AWS Logs Insights를 활용하여 AWS 서비스 로그에서 대시보드 지표를 쿼리하는 방법
AWS의 모든 서비스는 작업 처리 과정을 CloudWatch 로그 그룹 내 파일에 기록하며, 이 로그 그룹들은 보통 서비스 이름과 동일하게 명명되어 쉽게 식별할 수 있습니다. 이러한 로그 파일에는 서비스의 시스템 메시지나 일반적인 상태 정보가 기본적으로 저장됩니다.
하지만 사용자는 기본 로그 메시지 외에도 추가적인 사용자 정의 로그 메시지를 기록할 수 있습니다. 이러한 로그를 신중하게 생성하면, 유용한 CloudWatch 대시보드를 구성하는 데 중요한 역할을 할 수 있습니다.
작업 처리 과정에 대한 세부 정보를 제공하기 위해 메트릭과 구조화된 정보를 활용할 수 있습니다. 서비스 시스템 정보와 같은 표준 위젯을 포함하는 것뿐만 아니라 사용자 정의 위젯이나 메트릭으로 집계된 콘텐츠를 추가하여 기능을 확장할 수 있습니다.
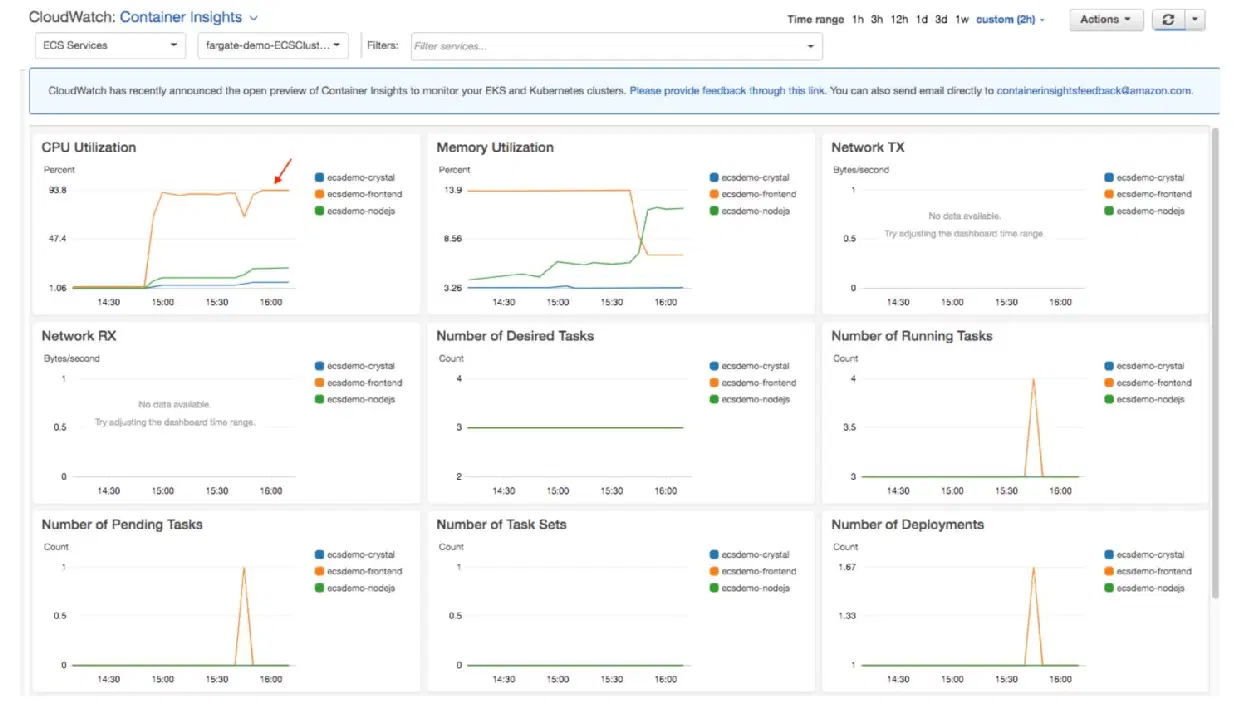
로그 파일 쿼리
출처: aws.amazon.com
AWS CloudWatch Log Insights를 이용하면, AWS 리소스에서 생성되는 로그 데이터를 실시간으로 검색하고 분석할 수 있습니다. 분석 결과는 데이터베이스 형태처럼 볼 수 있으며, 대시보드에서 정의된 쿼리는 해당 대시보드를 방문할 때마다 실행되거나, 과거의 특정 시간 범위에 맞춰 쿼리 결과를 보여주도록 설정할 수 있습니다.
로그 데이터 검색 및 분석에는 CloudWatch Logs Insights라는 쿼리 언어가 사용됩니다. 이 언어는 SQL의 하위 집합을 기반으로 하며, 로그 데이터를 검색하고 필터링하는 데 사용됩니다. 특정 로그 이벤트, 사용자 지정 로그 텍스트, 키워드 등을 검색할 수 있으며, 특정 필드를 기준으로 로그 데이터를 필터링할 수도 있습니다. 또한, 하나 이상의 로그 파일 내에서 로그 데이터를 집계하여 요약된 지표와 시각화 자료를 만들 수 있습니다.
쿼리가 실행되면 CloudWatch Log Insights는 로그 그룹의 데이터를 검색한 후 쿼리 조건과 일치하는 파일의 텍스트를 반환합니다.
로그 파일 쿼리 예시
개념 이해를 돕기 위해 몇 가지 기본적인 쿼리 예를 살펴보겠습니다.
대부분의 서비스는 주요 서비스 오류를 자동으로 기록합니다. 이처럼 오류 이벤트에 대한 사용자 지정 로그를 따로 만들지 않아도, 간단한 쿼리를 통해 지난 한 시간 동안 발생한 애플리케이션 로그의 오류 횟수를 파악할 수 있습니다.
fields @timestamp, @message | filter @message like /ERROR/ | stats count() by bin(1h)
또는 지난 하루 동안 API 평균 응답 시간을 모니터링하려면 다음과 같은 쿼리를 사용합니다.
fields @timestamp, @message | filter @message like /API response time/ | stats avg(response_time) by bin(1d)
CPU 사용량과 같은 지표는 서비스에서 CloudWatch에 기본적으로 기록하는 정보이므로, 이와 같은 데이터도 수집할 수 있습니다.
fields @timestamp, @message | filter @message like /CPUUtilization/ | stats avg(value) by bin(1h)
이러한 쿼리는 특정 사용 사례에 맞게 조정할 수 있으며, CloudWatch 대시보드에서 맞춤형 지표 및 시각화 자료를 생성하는 데 활용할 수 있습니다. 대시보드에 위젯을 추가하고, 위젯 내부에 쿼리 코드를 입력하여 표시할 내용을 정의하는 방식으로 작동합니다.
다음은 CloudWatch 대시보드에서 활용할 수 있으며, Log Insights의 내용으로 채워질 수 있는 몇 가지 위젯 유형입니다.
- 텍스트 위젯 – CloudWatch Insights 쿼리 출력과 같은 텍스트 기반 정보를 표시합니다.
- 로그 쿼리 위젯 – 애플리케이션 로그의 오류 횟수와 같은 CloudWatch Insights 로그 쿼리 결과를 표시합니다.
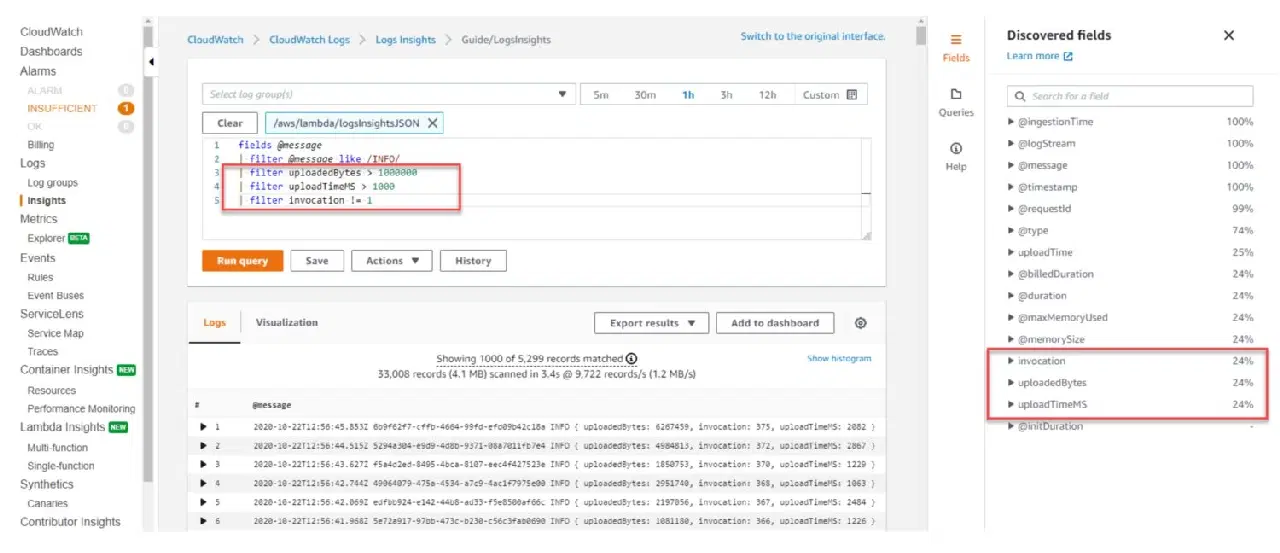
대시보드에 유용한 로그 정보 생성 방법
출처: aws.amazon.com
CloudWatch 대시보드에서 CloudWatch Insights 쿼리를 효과적으로 사용하려면, 시스템 내 각 서비스에 대한 CloudWatch 로그를 생성할 때 몇 가지 모범 사례를 따르는 것이 좋습니다. 다음은 몇 가지 유용한 팁입니다.
#1. 구조화된 로깅 활용
사전에 정의된 스키마를 기반으로 데이터를 구조화된 형식으로 기록하는 로깅 방식을 준수해야 합니다. 이렇게 하면 CloudWatch Insights 쿼리를 사용하여 로그 데이터를 더 쉽게 검색하고 필터링할 수 있습니다.
이는 아키텍처 플랫폼의 다양한 서비스에서 로그 형식을 표준화하는 것을 의미합니다. 개발 표준에 정의되어 있으면 효율성을 높일 수 있습니다.
예를 들어 특정 데이터베이스 테이블 관련 문제가 발생했을 때, "[TABLE_NAME] 경고/오류: <메시지>"와 같은 시작 메시지로 기록되도록 설정할 수 있습니다.
또는 "[FULL/DELTA]"와 같은 접두어를 사용하여 전체 데이터 작업과 부분 데이터 작업을 구분함으로써 특정 데이터 처리와 관련된 메시지만을 선택할 수 있습니다.
특정 소스 시스템의 데이터를 처리할 때, 해당 시스템 이름을 각 로그 항목의 접두어로 설정하면, 나중에 로그 파일에서 특정 메시지를 필터링하고 이에 대한 지표를 생성하기가 훨씬 쉬워집니다.
출처: aws.amazon.com
#2. 일관된 로그 형식 사용
모든 AWS 리소스에 대해 일관된 로그 형식을 사용하면, CloudWatch Insights 쿼리를 통해 로그 데이터를 더욱 쉽게 검색하고 필터링할 수 있습니다.
이전 내용과 밀접하게 연관되어 있지만, 핵심은 로그 형식이 표준화될수록 로그 데이터 사용이 더욱 용이해진다는 점입니다. 개발자들은 이 형식을 신뢰하고 직관적으로 활용할 수 있게 됩니다.
대부분의 프로젝트가 로깅 관련 표준을 무시한다는 사실은 안타깝습니다. 심지어 많은 프로젝트에서 사용자 정의 로그를 전혀 생성하지 않는 경우도 많습니다. 이는 놀랍지만 매우 흔한 현실입니다.
예외 처리 없이 어떻게 운영이 가능한지 의문을 갖게 되는 경우가 종종 있습니다. 혹시 예외 처리를 시도한 사람이 있다면, 제대로 처리하지 못했을 가능성이 큽니다.
따라서 일관된 로그 형식은 매우 강력한 자산이지만, 많은 조직에서 이를 갖추고 있지 못합니다.
#3. 관련 메타데이터 포함
로그 데이터에 타임스탬프, 리소스 ID, 오류 코드와 같은 메타데이터를 포함하면, CloudWatch Insights 쿼리를 사용하여 로그 데이터를 더 쉽게 검색하고 필터링할 수 있습니다.
#4. 로그 회전 활성화
로그 데이터가 과도하게 커지는 것을 방지하고, CloudWatch Insights 쿼리를 사용하여 로그 데이터를 더욱 쉽게 검색하고 필터링하려면 로그 회전을 활성화해야 합니다.
로그 데이터가 없는 것도 문제이지만, 구조화되지 않은 로그 데이터가 너무 많은 것도 마찬가지로 문제입니다. 데이터를 활용할 수 없다면 없는 것과 마찬가지입니다.
#5. CloudWatch Logs 에이전트 활용
사용자 정의 로그 시스템 구축을 원치 않는다면, 최소한 CloudWatch Logs 에이전트를 사용하십시오. 이 에이전트는 AWS 리소스에서 CloudWatch Logs로 로그 데이터를 자동으로 전송하여, CloudWatch Insights 쿼리를 통해 로그 데이터 검색 및 필터링을 더 쉽게 만듭니다.
더 복잡한 인사이트 쿼리 예시
CloudWatch Insights 쿼리는 단순한 두 줄 이상의 코드로 구성될 수 있습니다.
fields @timestamp, @message | filter @message like /ERROR/ | filter @message not like /404/ | parse @message /.*[(?<timestamp>[^]]+)].*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
이 쿼리는 다음 작업을 수행합니다.
- "ERROR" 문자열을 포함하지만 "404"를 포함하지 않는 로그 이벤트를 선택합니다.
- 로그 메시지를 구문 분석하여 타임스탬프, HTTP 메서드, 경로, 상태 코드 및 응답 시간을 추출합니다.
- HTTP 메서드, 경로, 상태 코드, 시간 조합에 대한 평균 응답 시간 및 로그 이벤트 수를 계산합니다.
- 결과를 내림차순으로 정렬합니다.
- 출력을 상위 20개 결과로 제한합니다.
이 쿼리는 애플리케이션에서 가장 흔한 오류를 식별하고, HTTP 메서드, 경로, 상태 코드 조합에 대한 평균 응답 시간을 추적합니다. 분석 결과를 활용하여 CloudWatch 대시보드에서 맞춤형 지표와 시각화 자료를 생성하여 웹 애플리케이션의 성능을 모니터링하고 문제를 해결할 수 있습니다.
다음은 Amazon S3 서비스 메시지를 쿼리하는 또 다른 예시입니다.
fields @timestamp, @message | filter @message like /REST.API.REQUEST/ | parse @message /.*"(?<method>[^s]+)s+(?<path>[^s]+).*" (?<status>d+) (?<response_time>d+)/ | stats avg(response_time) as avg_response_time, count() as count by bin(1h), method, path, status | sort count desc | limit 20
- 쿼리는 "REST.API.REQUEST" 문자열이 포함된 로그 이벤트를 선택합니다.
- 로그 메시지를 구문 분석하여 HTTP 메서드, 경로, 상태 코드, 응답 시간을 추출합니다.
- HTTP 메서드, 경로, 상태 코드 조합에 대한 평균 응답 시간과 로그 이벤트 수를 계산하고 결과를 개수별 내림차순으로 정렬합니다.
- 출력을 상위 20개 결과로 제한합니다.
이 쿼리 결과로, HTTP 메서드, 경로, 상태 코드 조합별 평균 응답 시간을 보여주는 CloudWatch 대시보드에 그래프를 생성할 수 있습니다.
대시보드 구축
CloudWatch Insights 로그 쿼리 결과를 기반으로 CloudWatch 대시보드의 지표 및 시각화 자료를 구성하려면, CloudWatch 콘솔로 이동하여 대시보드 마법사를 따라 콘텐츠를 구축할 수 있습니다.
다음은 CloudWatch 대시보드의 코드 예시이며, CloudWatch Insights 쿼리 데이터로 채워진 지표를 포함합니다.
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 0,
"width": 12,
"height": 6,
"properties": {
"metrics": [
[
"AWS/EC2",
"CPUUtilization",
"InstanceId",
"i-0123456789abcdef0",
{
"label": "CPU Utilization",
"stat": "Average",
"period": 300
}
]
],
"view": "timeSeries",
"stacked": false,
"region": "us-east-1",
"title": "EC2 CPU Utilization"
}
},
{
"type": "log",
"x": 0,
"y": 6,
"width": 12,
"height": 6,
"properties": {
"query": "fields @timestamp, @message
| filter @message like /ERROR/
| stats count() by bin(1h)
",
"region": "us-east-1",
"title": "Application Errors"
}
}
]
}
이 CloudWatch 대시보드에는 두 가지 위젯이 포함되어 있습니다.
- 시간 경과에 따른 EC2 인스턴스의 평균 CPU 사용률을 보여주는 지표 위젯입니다. CloudWatch Insights 쿼리가 위젯 내용을 채우며, 특정 EC2 인스턴스의 CPU 사용률 데이터를 5분 간격으로 집계합니다.
- 시간 경과에 따른 애플리케이션 오류 수를 보여주는 로그 위젯입니다. "ERROR" 문자열을 포함하는 로그 이벤트를 선택하고 시간별로 집계합니다.
JSON 형식 파일에는 대시보드 및 지표에 대한 정의가 포함되어 있으며, 인사이트 쿼리 자체도 속성으로 포함됩니다.
이 코드를 가져와 필요한 모든 AWS 계정에 배포할 수 있습니다. 서비스와 로그 메시지가 모든 AWS 계정 및 단계에서 일관성을 유지한다고 가정하면, 대시보드 소스 코드를 수정하지 않아도 모든 계정에서 대시보드를 사용할 수 있습니다.
마지막 말
견고한 로깅 구조를 구축하는 것은 시스템 안정성을 위한 미래 투자입니다. 이를 통해 더 큰 목표를 달성할 수 있으며, 부수적으로 지표와 시각화 자료가 포함된 유용한 대시보드를 확보할 수 있습니다.
개발, 테스트, 프로덕션 팀 모두 동일한 솔루션의 혜택을 누릴 수 있으며, 약간의 추가 작업만으로 모두에게 유익한 결과를 얻을 수 있습니다.
다음에는 최고의 AWS 모니터링 도구를 확인해 보세요.