주요 논점
- 소셜 미디어 플랫폼들은 사용자 개인 정보 보호에 대한 우려에도 불구하고, 생성형 AI 모델 학습을 위해 AI 기업에 사용자 데이터를 판매하고 있습니다.
- Meta, Reddit, Tumblr, WordPress.com과 같은 플랫폼들이 AI 학습용 데이터 라이선스 계약에 적극적으로 참여하고 있습니다.
- 사용자는 개인 정보 설정을 조정하거나, 데이터 공유를 거부하거나, 온라인 게시물에 신중을 기하는 등 몇 가지 간단한 조치를 통해 자신의 데이터를 보호할 수 있습니다.
소셜 미디어 기업들이 수익을 창출하는 새로운 방식 중 하나는 AI 회사와 데이터 거래를 하는 것입니다. 그렇다면 일반 사용자들은 자신의 데이터와 콘텐츠를 어떻게 보호할 수 있을까요?
생성형 AI 모델을 훈련하는 데 소셜 미디어 데이터가 사용되는 것에 대한 논란은 여전하지만, 이러한 상황은 소셜 미디어 기업들이 사용자 데이터를 공유하는 것을 막지 못하고 있습니다.
Meta는 이미 2023년 Meta Connect에서 발표된 생성형 AI 기능들을 훈련하는 데 소셜 미디어 데이터를 활용하고 있습니다. 여기에는 Meta AI와 WhatsApp에서 AI가 생성한 스티커 만들기 기능 등이 포함됩니다.
Meta의 제품 관리 이사인 Mike Clark는 메타 뉴스룸 게시물에서 다음과 같이 밝혔습니다.
“Instagram과 Facebook에서 공개적으로 공유된 사진과 텍스트 게시물은 Connect에서 발표된 기능의 기반이 되는 생성형 AI 모델을 학습시키는 데 사용된 데이터의 일부였습니다.”
이러한 추세는 2024년에도 꺾일 기미가 보이지 않습니다. 로이터 통신에 따르면 Reddit은 소셜 미디어 플랫폼 콘텐츠를 AI 모델 학습에 사용하도록 Google과 계약을 맺었습니다.
2024년 2월 22일에 제출된 Reddit의 S-1 서류를 통해 회사가 라이선스 계약을 모색하고 있음이 확인되었습니다. 해당 서류에는 다음과 같이 명시되어 있습니다.
“Reddit 데이터는 현재 AI 기술과 여러 LLM 구축의 기초가 되는 요소입니다. Reddit이 보유한 방대한 양의 대화 데이터와 지식이 LLM 학습 및 개선에 지속적으로 기여할 것이라고 믿습니다.”
Reddit은 LLM 학습을 위해 “제3자가 플랫폼에서 과거 및 실시간 데이터를 검색, 분석 및 표시할 수 있는 접근 권한을 허용하는 초기 단계에 있습니다.”라고 명시하고 있습니다.
Meta와 Reddit은 소셜 미디어 분야에서 가장 큰 기업들이지만, AI 학습을 위해 소셜 미디어 데이터를 활용하는 플랫폼은 이들만이 아닙니다. 404미디어 보도에 따르면 Tumblr와 WordPress.com도 Midjourney 및 OpenAI에 사용자 데이터를 판매할 준비를 하고 있습니다.
Facebook, Instagram, Reddit, Tumblr 또는 WordPress.com을 사용하고 있다면, 공개적으로 사용 가능한 콘텐츠가 이미 LLM 학습에 사용되었을 가능성이 있습니다.
예를 들어, 워싱턴 포스트의 검색 도구를 통해 Bard 학습의 일부로 사용된 Google의 C4 데이터 세트에 어떤 사이트가 포함되어 있는지 확인해 보면, Reddit.com이 790만 개의 토큰을 차지하는 것을 알 수 있습니다.

Tumblr.com은 160만 개의 토큰을 보유하고 있습니다. WordPress.com을 사용하는 제 소규모 웹사이트의 경우 14,000개의 토큰을 차지하므로 작은 개인 블로그도 데이터 세트에 포함될 수 있습니다.
AI 기업과 소셜 미디어 기업 간의 지속적인 거래와 라이선스 계약은 단순히 웹에서 데이터를 스크랩하는 것이 아니라 적극적으로 판매되고 있음을 시사합니다.
하지만 향후 데이터 처리와 관련해서는 어떻게 할 수 있을까요? Meta는 생성형 AI 데이터 주체 권리 양식을 도입하여 Meta의 생성형 AI 모델 학습을 위해 제3자가 개인 데이터를 처리하는 것에 대해 이의를 제기하거나 제한할 수 있도록 했습니다.
특히 이 옵션을 사용하더라도 Meta가 자체적으로 데이터를 처리하여 생성형 AI 학습에 사용하는 것을 막을 수는 없습니다. 또한, 양식을 통해 개인 데이터 사용에 대한 이의 신청을 하면 지원 티켓에서 개인 정보가 이미 Meta의 생성형 AI 결과에 사용되고 있다는 증거를 요구했습니다.
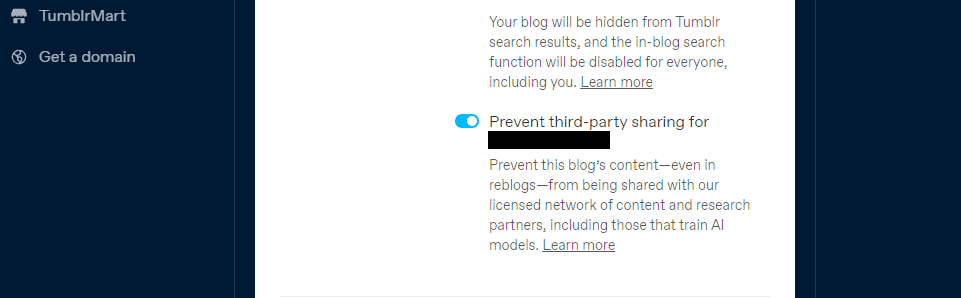
Tumblr는 블로그 설정을 통해 공개 블로그 콘텐츠를 제3자와 공유하지 않도록 선택할 수 있는 옵션을 도입했습니다. 블로그를 클릭한 후 공개 설정까지 스크롤하여 설정에서 찾을 수 있습니다. 거기에서 블로그에 대한 제3자 공유 방지를 선택할 수 있습니다.
Instagram과 같은 플랫폼에서는 계정을 비공개로 전환하여 데이터 사용을 방지할 수 있습니다. 이는 데이터 사용을 완전히 막는 것은 아니지만, LLM의 데이터 스크래핑은 공개 데이터에 초점을 맞추는 것으로 보이므로 잠재적인 보호 장치가 될 수 있습니다.
X(Twitter) 계정도 비공개로 설정할 수 있지만, 이는 잠재적인 보호 조치일 뿐이며 데이터가 비공개로 유지된다는 보장은 없습니다.
공동 성명에서 여러 국가의 정보 위원회와 전 세계 전문가들은 AI 기업의 데이터 스크랩으로 인한 개인 정보 보호 위험을 최소화하기 위해 개인이 취할 수 있는 몇 가지 조치를 제시했습니다. 조언은 다음과 같습니다.
- 웹사이트의 이용 약관 및 개인 정보 보호 정책을 확인하여 개인 정보가 어떻게 공유되는지 알아보십시오.
- 온라인에 게시하는 정보, 특히 민감한 정보를 제한하십시오.
- 개인 정보 보호 설정을 관리하십시오.
- 온라인에서 공유하는 정보에 대해 장기적인 관점에서 생각하십시오.
- 데이터가 부적절하게 처리되었다고 생각되면 소셜 미디어 회사 또는 웹사이트에 문의하십시오. 답변이 만족스럽지 않을 경우 관련 데이터 보호 당국에 불만을 제기하십시오.
특정 정보에 대한 제3자의 접근이 불편하다면 온라인에서 해당 정보를 삭제할 수도 있습니다. 다만 프로필에서 공개적으로 사용 가능한 정보는 이미 스크랩되었을 가능성이 있습니다.
안타깝게도 일반 사용자가 AI 회사로부터 데이터를 보호하기 위해 할 수 있는 일은 제한적입니다. 데이터에 대한 실질적인 통제는 규제 기관의 도움을 통해서만 가능할 것입니다.