Apache Hive와 Apache Impala: 주요 차이점
빅데이터 분석 도구 소개: Apache Hive와 Impala 비교
빅데이터 분석을 시작하는 사용자라면 Apache의 다양한 도구들을 접하게 될 것입니다. 하지만 이 많은 도구들 속에서 어떤 것을 선택해야 할지 혼란스러울 수 있습니다.
이 글에서는 Apache Hive와 Impala가 무엇이며, 이 둘의 차이점을 명확하게 설명하여 여러분의 혼란을 해소하고자 합니다.
아파치 하이브 (Apache Hive)
Apache Hive는 Apache Hadoop 플랫폼을 위한 SQL 기반 데이터 접근 인터페이스입니다. Hive를 사용하면 SQL과 유사한 구문을 통해 데이터를 쿼리하고, 집계하고, 분석할 수 있습니다.
Hive는 HDFS 파일 시스템에 저장된 데이터에 대한 읽기 액세스 방식을 제공하여, 데이터를 마치 일반적인 테이블이나 관계형 데이터베이스처럼 다룰 수 있도록 합니다. HiveQL 쿼리는 MapReduce 작업을 위한 Java 코드로 변환됩니다.
Hive 쿼리 언어인 HiveQL은 SQL 언어를 기반으로 하지만, SQL-92 표준을 완벽하게 지원하지는 않습니다.
그러나 HiveQL은 사용자 정의 스칼라 함수(UDF), 집계 함수(UDAF), 테이블 함수(UDTF) 등을 통해 확장할 수 있어, 필요에 따라 프로그래머가 쿼리를 사용자화할 수 있습니다.
Apache Hive의 작동 방식
Apache Hive는 HiveQL로 작성된 프로그램을 하나 이상의 MapReduce, Apache Tez 또는 Apache Spark 작업으로 변환합니다. 이러한 작업들은 Hadoop에서 실행될 수 있는 다양한 처리 엔진입니다. Hive는 데이터를 HDFS(Hadoop Distributed File System) 파일 형태로 구성하고, 클러스터 내에서 작업을 실행하여 결과를 생성합니다.
Apache Hive 테이블은 관계형 데이터베이스와 유사하게 데이터를 구성하며, 가장 큰 단위부터 가장 세분화된 단위 순으로 구성됩니다. 데이터베이스는 파티션으로 나뉘고, 파티션은 다시 "버킷"으로 분할될 수 있습니다.
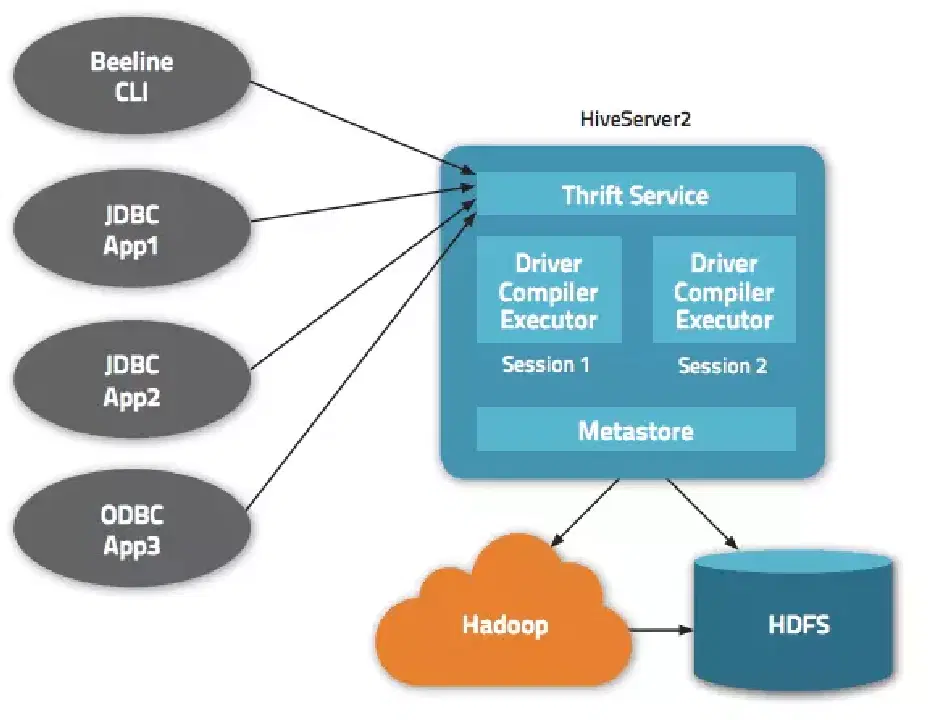
데이터는 HiveQL을 통해 접근할 수 있습니다. 각 데이터베이스 내에서 데이터는 번호가 매겨지고, 각 테이블은 HDFS 디렉토리에 대응됩니다.
Apache Hive 아키텍처 내에서는 웹 인터페이스, CLI, 또는 외부 클라이언트 등 다양한 인터페이스를 사용할 수 있습니다.
특히, “Apache Hive Thrift” 서버를 사용하면 원격 클라이언트가 여러 프로그래밍 언어를 사용하여 Apache Hive에 명령과 요청을 보낼 수 있습니다. Apache Hive의 중앙 디렉토리는 모든 정보를 담고 있는 “메타스토어”입니다.
Hive를 작동시키는 엔진을 “드라이버”라고 부르며, 최적의 실행 계획을 수립하기 위한 컴파일러와 옵티마이저를 함께 제공합니다.
보안은 Hadoop에서 제공합니다. 클라이언트와 서버 간 상호 인증을 위해 Kerberos를 사용하며, Apache Hive에서 생성된 새로운 파일에 대한 권한은 HDFS에 의해 관리되어 사용자, 그룹, 또는 기타 인증을 허용합니다.
하이브의 주요 특징
- Hadoop과 Spark 컴퓨팅 엔진을 모두 지원합니다.
- HDFS를 사용하여 데이터 웨어하우스 역할을 합니다.
- MapReduce 기반의 ETL 작업을 지원합니다.
- HDFS 덕분에 Hadoop과 유사한 내결함성을 제공합니다.
Apache Hive의 장점
Apache Hive는 쿼리 및 데이터 분석에 매우 적합한 솔루션입니다. Hive를 통해 얻을 수 있는 양질의 통찰력은 경쟁 우위를 확보하고 시장 수요에 빠르게 대응할 수 있도록 돕습니다.
Apache Hive의 가장 큰 장점 중 하나는 "SQL 친화적인" 언어와 사용 편의성입니다. 또한, 디스크에서 데이터를 읽거나 번호를 매기는 과정이 필요하지 않아 데이터 초기 삽입 속도가 빠릅니다.
HDFS에 데이터를 저장하기 때문에 Apache Hive는 최대 수백 페타바이트에 달하는 대용량 데이터 세트를 저장할 수 있습니다. 이 솔루션은 기존 데이터베이스보다 훨씬 뛰어난 확장성을 제공합니다. 클라우드 서비스라는 점을 고려할 때, Apache Hive는 사용자가 워크로드 변화에 따라 가상 서버를 신속하게 시작할 수 있도록 합니다.
보안 측면에서도 Hive는 문제가 발생할 경우 워크로드를 복제하여 복구하는 기능을 제공하여 성능을 향상시킵니다. 마지막으로, 시간당 최대 100,000개의 요청을 처리할 수 있는 뛰어난 작업 처리 능력을 자랑합니다.
아파치 임팔라 (Apache Impala)
Apache Impala는 C++로 작성되었으며, Apache 2.0 라이선스 하에 배포되는 대규모 병렬 SQL 쿼리 엔진입니다. Apache Hadoop에 저장된 데이터에 대한 실시간 SQL 쿼리 실행을 제공합니다.
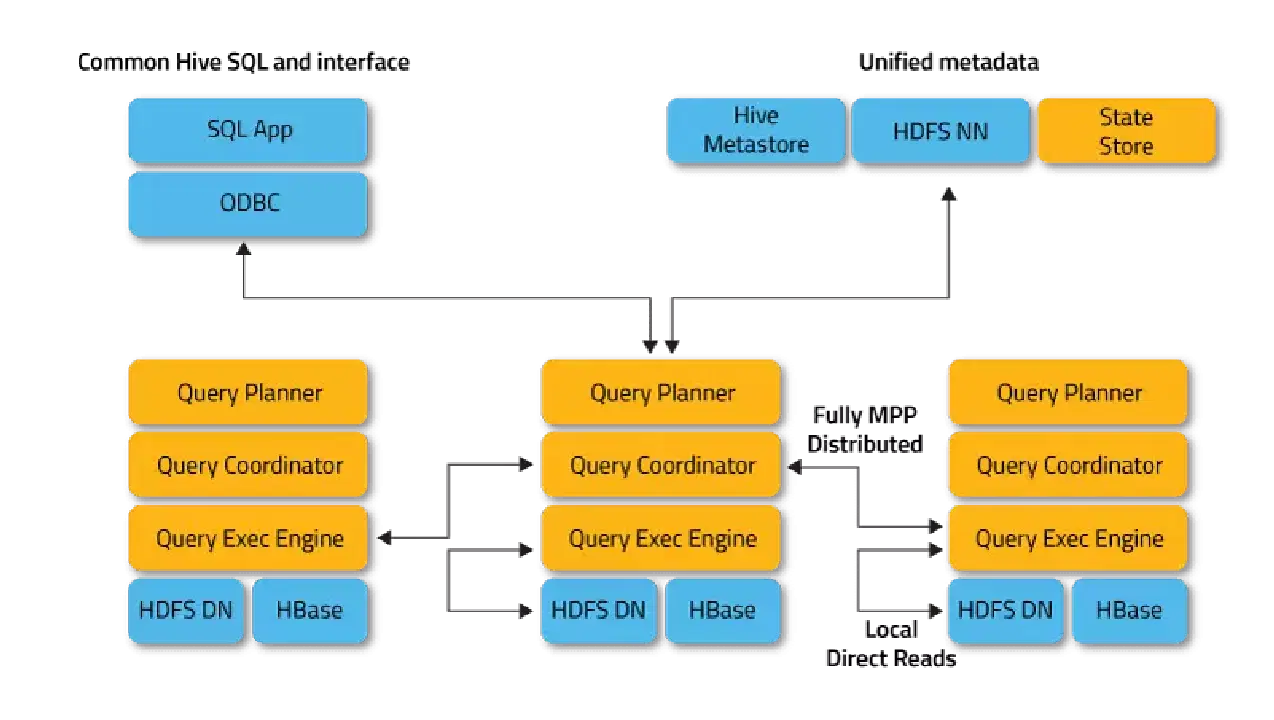
Impala는 대규모 병렬 처리(Massively Parallel Processing, MPP) 엔진, 분산 DBMS, 또는 SQL-on-Hadoop 스택 데이터베이스라고도 불립니다.

Impala는 분산 모드에서 작동하며, 클러스터의 각 노드에서 실행되는 프로세스 인스턴스들이 클라이언트 요청을 수신, 예약 및 조정합니다. 이를 통해 SQL 쿼리 조각을 병렬로 실행할 수 있습니다.
클라이언트는 Apache Hadoop(HBase 및 HDFS) 또는 Amazon S3에 저장된 데이터에 대해 SQL 쿼리를 보내는 사용자 및 애플리케이션을 의미합니다. Impala와 상호 작용은 HUE(Hadoop User Experience) 웹 인터페이스, ODBC, JDBC, 그리고 Impala Shell 명령줄 셸을 통해 이루어집니다.
Impala는 메타데이터 저장소를 사용하여 Apache Hive에 의존합니다. 특히, Hive Metastore는 데이터베이스의 가용성과 구조를 Impala에 알려주는 역할을 합니다.
스키마 객체를 생성, 수정, 삭제하거나 SQL 구문을 통해 테이블에 데이터를 로드할 때 해당 메타데이터 변경 사항은 전문 디렉토리 서비스를 통해 모든 Impala 노드로 자동으로 전파됩니다.
Impala의 핵심 구성 요소는 다음과 같은 실행 파일들입니다.
- Impalad (Impala 데몬): HDFS, HBase, 및 Amazon S3 데이터에 대한 쿼리를 예약하고 실행하는 시스템 서비스입니다. 각 클러스터 노드에서 하나의 impalad 프로세스가 실행됩니다.
- Statestore: 클러스터 내 모든 impalad 인스턴스의 위치와 상태를 추적하는 명명 서비스입니다. 이 시스템 서비스의 하나의 인스턴스는 각 노드와 주 서버(네임 노드)에서 실행됩니다.
- Catalog: Impala DDL 및 DML 구문의 변경 사항을 영향을 받는 모든 Impala 노드로 전파하여, 클러스터 내 모든 노드에서 새로운 테이블이나 로드된 데이터를 즉시 확인할 수 있도록 하는 메타데이터 조정 서비스입니다. Catalog의 인스턴스는 Statestore 데몬과 동일한 클러스터 호스트에서 실행하는 것이 좋습니다.
Apache Impala의 작동 방식
Apache Hive와 마찬가지로 Impala는 SQL 대신 SQL92의 하위 집합인 유사한 선언적 쿼리 언어인 HiveQL(Hive Query Language)을 사용합니다.
Impala에서 요청의 실제 실행 과정은 다음과 같습니다.
클라이언트 애플리케이션은 표준화된 ODBC 또는 JDBC 드라이버 인터페이스를 통해 임팔라드에 연결하여 SQL 쿼리를 보냅니다. 연결된 임팔라드는 현재 요청의 코디네이터 역할을 합니다.
SQL 쿼리를 분석하여 클러스터 내 임팔라드 인스턴스에 대한 작업을 결정합니다. 그런 다음 최적의 쿼리 실행 계획이 수립됩니다.
Impalad는 로컬 시스템 서비스 인스턴스를 사용하여 HDFS 및 HBase에 직접 접근하여 데이터를 가져옵니다. Apache Hive와 달리 이러한 직접적인 상호 작용은 중간 결과가 저장되지 않기 때문에 쿼리 실행 시간을 크게 단축시킵니다.
각 데몬은 코디네이터 임팔라드로 데이터를 반환하고, 코디네이터는 다시 클라이언트로 결과를 보냅니다.
임팔라의 주요 특징
- 실시간 인메모리 처리 지원
- SQL 친화적인 인터페이스
- HDFS, Apache HBase, Amazon S3와 같은 다양한 스토리지 시스템 지원
- Pentaho, Tableau와 같은 BI 도구와의 통합 지원
- HiveQL 구문 사용
Apache Impala의 장점
Impala는 모든 시스템 데몬 프로세스가 시작 시 직접 시작되기 때문에 초기 실행 시 발생하는 오버헤드를 줄여줍니다. 이는 쿼리 실행 시간을 크게 단축시키는 요인입니다. Impala가 빠른 속도를 제공하는 또 다른 이유는 Hive와 달리 중간 결과를 저장하지 않고 HDFS 또는 HBase에 직접 액세스하기 때문입니다.
Impala는 Hive처럼 컴파일을 거치는 대신 런타임에 프로그램 코드를 생성합니다. 하지만 빠른 성능을 제공하는 대신, 신뢰성이 다소 감소하는 측면도 있습니다.
예를 들어, SQL 쿼리 실행 중 데이터 노드가 다운되면 Impala 인스턴스는 재시작해야 하는 반면, Hive는 데이터 소스에 대한 연결을 유지하여 내결함성을 제공합니다.
Impala의 추가적인 장점으로는 Kerberos 보안 네트워크 인증 프로토콜, 우선순위 지정, 요청 대기열 관리 기능, LZO, Avro, RCFile, Parquet, Sequence와 같은 널리 사용되는 빅데이터 형식에 대한 내장 지원이 있습니다.
하이브와 임팔라: 공통점
Hive와 Impala는 Apache Software Foundation 라이선스에 따라 무료로 배포되는 SQL 도구이며, Hadoop 클러스터에 저장된 데이터를 처리하기 위해 사용됩니다. 또한, 두 도구 모두 HDFS 분산 파일 시스템을 사용합니다.
Impala와 Hive는 Apache Hadoop 클러스터에 저장된 빅데이터를 SQL로 처리한다는 공통적인 목표를 가지고 있지만, 서로 다른 방식으로 작업을 수행합니다. Impala는 SQL과 유사한 인터페이스를 제공하여 Hive 테이블을 읽고 쓸 수 있도록 하여 데이터 교환을 용이하게 합니다.
동시에, Impala는 Hadoop에서 SQL 작업을 매우 빠르고 효율적으로 처리하여 빅데이터 분석 연구 프로젝트에 적합합니다. 가능하면 Impala는 장기 실행 SQL 배치 쿼리 처리에 사용되는 기존 Apache Hive 인프라와 함께 작동합니다.
또한, Impala는 테이블 정의를 기존의 MySQL 또는 PostgreSQL 데이터베이스와 유사한 메타스토어, 즉 Hive가 데이터를 저장하는 동일한 위치에 저장합니다. 모든 열이 Impala에서 지원하는 데이터 유형, 파일 형식 및 압축 코덱을 사용하는 한, Impala는 Hive 테이블에 접근할 수 있습니다.
하이브와 임팔라: 차이점

프로그래밍 언어
Hive는 Java로 작성되었으며, Impala는 C++로 작성되었습니다. 그러나 Impala는 일부 Java 기반 Hive UDF를 사용하기도 합니다.
사용 사례
데이터 엔지니어는 ETL(추출, 변환, 로드) 프로세스에서 Hive를 주로 사용합니다. 예를 들어, 여행 정보 수집기나 공항 정보 시스템처럼 대규모 데이터 세트에 대한 장기 실행 배치 작업을 수행하는 데 사용됩니다. 반면, Impala는 주로 분석가와 데이터 과학자를 대상으로 하며, 비즈니스 인텔리전스(BI)와 같은 작업에 주로 사용됩니다.
성능
Impala는 SQL 쿼리를 실시간으로 실행하는 반면, Hive는 데이터 처리 속도가 느린 편입니다. 간단한 SQL 쿼리의 경우, Impala는 Hive보다 6배에서 69배까지 빠르게 실행될 수 있습니다. 그러나 복잡한 쿼리는 Hive가 더 잘 처리합니다.
대기 시간/처리량
Hive의 처리량은 Impala보다 훨씬 높습니다. 메모리에서 쿼리 캐싱을 활성화하는 LLAP(Live Long and Process) 기능은 Hive에 뛰어난 저수준 성능을 제공합니다. LLAP에는 장기 실행 시스템 서비스(데몬)가 포함되어 있어 HDFS 데이터 노드와 직접 상호 작용하고 DAG(Directed Acyclic Graph) 쿼리 구조(빅데이터 컴퓨팅에 활발히 사용되는 그래프 모델)를 긴밀하게 통합할 수 있습니다.
결함 허용
Hive는 모든 중간 결과를 보존하는 내결함성 시스템입니다. 이는 확장성에는 긍정적인 영향을 주지만 데이터 처리 속도 저하를 야기합니다. 반면, Impala는 메모리 바인딩이 더 많기 때문에 내결함성 플랫폼이라고 할 수 없습니다.
코드 변환
Hive는 컴파일 시점에 쿼리 식을 생성하지만, Impala는 런타임에 쿼리 식을 생성합니다. Hive는 애플리케이션을 처음 시작할 때 "콜드 스타트" 문제로 인해 쿼리 변환 속도가 느립니다. 왜냐하면 데이터 원본에 대한 연결을 설정해야 하기 때문입니다. 반면 Impala는 이러한 종류의 시작 오버헤드가 없습니다. SQL 쿼리를 처리하는 데 필요한 시스템 서비스(데몬)는 부팅 시 시작되어 작업 속도를 높입니다.
스토리지 지원
Impala는 LZO, Avro, Parquet 형식을 지원하고, Hive는 일반 텍스트 및 ORC 형식을 지원합니다. 그러나 둘 다 RCFile 및 Sequence 형식을 지원합니다.
| Apache Hive | Apache Impala | |
| 프로그래밍 언어 | Java | C++ |
| 사용 사례 | 데이터 엔지니어링 | 분석 및 분석 |
| 성능 | 간단한 쿼리의 경우 낮음 | 높음 |
| 대기 시간 | 비교적 높은 대기 시간 | 캐싱으로 인해 더 낮은 대기 시간 |
| 결함 허용 | MapReduce로 인해 더 관대함 | MPP로 인해 더 관대함 |
| 코드 변환 | 콜드 스타트로 인해 느림 | 더 빠른 변환 |
| 스토리지 지원 | 일반 텍스트 및 ORC | LZO, Avro, Parquet |
결론
Hive와 Impala는 서로 경쟁하는 도구가 아니라 상호 보완적인 관계에 있습니다. 둘 사이에는 상당한 차이점이 있지만 공통점도 많습니다. 따라서 어느 도구를 선택할지는 프로젝트의 데이터 특성과 요구 사항에 따라 달라집니다.
더불어 Hadoop과 Spark 간의 비교에 대해서도 함께 살펴보시면 도움이 될 것입니다.