2020년 9월 1일, 엔비디아는 암페어(Ampere) 아키텍처를 기반으로 한 최신 RTX 3000 시리즈 게이밍 GPU 라인업을 발표했습니다. 이번 글에서는 새롭게 추가된 기능, AI 기반 소프트웨어, 그리고 이 시리즈를 특별하게 만드는 모든 요소들을 자세히 살펴보겠습니다.
RTX 3000 시리즈 GPU의 등장

엔비디아의 발표는 맞춤형 8nm 공정으로 제작된 새로운 GPU의 등장을 알렸습니다. 이 GPU는 래스터화 및 레이 트레이싱 성능 모두에서 이전 세대 대비 상당한 성능 향상을 보여줍니다.
라인업의 가장 하위 모델인 RTX 3070은 499달러에 출시되었습니다. 엔비디아의 초기 발표에서 공개된 가장 저렴한 카드임에도 불구하고, 기존 RTX 2080 Ti를 능가하는 성능을 제공합니다. RTX 2080 Ti는 최고급 라인 카드로, 정가 1400달러 이상에 판매되곤 했습니다. 엔비디아 발표 이후 타사 판매 가격이 하락하면서 많은 제품들이 이베이에서 600달러 미만으로 급하게 판매되었습니다.
발표 시점에는 확고한 벤치마크가 없었기 때문에, 이 카드가 2080 Ti보다 객관적으로 “더 나은” 것인지, 아니면 엔비디아가 마케팅을 과장한 것인지는 불분명했습니다. 벤치마크 결과, 4K 해상도에서 RTX를 켠 상태에서는 암페어 기반 3000 시리즈가 튜링(Turing) 기반 제품보다 레이 트레이싱 성능에서 두 배 이상 앞서는 것으로 나타났습니다. 이는 순수 래스터화된 게임에 비해 격차가 더 커 보이는 이유입니다. 레이 트레이싱이 이제는 성능에 큰 영향을 미치지 않고 최신 콘솔 세대에서 지원되기 때문에, 이전 세대 주력 제품과 비슷한 속도로 실행되면서 가격은 3분의 1 수준으로 낮아진 점은 주목할 만합니다.
가격이 이대로 유지될지는 미지수입니다. 타사 디자인은 일반적으로 가격이 최소 50달러 더 비싸고 수요가 매우 높기 때문에, 2020년 10월에는 600달러에 판매되는 것을 보는 것도 놀라운 일이 아닙니다.
그 다음 모델인 RTX 3080은 699달러에 출시되었으며, RTX 2080보다 두 배 빠르고 3070보다 약 25~30% 더 빠른 성능을 제공합니다.
라인업의 최상위 모델은 RTX 3090입니다. 이 모델은 매우 거대하여 엔비디아 내부적으로 “BFGPU(Big Ferocious GPU)”라고 불립니다.

엔비디아는 직접적인 성능 지표를 제시하지 않았지만, 60FPS로 8K 게임을 실행하는 모습을 보여주었습니다. 엔비디아는 DLSS를 사용했을 가능성이 높지만 8K 게임은 8K 게임입니다.
물론, 3060과 같은 더 예산 지향적인 모델의 다른 변형도 출시될 예정이지만, 일반적으로 나중에 출시됩니다.
엔비디아는 냉각 성능 향상을 위해 새로운 쿨러 디자인을 적용했습니다. 3080은 정격 전력이 320와트로 상당히 높기 때문에 듀얼 팬 설계를 채택했습니다. 하지만 하단에 두 개의 팬을 배치하는 대신, 일반적으로 백플레이트가 있는 상단 끝에 팬을 배치했습니다. 이 팬은 공기를 CPU 쿨러와 케이스 상단으로 향하게 합니다.

케이스 내부의 공기 흐름이 성능에 얼마나 큰 영향을 미칠 수 있는지를 고려하면 이는 매우 합리적인 선택입니다. 그러나 이러한 디자인으로 인해 회로 기판이 매우 비좁아져 타사 판매 가격에 영향을 줄 수 있습니다.
DLSS: 소프트웨어의 이점
레이 트레이싱이 이 새로운 카드의 유일한 이점은 아닙니다. 사실, RTX 2000 시리즈와 3000 시리즈는 이전 세대 카드에 비해 실제 레이 트레이싱을 수행하는 데 큰 차이는 없습니다. 블렌더와 같은 3D 소프트웨어에서 전체 장면을 레이 트레이싱하는 데에는 일반적으로 프레임당 몇 초 또는 몇 분이 걸리므로 10밀리초 미만으로 처리하는 것은 불가능합니다.
물론 RT 코어라는 레이 계산 전용 하드웨어가 있지만, 엔비디아는 다른 접근 방식을 선택했습니다. 엔비디아는 노이즈 제거 알고리즘을 개선하여 GPU가 매우 저렴한 단일 패스를 렌더링한 다음 AI 기술을 통해 게이머가 원하는 이미지로 변환합니다. 기존의 래스터화 기반 기술과 결합하면 레이 트레이싱 효과로 향상된 쾌적한 경험을 제공합니다.

이를 빠르게 수행하기 위해 엔비디아는 텐서 코어라는 AI 전용 처리 코어를 추가했습니다. 이 코어는 기계 학습 모델을 실행하는 데 필요한 모든 수학 연산을 매우 빠르게 처리합니다. 텐서 코어는 클라우드 서버 공간의 AI 게임 체인저이며, AI는 많은 회사에서 광범위하게 사용되고 있습니다.
잡음 제거 외에도 게이머를 위한 텐서 코어의 주요 용도는 DLSS(Deep Learning Super Sampling)입니다. DLSS는 낮은 품질의 프레임을 가져와 풀 네이티브 품질로 업스케일합니다. 즉, 1080p 수준의 프레임 속도로 게임을 하면서 4K 해상도의 화질을 즐길 수 있습니다.
이는 레이 트레이싱 성능에도 상당한 도움이 됩니다. PCMag의 벤치마크에 따르면 RTX 2080 Super에서 모든 레이 트레이싱 설정을 최대로 설정하고 Control 게임을 실행했을 때, 4K 해상도에서는 19FPS에 불과했지만 DLSS를 켜면 54FPS까지 향상되었습니다. DLSS는 튜링 및 암페어의 텐서 코어를 통해 가능해진 엔비디아의 무료 성능 향상 기술입니다. DLSS를 지원하는 게임에서는 소프트웨어만으로도 상당한 속도 향상을 기대할 수 있습니다.
DLSS는 새로운 기술이 아니며 2년 전 RTX 2000 시리즈 출시 때 기능으로 발표되었습니다. 당시에는 엔비디아가 각 개별 게임에 대해 기계 학습 모델을 훈련하고 조정해야 했기 때문에 매우 소수의 게임에서만 지원되었습니다.
하지만 엔비디아는 DLSS 2.0이라는 새로운 버전을 완전히 재작성했습니다. DLSS 2.0은 모든 개발자가 구현할 수 있는 범용 API이며, 대부분의 주요 게임에서 이미 채택하고 있습니다. DLSS 2.0은 한 프레임에서 작업하는 대신 TAA와 유사하게 이전 프레임에서 모션 벡터 데이터를 가져옵니다. 그 결과 DLSS 1.0보다 훨씬 더 선명하고 어떤 경우에는 기본 해상도보다 더 좋고 선명하게 보이므로 DLSS를 켜지 않을 이유가 거의 없습니다.
컷신처럼 장면이 완전히 전환될 때, DLSS 2.0은 모션 벡터 데이터를 기다리는 동안 처음 프레임을 50% 품질로 렌더링해야 합니다. 이로 인해 몇 밀리초 동안 품질이 약간 떨어질 수 있습니다. 하지만 전체 화면의 99%는 제대로 렌더링되므로 대부분의 사람들은 이를 알아차리지 못할 것입니다.
암페어 아키텍처: AI를 위한 설계
암페어는 매우 빠릅니다. 특히 AI 연산에서 뛰어난 속도를 보여줍니다. RT 코어는 튜링보다 1.7배 빠르고, 새로운 텐서 코어는 튜링보다 2.7배 빠릅니다. 이 두 가지 코어의 조합은 레이 트레이싱 성능에서 진정한 세대 도약을 의미합니다.

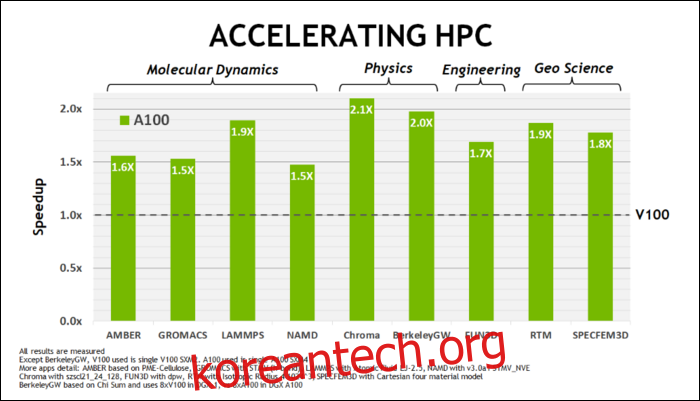
올해 5월 초, 엔비디아는 암페어 A100 GPU를 출시했습니다. 이 GPU는 AI 실행을 위해 설계된 데이터 센터 GPU입니다. 엔비디아는 A100 GPU를 통해 암페어 아키텍처를 훨씬 더 빠르게 만드는 많은 기술들을 상세히 설명했습니다. 데이터 센터 및 고성능 컴퓨팅 워크로드에서 암페어는 일반적으로 튜링보다 약 1.7배 빠르며, AI 학습에서는 최대 6배 빠른 성능을 보여줍니다.
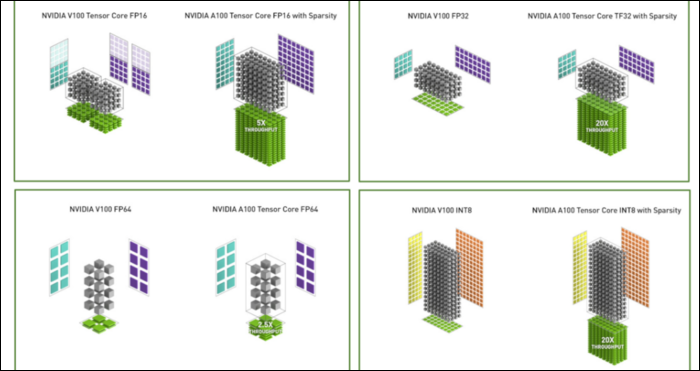
암페어는 일부 워크로드에서 업계 표준인 “부동 소수점 32(FP32)”를 대체하도록 설계된 새로운 숫자 형식을 사용합니다. 컴퓨터가 처리하는 모든 숫자는 8비트, 16비트, 32비트, 64비트 등 메모리에서 미리 정의된 비트 수를 차지합니다. 숫자가 클수록 처리하기가 더 어려우므로 작은 크기를 사용할 수 있다면 처리 속도가 향상됩니다.
FP32는 32비트 십진수를 저장하며, 숫자 범위(크기)에 8비트를 사용하고 정밀도에 23비트를 사용합니다. 엔비디아에 따르면, 이러한 23개의 정밀도 비트는 많은 AI 워크로드에 반드시 필요한 것은 아니며, 그 중 10개만 사용해도 비슷한 결과와 훨씬 더 나은 성능을 얻을 수 있습니다. 크기를 32비트 대신 19비트로 줄이면 많은 연산에서 큰 차이가 발생합니다.
이 새로운 형식은 텐서 플로트 32(Tensor Float 32)라고 하며, A100의 텐서 코어는 이 형식을 처리하도록 최적화되었습니다. 이는 다이 크기를 줄이고 코어 수를 늘리는 것 외에도 AI 학습에서 6배의 성능 향상을 얻는 데 기여합니다.

새로운 숫자 형식 외에도 암페어는 FP32 및 FP64와 같은 특정 계산에서 상당한 성능 향상을 보여줍니다. 이러한 성능 향상은 일반 사용자에게 더 높은 FPS로 직접적으로 이어지지는 않지만, 텐서 연산에서 전반적으로 거의 3배 더 빠른 속도를 제공하는 데 일조합니다.
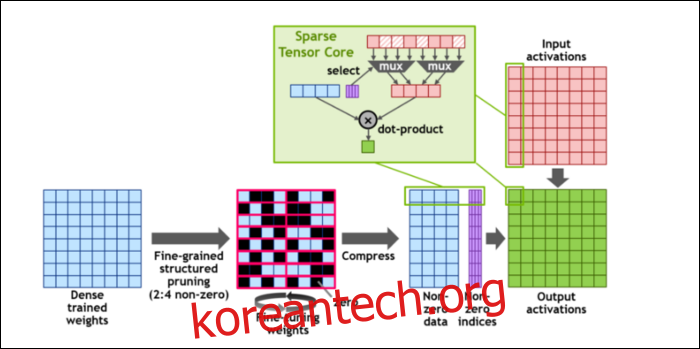
또한 계산 속도를 더욱 높이기 위해 세분화된 구조적 희소성이라는 개념을 도입했습니다. 이는 매우 단순한 개념에 대한 멋진 이름입니다. 신경망은 최종 결과에 영향을 미치는 가중치라고 하는 많은 숫자 목록과 함께 작동합니다. 크런치해야 할 숫자가 많을수록 속도가 느려집니다.
하지만 이러한 숫자가 모두 실제로 유용한 것은 아닙니다. 일부 숫자는 0이므로 기본적으로 제거할 수 있습니다. 동시에 더 많은 숫자를 처리할 수 있을 때 이는 엄청난 속도 향상으로 이어집니다. 희소성은 기본적으로 숫자를 압축하여 계산에 필요한 노력을 줄여줍니다. 새로운 “스파스 텐서 코어(Sparse Tensor Core)”는 압축된 데이터에서 작동하도록 구축되었습니다.
이러한 변경 사항에도 불구하고 엔비디아는 훈련된 모델의 정확도에 눈에 띄는 영향이 없을 것이라고 밝혔습니다.
가장 작은 숫자 형식 중 하나인 스파스 INT8 계산의 경우, 단일 A100 GPU의 최대 성능은 1.25페타플롭(PetaFLOP) 이상으로 매우 높은 수치입니다. 물론 특정 종류의 숫자를 처리할 때만 해당되지만, 매우 인상적입니다.