30개 이상의 Hadoop 인터뷰 질문 및 답변
빅 데이터 분석 및 Hadoop 전문가 채용 기회
포브스 통계에 따르면 전 세계 기업의 상당 부분인 90%에 달하는 조직이 투자 보고서 작성 시 빅 데이터 분석을 활용하고 있습니다. 빅 데이터의 중요성이 커짐에 따라, Hadoop 전문가에 대한 채용 시장의 문이 그 어느 때보다 넓어지고 있습니다.
이러한 상황에서 Hadoop 전문가로서 성공적인 경력을 쌓을 수 있도록, 실제 인터뷰에서 나올 수 있는 질문과 답변을 준비했습니다. 이 자료를 통해 인터뷰를 자신 있게 통과하고 원하는 목표를 달성하는 데 도움을 드릴 것입니다.
Hadoop 및 빅 데이터 분야의 매력적인 급여 수준을 확인하면 인터뷰에 대한 동기 부여가 더욱 강해질 것입니다. 🤔
- Indeed.com에 따르면 미국 내 빅 데이터 Hadoop 개발자의 평균 연봉은 약 $144,000에 이릅니다.
- 영국에서는 itjobswatch.co.uk에서 빅 데이터 Hadoop 개발자의 평균 연봉이 £66,750 수준으로 보고되었습니다.
- 인도에서는 Indeed.com 데이터를 기준으로 평균 연봉이 약 16,000,000 루피에 달합니다.
상당히 매력적인 수준이지 않습니까? 이제 Hadoop에 대해 더 깊이 알아볼 차례입니다.
Hadoop이란 무엇인가?
Hadoop은 대용량 데이터 세트를 처리, 저장 및 분석하기 위해 Java로 개발된 널리 사용되는 프레임워크입니다. 이 프레임워크는 프로그래밍 모델을 기반으로 작동합니다.
Hadoop의 핵심적인 설계 특징은 단일 서버 환경에서 로컬 컴퓨팅 및 스토리지를 제공하는 시스템에서 여러 시스템으로 확장할 수 있다는 점입니다. 또한, 애플리케이션 계층의 오류를 감지하고 처리하여 높은 가용성을 보장하는 기능은 Hadoop 시스템을 매우 안정적으로 만듭니다.
이제 Hadoop 인터뷰에서 자주 나오는 질문과 그에 대한 답변을 바로 살펴보도록 하겠습니다.
Hadoop 인터뷰 예상 질문 및 답변
Hadoop의 저장 단위는 무엇인가?
답변: Hadoop의 저장 단위는 HDFS(Hadoop Distributed File System)라고 합니다.
NAS(Network Attached Storage)와 Hadoop 분산 파일 시스템의 차이점은 무엇인가?
답변: HDFS는 Hadoop의 기본 스토리지 시스템으로, 상용 하드웨어를 활용하여 대용량 파일을 저장하는 분산 파일 시스템입니다. 반면, NAS는 다양한 클라이언트 그룹에 데이터 액세스 권한을 제공하는 파일 수준의 컴퓨터 데이터 스토리지 서버입니다.
NAS는 데이터를 전용 하드웨어에 저장하는 반면, HDFS는 Hadoop 클러스터 내의 모든 시스템에 데이터 블록을 분산 저장합니다.
NAS는 고가의 고급 스토리지 장비를 사용하는 반면, HDFS는 경제적인 상용 하드웨어를 활용하여 비용 효율성을 높입니다.
NAS는 연산 데이터와 저장 데이터를 분리하여 저장하기 때문에 MapReduce에 적합하지 않습니다. 반대로, HDFS는 MapReduce 프레임워크와 효과적으로 연동되도록 설계되어 있습니다. MapReduce 프레임워크에서는 연산 작업이 데이터가 있는 곳에서 수행됩니다.
Hadoop의 MapReduce와 Shuffling을 설명하시오.
답변: MapReduce는 Hadoop 클러스터 내에서 대규모 확장성을 구현하기 위해 Hadoop 프로그램이 수행하는 두 가지 주요 단계를 의미합니다. Shuffling은 Mapper 단계의 출력 데이터를 MapReduce의 다음 단계인 Reducer로 전송하는 과정입니다.
Apache Pig 아키텍처 개요
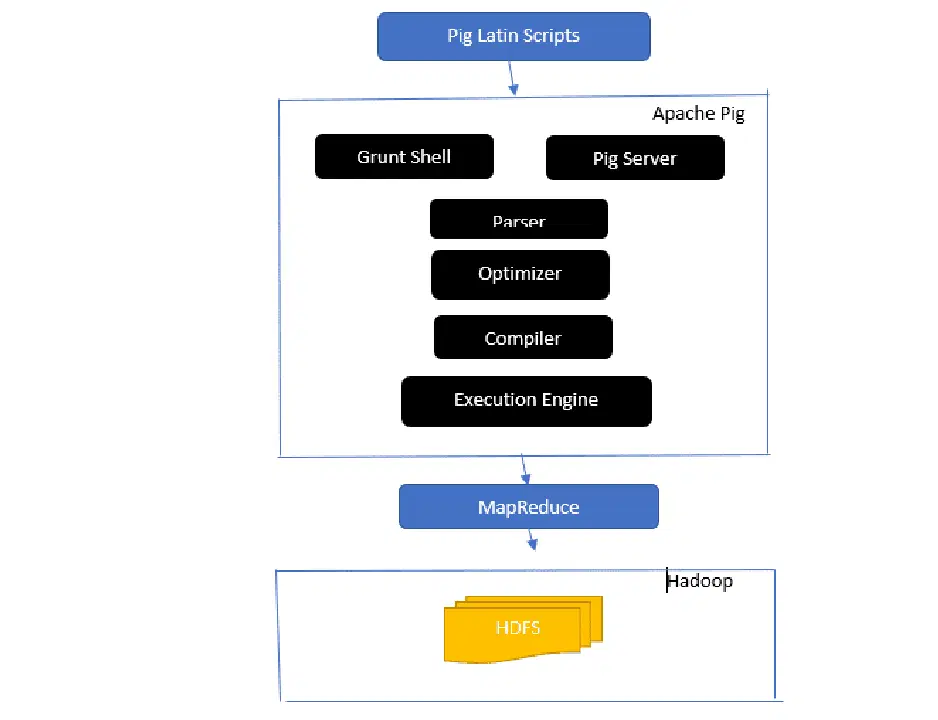
답변: Apache Pig 아키텍처는 Pig Latin 스크립트를 사용하여 대용량 데이터 세트를 처리하고 분석하는 Pig Latin 인터프리터로 구성됩니다.
또한, Apache Pig는 조인, 로드, 필터, 정렬, 그룹화 등 다양한 데이터 연산을 수행할 수 있는 데이터 세트 컬렉션으로 이루어져 있습니다.
Pig 라틴어는 Grant 쉘, UDF, 임베디드와 같은 실행 메커니즘을 사용하여 Pig 스크립트를 작성하고 필요한 작업을 수행합니다.
Pig는 이러한 스크립트를 Map-Reduce 작업 시리즈로 변환하여 프로그래머의 부담을 줄여줍니다.
Apache Pig 아키텍처의 주요 구성 요소는 다음과 같습니다.
- 파서: Pig 스크립트의 구문을 확인하고 유형 검사를 수행하여 스크립트를 처리합니다. 파서의 출력은 Pig Latin의 명령문과 논리 연산자를 나타내며, DAG(방향성 비순환 그래프)라고 합니다.
- 옵티마이저: DAG에서 프로젝션 및 푸시다운과 같은 논리적 최적화를 수행합니다.
- 컴파일러: 옵티마이저가 생성한 최적화된 논리적 계획을 일련의 MapReduce 작업으로 컴파일합니다.
- 실행 엔진: MapReduce 작업의 최종 실행이 이루어지는 곳으로, 원하는 결과를 생성합니다.
- 실행 모드: Apache Pig는 주로 로컬 모드와 맵 리듀스 모드를 지원합니다.
답변: Local Metastore 서비스는 Hive와 동일한 JVM에서 실행되며, 동일한 시스템 또는 원격 시스템에서 실행 중인 데이터베이스에 연결됩니다. 반면, Remote Metastore 서비스는 Hive 서비스 JVM과는 독립적으로 자체 JVM에서 실행됩니다.
빅 데이터의 5가지 V는 무엇인가?
답변: 빅 데이터의 5가지 V는 빅 데이터의 주요 특징을 나타내는 요소입니다. 다음을 포함합니다.
- 가치(Value): 빅 데이터는 데이터를 활용하는 조직에 높은 투자 수익률(ROI)을 제공하고자 합니다. 빅 데이터는 통찰력 발견과 패턴 인식에서 가치를 창출하며, 그 결과 고객 관계 강화와 운영 효율성 향상을 가져옵니다.
- 다양성(Variety): 수집되는 데이터 유형의 이질성을 나타냅니다. 다양한 데이터 형식에는 CSV 파일, 비디오, 오디오 등이 포함됩니다.
- 볼륨(Volume): 조직에서 관리하고 분석하는 데이터의 상당한 양과 크기를 의미합니다. 이 데이터는 기하급수적으로 증가하는 추세에 있습니다.
- 속도(Velocity): 데이터가 생성되고 증가하는 기하급수적인 속도를 나타냅니다.
- 진실성(Veracity): 데이터가 불완전하거나 일관성이 없을 때 데이터가 '불확실'하거나 '부정확'한 정도를 나타냅니다.
Pig Latin의 다양한 데이터 유형을 설명하시오.
답변: Pig Latin의 데이터 유형은 원자 데이터 유형과 복합 데이터 유형으로 나눌 수 있습니다.
원자 데이터 유형은 다른 프로그래밍 언어에서도 사용되는 기본적인 데이터 유형입니다. 다음과 같은 것들이 있습니다.
- Int: 부호 있는 32비트 정수를 정의합니다. 예: 13
- Long: 64비트 정수를 정의합니다. 예: 10L
- Float: 부호 있는 32비트 부동 소수점을 정의합니다. 예: 2.5F
- Double: 부호 있는 64비트 부동 소수점을 정의합니다. 예: 23.4
- Boolean: 불리언 값을 정의합니다. (참/거짓)
- Datetime: 날짜-시간 값을 정의합니다. 예: 1980-01-01T00:00.00.000+00:00
복합 데이터 유형은 다음과 같습니다.
- Map: 키-값 쌍의 집합을 나타냅니다. 예: ['color'#'yellow', 'number'#3]
- Bag: 튜플 집합의 모음으로, '{}' 기호를 사용합니다. 예: {(헨리, 32), (키티, 47)}
- Tuple: 정렬된 필드 집합을 정의합니다. 예: (나이, 33세)
Apache Oozie와 Apache ZooKeeper는 무엇인가?
답변: Apache Oozie는 Hadoop 작업을 하나의 논리적 작업으로 예약하고 관리하는 Hadoop 스케줄러입니다.
반면, Apache ZooKeeper는 분산 환경에서 다양한 서비스의 조정을 돕는 역할을 합니다. 동기화, 그룹화, 구성 유지 관리, 이름 지정 등의 서비스를 제공하여 개발 시간을 절약하고, 대기 및 리더 선출에 대한 지원 기능도 제공합니다.
MapReduce 작업에서 Combiner, RecordReader, Partitioner의 역할은 무엇인가?
답변: Combiner는 미니 리듀서와 유사한 역할을 합니다. Mapper 단계에서 데이터를 받아 처리한 후 결과를 Reducer 단계로 전달합니다.
RecordReader는 InputSplit과 상호 작용하여 데이터를 키-값 쌍으로 변환하여 Mapper가 데이터를 읽을 수 있도록 합니다.
Partitioner는 데이터를 요약하는 데 필요한 Reducer 작업 수를 결정하고, Combiner의 결과물이 Reducer로 전달되는 방식을 결정하는 역할을 합니다. 또한 중간 맵 출력의 키 분할을 제어합니다.
Hadoop의 다양한 벤더별 배포판을 언급하시오.
답변: Hadoop 기능을 확장하는 다양한 벤더는 다음과 같습니다.
- IBM Open Platform
- Cloudera CDH Hadoop 배포판
- MapR Hadoop 배포
- Amazon Elastic MapReduce
- Hortonworks Data Platform (HDP)
- Pivotal Big Data Suite
- Datastax Enterprise Analytics
- Microsoft Azure HDInsight (클라우드 기반 Hadoop 배포)
HDFS가 내결함성을 가지는 이유는 무엇인가?
답변: HDFS는 데이터를 여러 DataNode에 복제하여 내결함성을 구현합니다. 여러 노드에 데이터를 저장함으로써 하나의 노드에 문제가 발생하더라도 다른 노드에서 데이터를 검색할 수 있도록 합니다.
페더레이션과 고가용성을 구분하시오.
답변: HDFS 페더레이션은 다른 노드에 문제가 발생하더라도 한 노드에서 지속적인 데이터 흐름을 보장하여 내결함성을 제공합니다. 반면, 고가용성은 액티브 NameNode와 보조 NameNode를 별도의 시스템에 구성하여 두 시스템을 통해 안정적인 서비스를 제공하는 방식입니다.
페더레이션은 제한 없이 다양한 NameNode를 사용할 수 있지만, 고가용성에서는 액티브 및 대기 상태의 두 NameNode만 사용할 수 있습니다.
페더레이션에서 NameNode는 메타데이터 풀을 공유하며, 각 NameNode는 전용 풀을 가집니다. 고가용성에서는 액티브 NameNode가 작업을 수행하는 동안 대기 NameNode는 유휴 상태로 메타데이터를 주기적으로 업데이트합니다.
블록 및 파일 시스템 상태를 확인하는 방법은 무엇인가?
답변: HDFS 파일 시스템의 상태를 확인하려면 루트 사용자 권한으로 또는 개별 디렉터리에서 `hdfs fsck /` 명령을 사용합니다.
사용 예시: `hdfs fsck / -files --blocks --locations > dfs-fsck.log`
명령 옵션:
- `-files`: 확인 중인 파일 목록을 출력합니다.
- `--locations`: 확인 과정에서 모든 블록의 위치를 출력합니다.
블록 상태 확인 명령: `hdfs fsck <path> -files -blocks`
- `<path>`: 검사를 시작할 경로를 지정합니다.
- `--blocks`: 확인 과정에서 파일 블록을 출력합니다.
`rmadmin -refreshNodes`와 `dfsadmin -refreshNodes` 명령은 언제 사용하는가?
답변: 이 두 명령은 노드를 가동하거나 가동이 완료된 후 노드 정보를 새로 고치는 데 사용됩니다.
`dfsadmin -refreshNodes` 명령은 HDFS 클라이언트를 실행하고 NameNode의 노드 구성을 새로 고치는 역할을 합니다. 반면, `rmadmin -refreshNodes` 명령은 ResourceManager의 관리 작업을 실행합니다.
체크포인트란 무엇인가?
답변: 체크포인트는 파일 시스템의 마지막 변경 사항을 최신 FSImage와 병합하여 편집 로그 파일 크기를 줄이고 NameNode 시작 프로세스를 빠르게 만드는 작업입니다. 체크포인트는 Secondary NameNode에서 수행됩니다.
대용량 데이터 세트를 가진 애플리케이션에 HDFS를 사용하는 이유는 무엇인가?
답변: HDFS는 분산 파일 시스템을 구현하는 DataNode 및 NameNode 아키텍처를 제공합니다.
이러한 아키텍처를 통해 확장성이 뛰어난 Hadoop 클러스터에서 데이터에 대한 고성능 액세스를 제공할 수 있습니다. NameNode는 파일 시스템의 메타데이터를 RAM에 저장하므로 메모리 용량이 HDFS 파일 시스템 파일 수를 제한합니다.
`jps` 명령의 기능은 무엇인가?
답변: `jps` (Java Virtual Machine Process Status) 명령은 NodeManager, DataNode, NameNode, ResourceManager 등 특정 Hadoop 데몬이 실행 중인지 확인하는 데 사용됩니다. 이 명령은 호스트에서 운영 노드를 확인하기 위해 루트 권한으로 실행해야 합니다.
Hadoop에서 '투기적 실행'이란 무엇인가?
답변: Hadoop에서 마스터 노드가 느린 작업을 감지하면, 해당 작업을 다른 노드에서 백업 작업으로 시작하여 실행 속도를 향상시키는 프로세스입니다. 투기적 실행은 특히 작업 부하가 많은 환경에서 시간을 절약하는 데 도움이 됩니다.
Hadoop을 실행할 수 있는 세 가지 모드는 무엇인가?
답변: Hadoop이 실행될 수 있는 세 가지 주요 모드는 다음과 같습니다.
- 독립형 모드: 로컬 파일 시스템과 단일 Java 프로세스를 사용하여 Hadoop 서비스를 실행하는 기본 모드입니다.
- 의사 분산 모드: 단일 노드 Hadoop 배포를 사용하여 모든 Hadoop 서비스를 실행합니다.
- 완전 분산 모드: 분리된 노드를 사용하여 Hadoop 마스터 및 슬레이브 서비스를 실행합니다.
UDF란 무엇인가?
답변: UDF(사용자 정의 함수)는 Impala 쿼리 실행 중 열 값을 처리하는 데 사용할 수 있는 사용자 지정 함수를 코딩할 수 있는 기능입니다.
DistCp란 무엇인가?
답변: DistCp(Distributed Copy)는 여러 클러스터 간 또는 클러스터 내에서 데이터를 복사하는 데 유용한 도구입니다. MapReduce를 사용하여 DistCp는 오류 처리, 복구 및 보고 기능을 제공하며, 대량 데이터 복사를 효과적으로 구현할 수 있습니다.
답변: Hive 메타스토어는 Hive 테이블의 Apache Hive 메타데이터를 MySQL과 같은 관계형 데이터베이스에 저장하는 서비스입니다. 메타데이터에 대한 빠른 액세스를 지원하는 메타스토어 서비스 API를 제공합니다.
RDD를 정의하시오.
답변: RDD(Resilient Distributed Datasets)는 Spark의 핵심 데이터 구조로, 다양한 클러스터 노드에서 계산되는 데이터 요소의 불변 분산 컬렉션을 의미합니다.
네이티브 라이브러리를 YARN 작업에 어떻게 포함시킬 수 있는가?
답변: `-Djava.library.path` 옵션을 명령에 사용하거나, `.bashrc` 파일에서 `LD_LIBRARY_PATH`를 설정하여 네이티브 라이브러리를 포함시킬 수 있습니다. 설정 예시는 다음과 같습니다:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
HBase에서 'WAL'을 설명하시오.
답변: WAL(Write Ahead Log)은 HBase에서 MemStore의 데이터 변경 사항을 파일 기반 스토리지에 기록하는 복구 프로토콜입니다. WAL은 RegionalServer 충돌이나 MemStore 플러시 전에 데이터를 복구하는 데 사용됩니다.
YARN은 Hadoop MapReduce를 대체하는가?
답변: 아니요, YARN은 Hadoop MapReduce를 대체하는 것이 아닙니다. 대신, Hadoop 2.0 또는 MapReduce 2라고 하는 강력한 기술이 MapReduce를 지원합니다.
Hive에서 `ORDER BY`와 `SORT BY`의 차이점은 무엇인가?
답변: 두 명령 모두 Hive에서 데이터를 정렬된 방식으로 가져오지만, `SORT BY`를 사용하여 얻은 결과는 부분적으로만 정렬될 수 있습니다.
`SORT BY`는 데이터를 정렬하기 위해 여러 리듀서를 사용할 수 있으며, 이 경우 최종 결과가 부분적으로 정렬될 수 있습니다. 반면 `ORDER BY`는 전체 정렬을 위해 하나의 리듀서만 사용하며, `LIMIT` 키워드를 사용하여 정렬 시간을 단축할 수 있습니다.
Spark와 Hadoop의 차이점은 무엇인가?
답변: Hadoop과 Spark는 둘 다 분산 처리 프레임워크이지만, 처리 방식에 큰 차이가 있습니다. Hadoop은 일괄 처리에 효율적이고, Spark는 실시간 데이터 처리에 강점을 가지고 있습니다.
또한 Hadoop은 주로 HDFS에서 파일을 읽고 쓰는 반면, Spark는 Resilient Distributed Dataset(RDD) 개념을 사용하여 RAM에서 데이터를 처리합니다.
처리 시간 측면에서 Hadoop은 대기 시간이 긴 컴퓨팅 프레임워크로, 데이터를 대화식으로 처리하기에는 부적합합니다. 반면, Spark는 데이터를 대화식으로 처리할 수 있는 대기 시간이 짧은 컴퓨팅 프레임워크입니다.
Sqoop과 Flume을 비교하시오.
답변: Sqoop과 Flume은 다양한 소스에서 수집한 데이터를 HDFS에 로드하는 데 사용되는 Hadoop 도구입니다.
- Sqoop(SQL-to-Hadoop)은 Teradata, MySQL, Oracle 등과 같은 데이터베이스에서 정형 데이터를 추출하고, Flume은 데이터베이스 또는 다른 소스에서 비정형 데이터를 추출하여 HDFS에 로드하는 데 사용됩니다.
- Sqoop은 이벤트에 의해 구동되지 않지만 Flume은 이벤트 구동 방식입니다.
- Sqoop은 다양한 데이터 소스에 연결하는 방법을 알고 있는 커넥터 기반 아키텍처를 사용하는 반면, Flume은 에이전트 기반 아키텍처를 사용합니다. 여기서 데이터 가져오기를 담당하는 것은 작성된 코드인 에이전트입니다.
- Flume은 분산 특성을 가지고 있어 데이터를 쉽게 수집하고 집계할 수 있습니다. Sqoop은 병렬 데이터 전송에 유용하며, 그 결과 여러 파일로 데이터가 출력됩니다.
BloomMapFile에 대해 설명하시오.
답변: BloomMapFile은 MapFile 클래스를 확장한 클래스로, 동적 블룸 필터를 사용하여 키에 대한 빠른 멤버십 테스트를 제공합니다.
HiveQL과 PigLatin의 차이점을 나열하시오.
답변: HiveQL은 SQL과 유사한 선언적 언어이고, PigLatin은 높은 수준의 절차적 데이터 흐름 언어입니다.
데이터 정제란 무엇인가?
답변: 데이터 정제는 데이터 세트 내에서 잘못되었거나 불완전하거나 손상되었거나 중복되었거나 형식이 잘못된 데이터를 포함한 데이터 오류를 제거하거나 수정하는 중요한 프로세스입니다.
이 프로세스는 데이터 품질을 개선하고 조직 내에서 효율적인 의사 결정에 필요한 보다 정확하고 일관되며 신뢰할 수 있는 정보를 제공하는 것을 목표로 합니다.
결론 💃
빅 데이터와 Hadoop 분야의 채용 기회가 증가하고 있는 현재, 여러분의 취업 성공 가능성을 높이고 싶으실 겁니다. 이 글에서 제공된 Hadoop 인터뷰 질문과 답변이 다가오는 인터뷰에서 좋은 결과를 얻는 데 도움이 되기를 바랍니다.
다음 단계로 빅 데이터와 Hadoop 학습을 위한 유용한 자료를 찾아보시는 것도 좋습니다.
행운을 빕니다! 👍