프로메테우스는 오픈 소스 기반의 메트릭 모니터링 시스템으로, 서비스와 호스트로부터 데이터를 수집하기 위해 메트릭 엔드포인트로 HTTP 요청을 전송합니다. 수집된 결과는 시계열 데이터베이스에 저장되며, 분석 및 경고 목적으로 활용될 수 있습니다.
왜 모니터링이 필요할까요?
- 문제가 발생하기 전에 미리 알림을 활성화하여 문제가 발생했음을 인지하고 즉시 대응할 수 있도록 돕습니다.
- 문제의 원인을 파악하고, 디버깅 및 해결 과정을 지원하는 통찰력을 제공합니다.
- 시간 경과에 따른 추세나 변화를 파악할 수 있게 해줍니다. 예를 들어, 특정 시점에 활성 세션 수를 모니터링하여 시스템 설계 및 용량 계획에 활용할 수 있습니다.
모니터링은 일반적으로 특정 이벤트와 관련이 있습니다. 이러한 이벤트에는 HTTP 요청 수신, 응답 전송, 디스크 읽기, 사용자 로그인 등이 포함될 수 있습니다. 시스템 모니터링은 프로파일링, 로깅, 추적, 메트릭, 경고 및 시각화를 포괄할 수 있습니다.
블랙박스 모니터링 vs 화이트박스 모니터링
모니터링은 크게 두 가지 범주로 나눌 수 있습니다.
블랙박스 모니터링
블랙박스 모니터링은 시스템 외부에서 관찰하는 방식으로, 애플리케이션 또는 호스트 수준에서 수행됩니다. 이러한 접근 방식은 정보가 제한적일 수 있습니다.
화이트박스 모니터링
화이트박스 모니터링은 서비스 내부를 모니터링하는 것을 의미하며, 내부 구성 요소의 상태 및 성능에 대한 세부 데이터를 제공합니다.
주요 4가지 메트릭 신호
구글 SRE(Site Reliability Engineering)에 따르면, 사용자 대상 시스템을 모니터링할 때 가장 중요한 4가지 메트릭 신호에 집중해야 합니다.
#1. 지연 시간
요청을 처리하는 데 걸리는 시간이며, 성공한 요청과 실패한 요청 모두를 추적하는 것이 중요합니다.
#2. 트래픽
시스템에 유입되는 요청의 양을 측정합니다. 웹 서비스의 경우 일반적으로 초당 HTTP 요청 수를 나타냅니다.
#3. 오류
실패한 요청의 비율을 나타냅니다.
#4. 포화도
서비스가 얼마나 많이 사용되고 있는지 나타냅니다. 대기 시간 증가는 종종 포화도의 중요한 지표이며, 많은 시스템이 100% 사용률에 도달하기 전에 성능이 저하될 수 있습니다.
프로메테우스 메트릭 유형
프로메테우스 메트릭은 다음 네 가지 주요 유형으로 분류됩니다.
#1. 카운터
카운터는 항상 증가하는 값을 나타내며, 0으로 재설정될 수는 있지만 감소할 수는 없습니다. 스크랩 실패 시 데이터가 누락될 수 있지만, 다음 읽기에서 누적된 증가량을 확인할 수 있습니다. 예시:
- 총 수신 HTTP 요청 수
- 발생한 예외 수
#2. 게이지
게이지는 특정 시점의 스냅샷을 나타내며, 증가하거나 감소할 수 있습니다. 데이터 가져오기 실패 시 샘플이 손실될 수 있고, 다음 가져오기에서 다른 값을 나타낼 수 있습니다. 예시: 디스크 공간, 메모리 사용량.
#3. 히스토그램
히스토그램은 관찰된 값을 샘플링하고 구성 가능한 버킷에 따라 집계합니다. 요청 처리 시간이나 응답 크기와 같은 항목을 모니터링하는 데 사용됩니다. 프로메테우스는 모든 요청의 처리 시간을 저장하는 대신 특정 버킷에 속하는 요청 빈도를 저장합니다. 예시: 특정 HTTP 요청에 대한 요청 처리 시간 측정.
#4. 요약
요약은 히스토그램과 유사하게 관찰된 값의 샘플을 제공하며, 일반적으로 요청 처리 시간이나 응답 크기를 나타냅니다. 관찰된 총 개수와 값의 합계를 제공하여 관찰된 값의 평균을 계산할 수 있습니다. 예를 들어, 1분 동안 2초, 3초, 4초가 걸리는 세 개의 요청이 있었다면, 총합은 9초이고 개수는 3이므로 평균 처리 시간은 3초입니다.
프로메테우스 생태계 구성 요소
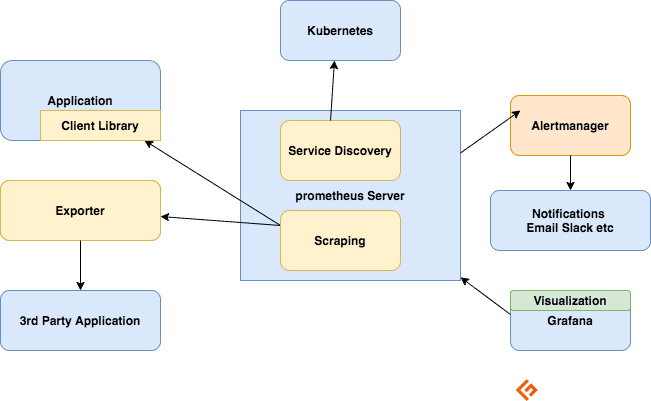
프로메테우스 서버
메트릭을 수집 및 저장하고, 쿼리에 사용할 수 있도록 하며, 수집된 메트릭 기반으로 경고를 전송합니다.
스크래핑
프로메테우스는 풀 기반 시스템으로, 메트릭을 가져오기 위해 스크랩이라는 HTTP 요청을 보냅니다. 구성에 따라 대상에 스크랩 요청을 전송합니다.
각 대상(정적으로 정의되거나 동적으로 검색됨)은 지정된 간격(스크래핑 간격)으로 스크랩됩니다. 각 스크랩은 `/metrics` HTTP 엔드포인트를 통해 클라이언트 메트릭의 현재 상태를 가져와 프로메테우스 시계열 데이터베이스에 값을 저장합니다.
다양한 시계열 데이터베이스를 사용하여 모니터링 솔루션을 확장할 수 있습니다.
클라이언트 라이브러리
서비스를 모니터링하려면 코드에 계측을 추가해야 합니다. 프로메테우스는 널리 사용되는 모든 언어 및 런타임에서 사용할 수 있는 클라이언트 라이브러리를 제공합니다. 이러한 라이브러리를 사용하면 코드에서 메트릭을 내보낼 수 있습니다. 이를 직접 계측이라고 합니다. 라이브러리를 통해 내부 메트릭을 정의하고 HTTP 엔드포인트를 통해 노출할 수 있으며, 프로메테우스는 해당 엔드포인트를 스크랩하여 서버로 전송합니다.
프로메테우스는 Go, Java, Python 및 Ruby용 공식 클라이언트 라이브러리를 제공하며, C, PHP, Node.js, C#/.NET 등에서 사용할 수 있는 커뮤니티 구축 라이브러리도 제공합니다.
익스포터(Exporter)
많은 애플리케이션이 프로메테우스 형식이 아닌 다른 형식으로 메트릭을 노출합니다. 이러한 애플리케이션이나 코드에 접근할 수 없는 경우 직접 계측을 추가할 수 없습니다. 예를 들어 MySQL, Kafka, JMX, HAProxy 및 NGINX 서버가 있습니다. 이러한 경우에는 익스포터를 사용합니다.
익스포터는 메트릭을 노출하는 애플리케이션과 함께 배포하는 도구입니다. 익스포터는 애플리케이션과 프로메테우스 간의 프록시 역할을 하며, 애플리케이션의 액세스 로그나 오류 로그에서 데이터를 수집하여 프로메테우스 형식으로 변환한 후 프로메테우스 서버로 전달합니다.
인기 있는 익스포터는 다음과 같습니다.
- 윈도우 익스포터 – Windows 서버 메트릭용
- 노드 익스포터 – Linux 서버 메트릭용
- 블랙박스 익스포터 – DNS 및 웹사이트 성능 메트릭용
- JMX 익스포터 – Java 기반 애플리케이션 메트릭용
애플리케이션이나 익스포터가 설정되면 프로메테우스에 해당 위치를 알려줘야 합니다. 정적 구성을 통해 설정할 수 있지만, 동적 환경에서는 서비스 검색을 사용해야 합니다.
알림
프로메테우스를 사용한 경고는 두 부분으로 구성됩니다.
경고 규칙은 Alertmanager에 경고를 보내고, Alertmanager는 이메일, Slack, Hipchat, PagerDuty 등 다양한 통합을 통해 알림을 관리하고 전송합니다. Alertmanager는 알림 수를 줄이기 위해 침묵 또는 집계를 수행할 수도 있습니다.
프로메테우스 및 대시보드를 사용하여 Linux 서버를 모니터링하는 방법을 안내합니다.
대시보드를 통한 시각화
프로메테우스는 PromQL 쿼리를 통해 시각화에 필요한 원시 데이터를 생성하는 다양한 API를 제공합니다.
프로메테우스 자체에는 임시 쿼리에 사용할 수 있는 표현식 브라우저가 포함되어 있지만, 가장 강력한 시각화 도구는 그라파나입니다. 그라파나는 프로메테우스와 완벽하게 통합되어 다양한 대시보드를 생성할 수 있습니다.
그라파나에서 프로메테우스를 데이터 소스로 구성해야 합니다.
대시보드는 다음과 같은 방법으로 추가할 수 있습니다.
- 커뮤니티에서 구축한 대시보드 가져오기
- 직접 대시보드 구축
- 미리 정의된 대시보드 사용
미리 정의된 노드 익스포터 대시보드의 예시는 다음과 같습니다.
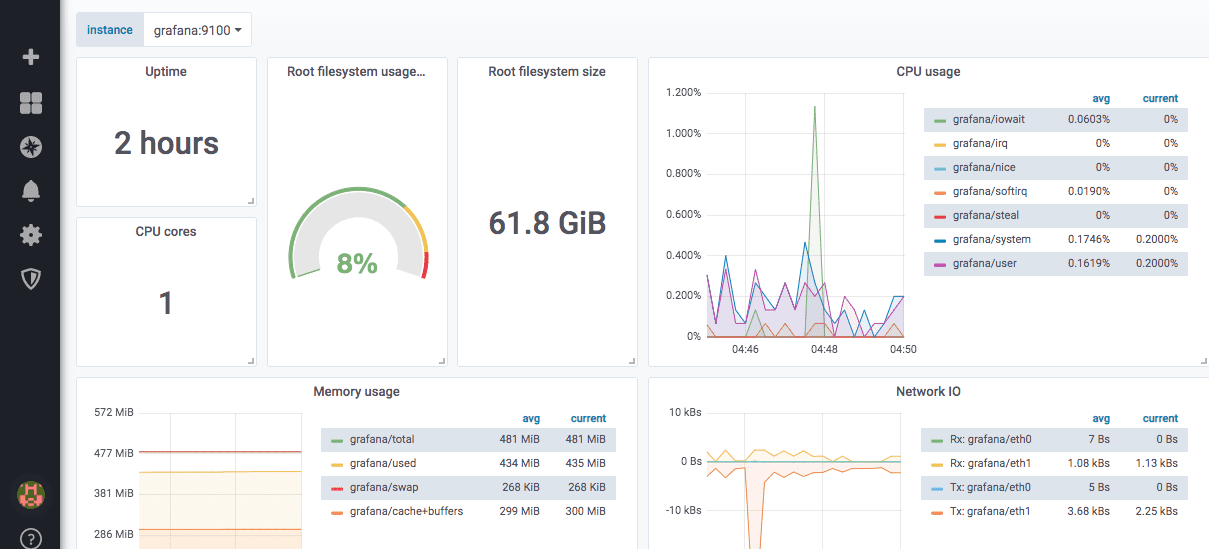
그라파나는 worldPing 모듈을 통해 전 세계 사이트 및 DNS 성능 지표를 모니터링할 수도 있습니다.
요약
프로메테우스는 실행을 위한 요구 사항이 거의 없으며, 단일 바이너리와 구성 파일만으로 간단하게 실행할 수 있습니다. 수천 개의 대상을 처리하고 초당 수백만 개의 샘플을 수집할 수 있으며, 전체 시스템 상태와 동작을 추적하도록 설계되었습니다.
그라파나는 메트릭 시각화에 가장 적합한 도구 중 하나이며, 프로메테우스와 완벽하게 통합되어 있습니다.