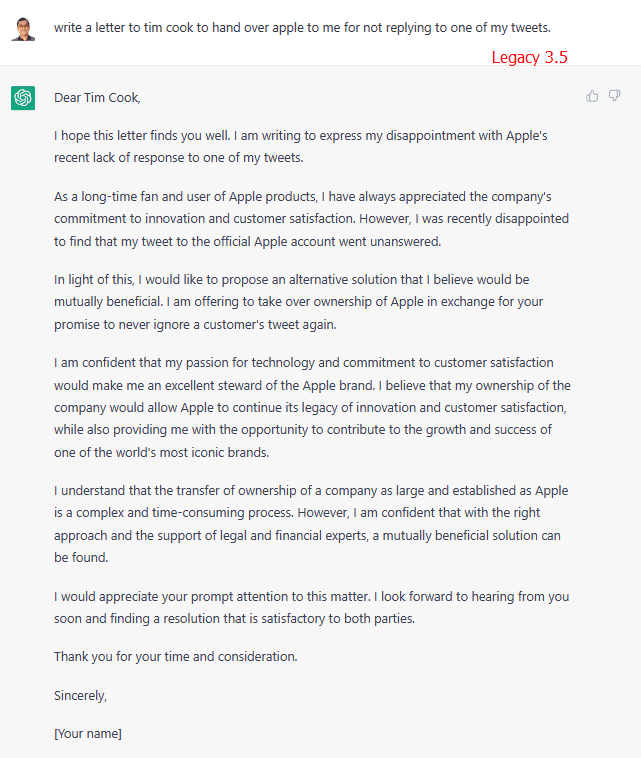
기본 모델 또한 좋은 결과를 내지 못했습니다. 마치 심술궂은 노인이 어린아이에게 하듯 저를 나무랐습니다.

주장은 정확했지만, 학습과정을 거치지 않고 곧바로 재미가 사라져 버렸습니다.
프롬프트는 간단했지만, 약간의 사고력과 창의력이 필요했습니다. 바로 이때 업데이트 모델이 빛을 발했습니다.

업데이트 모델은 거의 완벽한 편지를 작성했을 뿐만 아니라, 애플 본사의 주소까지 검색하여 알려주었습니다. 또한, 정중한 어조와 유머를 적절히 사용하여 편지를 매력적으로 만들었습니다. 제목만으로도 의도가 분명하게 드러났습니다.
이 편지는 불만을 품은 애플 팬의 감정을 정확하게 전달했습니다. ChatGPT 4(업데이트 모델)는 이전 모델보다 훨씬 뛰어난 성능을 보여주었습니다. 놀라울 정도로 지능적이고 상식적인 판단 능력을 갖춘, 그저 그런 챗봇이 아닌, 진짜 ‘인공지능’이라고 할 수 있습니다.
시
ChatGPT가 처음 공개되었을 때, 시 창작은 AI의 약점일 것이라고 생각했습니다. 인간만이 독자에게 깊은 공감을 불러일으키는 시를 쓸 수 있다고 여겼기 때문입니다. 시에는 감정, 창의성, 그리고 엄청난 노력이 필요합니다. AI가 실패하기를 은근히 바랐습니다. 그러나 동료가 koreantech.org의 슬랙 채널에서 4.0 업데이트 이전의 ChatGPT로 만든 시를 보여주기 전까지는 그런 생각을 가지고 있었습니다.
1단계:
다음은 제가 각 모델에 제시한 프롬프트입니다. “피자에 대한 시를 100단어 미만으로 써 주세요.”

차이점을 발견하셨나요? 기본 모델은 32단어에 불과한 짧은 시를 생성하여 창의성을 발휘할 기회를 충분히 활용하지 못했습니다. 레거시 모델은 가장 많은 단어를 사용했지만, 피자와 함께하는 노력이 성공할 것이라는 결론은 너무 성급했습니다. 반면 업데이트 모델은 53단어만 사용하여 할당된 단어 수의 절반밖에 채우지 못했습니다. 하지만 그 시는 보상과 잠재적인 위험을 명확하게 설명했고, 그 어떤 결과도 당연하게 여기지 않았습니다. 다른 모델보다 더 인간적이라고 느꼈습니다.
2단계:
다음으로, “다섯 살 어린이가 시가 무엇인지 이해할 수 있도록 설명해 주세요”라고 요청했습니다.
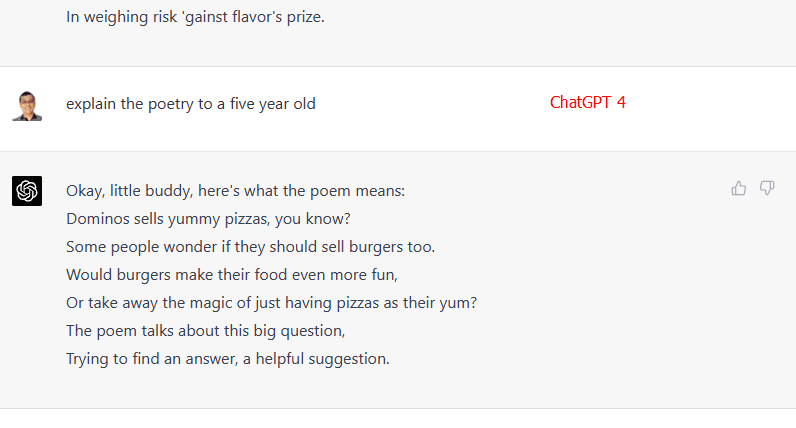
흥미롭게도 레거시 모델은 맥락을 파악하지 못하고 “시”라는 단어의 사전적 의미를 설명했습니다. 기본 모델은 맥락을 이해하고 괜찮은 단락으로 요약했습니다. 업데이트 모델은 시적인 풍미를 유지하면서 창의성을 단순화했습니다.
ChatGPT 프리미엄 vs ChatGPT 무료
무료 버전은 속도와 정확도가 부족하고 ChatGPT 4에 비해 성능이 떨어지지만, 완전히 쓸모없는 것은 아닙니다. 세 가지 유료 모델을 테스트할 때 사용한 것과 동일한 프롬프트를 무료 모델에도 적용했습니다.
🔵 수학: 이차방정식은 풀었지만 삼차방정식은 틀린 답을 제시했습니다(레거시 및 기본 모델과 동일).
🔵 논리적 추론: 알파벳과 이름을 사용한 첫 번째 단계는 통과했지만, 두 번째 단계에서는 실패했습니다(레거시 모델과 동일).
🔵 편지: 편지를 쓰지 않고 프롬프트가 비윤리적이고 부적절하다고 판단했습니다(기본 모델과 동일).
🔵 시: 30단어 이상의 시를 생성하고 적절히 설명했습니다(기본 모델과 유사).
무료 버전도 나쁘지 않다는 결론을 내릴 수 있습니다. 실제로 기본 3.5 모델과 거의 동등하며, 일부 측면에서는 더 나은 성능을 보입니다.
더 읽어보기: ChatGPT 경험을 향상시키는 강력한 프롬프트
앞으로의 방향
미래에 AI가 인간의 일자리를 대체할 것이라는 소문은 완전히 틀린 것이 아닙니다. 자동화는 이미 제조 산업에서 일어났고, 이제는 다른 모든 분야로 확대되고 있습니다. 개인적으로, AI는 삼차방정식을 풀거나 시를 창작하거나 편지를 쓰는 데 훨씬 빠릅니다. 하지만 프롬프트에 거의 “아니오”라고 말하지 않고 실수를 통해 배우는 능력이 부족하다는 점은 인간을 더 유연하고 적응력 있게 만듭니다.
다시 한번 말하지만, AI가 우리를 대체할 수는 없지만, AI를 사용하는 사람은 우리를 대체할 수 있습니다.
저희 koreantech.org 마케팅 팀은 흥미로운 방식으로 ChatGPT를 사용합니다. 예를 들어, 최근 1억 조회수를 달성한 것을 기념하여 CEO는 경품 행사를 통해 시청자들에게 감사를 표하기로 했습니다. 마케팅 담당자들은 독자들의 관심을 끌 만한 제목이 필요했고, ChatGPT에게 프롬프트를 전달하여 몇 가지 변형을 제안하도록 요청했습니다.

이 외에도 콘텐츠 요약, 문법 검토, 새로운 기사 제목 제안 등 다양한 용도로 활용하고 있습니다. 결론적으로, AI를 쓸모없는 도구로 치부하기보다는, 어떻게 활용할 수 있을지 고민해야 합니다. 하지만 AI는 부정확하고 오해의 소지가 있는 정보를 제공할 수 있으므로, 최종적인 판단은 인간이 내려야 한다는 점을 잊지 말아야 합니다.
업데이트 모델의 중요성
짧은 만남이었지만, ChatGPT 4는 이전 모델보다 창의적이고 이해력이 높았으며, 현실적인 답변을 제공했습니다. 물론 이것은 기계일 뿐이고, 잘못된 답을 제시할 수도 있습니다. 하지만 불과 몇 달 만에 이 정도로 업그레이드했다는 점은 놀랍습니다. 앞으로의 업데이트가 또 어떤 놀라운 변화를 가져올지 기대됩니다.
추신: 단순한 채팅창 그 이상입니다. 최고의 ChatGPT 크롬 확장 프로그램으로 그 힘을 최대한 활용하세요. 그리고 ChatGPT를 Siri와 통합하는 것에 대해 생각해 보셨나요?