코드 예제가 포함된 완전한 가이드
본 튜토리얼에서는 파이썬 집합의 기본 원리와, 집합을 조작하는 데 활용 가능한 다양한 메서드들을 학습합니다.
집합은 파이썬의 내장 데이터 구조 중 하나입니다. 중복 없는 요소들의 모음을 다루어야 할 때, 집합은 아주 유용한 데이터 구조가 됩니다.
다음 여러 섹션에서 파이썬 집합의 핵심 사항과 활용 가능한 다양한 집합 메서드들을 살펴볼 것입니다. 더불어, 파이썬에서 기본적인 집합 연산을 수행하는 방법도 배우게 됩니다.
자, 시작해 볼까요!
파이썬 집합의 기초
파이썬에서 집합은 고유한(중복되지 않는) 요소들로 구성된, 순서가 없는 모음입니다. 즉, 집합 내의 모든 요소는 서로 구별되어야 합니다.
집합에서는 요소를 추가하거나 제거하는 것이 가능합니다. 따라서 집합은 변경 가능한 컬렉션입니다. 다양한 데이터 타입의 요소를 담을 수 있지만, 집합의 개별 요소는 해시 가능해야 합니다.
객체의 해시 값이 생성 후 변경되지 않는다면, 그 객체는 해시 가능하다고 말합니다. 파이썬 문자열, 튜플, 그리고 대부분의 불변 객체들은 해시 가능합니다.
집합 생성을 자세히 알아봅시다. 우선, 아래 두 가지 집합을 살펴봅시다.
py_set = {0,1,2,(2,3,4),'Cool!'}
py_set = {0,1,2,[2,3,4],'Oops!'}
# 출력 결과
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-40-2d3716c7fe01> in <module>()
----> 1 py_set = {0,1,2,[2,3,4],'Oops!'}
TypeError: unhashable type: 'list'
첫 번째 집합은 숫자, 튜플, 문자열을 포함합니다. 집합 초기화는 문제없이 실행됩니다. 반면에 두 번째 집합은 튜플 대신 리스트를 포함합니다. 리스트는 변경 가능한 컬렉션이므로 해시할 수 없어, 초기화 시 `TypeError`가 발생합니다.
📑 위 내용을 종합하면, 파이썬 집합은 고유하고 해시 가능한 요소들로 이루어진 변경 가능한 모음으로 정의할 수 있습니다.
파이썬 집합 생성 방법
이제 파이썬에서 집합을 생성하는 여러 방법을 알아보겠습니다.
#1. 명시적 초기화
파이썬에서 집합은 쉼표(,)로 구분된 요소들을 중괄호 {}로 묶어 생성할 수 있습니다.
py_set1 = {'Python','C','C++','JavaScript'}
type(py_set1)
# 출력 결과
set
파이썬 리스트를 다뤄본 경험이 있다면, 빈 리스트를 초기화할 때 []를 사용한다는 것을 알 것입니다. 하지만 파이썬 집합의 경우, 비록 중괄호 {}로 묶는 방식은 같지만, {}만으로는 집합을 초기화할 수 없습니다. 이는 {}가 파이썬 집합이 아닌, 파이썬 딕셔너리를 초기화하기 때문입니다.
py_set2 = {}
type(py_set2)
# 출력 결과
dict
`type()` 함수를 다시 호출하여 `py_set`이 딕셔너리(`dict`)인지 확인할 수 있습니다.
#2. `set()` 함수 사용
빈 집합을 초기화한 후 요소를 추가하려면 `set()` 함수를 활용하면 됩니다.
py_set3 = set() type(py_set3) # 출력 결과 set
#3. 다른 이터러블을 집합으로 변환
집합을 생성하는 또 다른 방법은 `set(iterable)`를 사용하여 리스트나 튜플 같은 다른 이터러블을 집합으로 변환하는 것입니다.
py_list = ['Python','C','C++','JavaScript','C']
py_set4 = set(py_list)
print(py_set4)
# {'C++', 'C', 'JavaScript', 'Python'} # 중복 요소 'C'는 제거됨
type(py_set4)
# set
위의 예에서 `py_list`는 'C'를 두 번 포함합니다. 하지만 `py_set4`에서는 'C'가 한 번만 나타납니다. 이는 집합이 고유한 요소의 모음이기 때문입니다. 이러한 집합 변환 기술은 종종 파이썬 리스트에서 중복을 제거하는 데 사용됩니다.
파이썬 집합에 요소 추가하는 방법
빈 집합 `py_set`을 생성하고, 이 튜토리얼의 나머지 부분에서 이를 활용해 보겠습니다.
py_set = set() len(py_set) # 집합의 길이를 반환 # 출력 결과 0
#1. `.add()` 메서드 사용
집합에 요소를 추가하려면 `.add()` 메서드를 사용할 수 있습니다. `set.add(element)`는 집합에 요소를 추가합니다.
더욱 명확하게 이해하기 위해, 파이썬 집합에 요소를 추가하고 각 단계에서 집합을 출력해 보겠습니다.
▶️ `py_set`에 'Python' 문자열을 요소로 추가해 봅시다.
py_set.add('Python')
print(py_set)
# 출력 결과
{'Python'}
이제 다른 요소를 추가해 보겠습니다.
py_set.add('C++')
print(py_set)
# 출력 결과
{'Python', 'C++'}
`.add()` 메서드는 요소가 집합에 아직 없을 경우에만 요소를 추가한다는 점을 기억하는 것이 중요합니다. 추가하려는 요소가 이미 집합에 있다면, 추가 작업은 아무런 효과가 없습니다.
이를 확인하기 위해, `py_set`에 'C++'를 다시 추가해 보겠습니다.
py_set.add('C++')
print(py_set)
# 출력 결과
{'Python', 'C++'}
집합에 이미 'C++'가 있기 때문에 추가 작업은 영향을 미치지 않습니다.
▶️ 이제 집합에 몇 가지 요소를 더 추가해 봅시다.
py_set.add('C')
print(py_set)
py_set.add('JavaScript')
print(py_set)
py_set.add('Rust')
print(py_set)
# 출력 결과
{'Python', 'C++', 'C'}
{'JavaScript', 'Python', 'C++', 'C'}
{'Rust', 'JavaScript', 'Python', 'C++', 'C'}
#2. `.update()` 메서드 사용
지금까지 한 번에 하나의 요소씩 기존 집합에 추가하는 방법을 알아봤습니다.
그렇다면, 여러 요소를 한 번에 추가하려면 어떻게 해야 할까요?
`.update()` 메서드를 `set.update(collection)` 구문과 함께 사용하면 컬렉션의 요소들을 집합에 추가할 수 있습니다. 컬렉션은 리스트, 튜플, 딕셔너리 등이 될 수 있습니다.
py_set.update(['Julia','Ruby','Scala','Java'])
print(py_set)
# 출력 결과
{'C', 'C++', 'Java', 'JavaScript', 'Julia', 'Python', 'Ruby', 'Rust', 'Scala'}
이 방법은 메모리에 다른 객체를 생성하지 않고, 요소 컬렉션을 집합에 추가하려는 경우 유용합니다.
다음 섹션에서는 집합에서 요소를 제거하는 방법을 알아보겠습니다.
파이썬 집합에서 요소 제거하는 방법
다음 집합(업데이트 작업 전의 `py_set`)을 생각해 봅시다.
py_set = {'C++', 'JavaScript', 'Python', 'Rust', 'C'}
#1. `.pop()` 메서드 사용
`set.pop()`은 집합에서 임의의 요소를 제거하고 반환합니다. `py_set`에서 `pop` 메서드를 호출하고 어떤 것을 반환하는지 확인해 보겠습니다.
py_set.pop() # 출력 결과 'Rust'
이번에는 `.pop()` 메서드 호출이 'Rust' 문자열을 반환했습니다.
참고: `.pop()` 메서드는 임의의 요소를 반환하므로, 코드를 실행할 때마다 다른 요소를 얻을 수도 있습니다.
집합을 검사해 보면 'Rust'는 더 이상 집합에 존재하지 않습니다.
print(py_set)
# 출력 결과
{'JavaScript', 'Python', 'C++', 'C'}
#2. `.remove()` 및 `.discard()` 메서드 사용
특정 요소를 집합에서 제거하고 싶을 때는 `.remove()`와 `.discard()` 메서드를 활용할 수 있습니다.
`set.remove(element)`는 집합에서 해당 요소를 제거합니다.
py_set.remove('C')
print(py_set)
# 출력 결과
{'JavaScript', 'Python', 'C++'}
집합에 존재하지 않는 요소를 제거하려고 하면 `KeyError`가 발생합니다.
py_set.remove('Scala')
# 출력 결과
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-58-a1abab3a8892> in <module>()
----> 1 py_set.remove('Scala')
KeyError: 'Scala'
다시 `py_set`을 살펴보면, 이제 세 개의 요소만 남아있습니다.
print(py_set)
# 출력 결과
{'JavaScript', 'Python', 'C++'}
`set.discard(element)` 구문을 사용하면 `.discard()` 메서드 또한 집합에서 요소를 제거합니다.
py_set.discard('C++')
print(py_set)
# 출력 결과
{'JavaScript', 'Python'}
하지만, `.remove()` 메서드와 달리, 존재하지 않는 요소를 제거하려고 할 때 `KeyError`를 발생시키지 않습니다.
`.discard()` 메서드를 사용하여 리스트에서 'Scala'(존재하지 않음)를 제거하려고 시도해도 오류는 발생하지 않습니다.
py_set.discard('Scala') # 에러 없음!
print(py_set)
# 출력 결과
{'JavaScript', 'Python'}
파이썬 집합의 요소 접근 방법
지금까지 파이썬 집합에서 요소를 추가하고 제거하는 방법을 배웠습니다. 하지만 집합의 개별 요소에 접근하는 방법을 아직 살펴보지 않았습니다.
집합은 순서가 없는 모음이므로 인덱싱할 수 없습니다. 따라서 인덱스를 사용하여 집합의 요소에 접근하려고 시도하면 아래와 같이 오류가 발생합니다.
py_set = {'C++', 'JavaScript', 'Python', 'Rust', 'C'}
print(py_set[0])
# 출력 결과
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-27-0329274f4580> in <module>()
----> 1 print(py_set[0])
TypeError: 'set' object is not subscriptable
그렇다면, 집합의 요소에는 어떻게 접근할 수 있을까요?
이를 수행하는 두 가지 일반적인 방법이 있습니다:
- 집합을 반복하여 각 요소에 접근
- 특정 요소가 집합의 멤버인지 확인
▶️ `for` 루프를 사용하여 집합과 접근 요소를 반복해 보겠습니다.
for elt in py_set: print(elt) # 출력 결과 C++ JavaScript Python Rust C
실제로는 `in` 연산자를 사용하여 주어진 요소가 집합에 있는지 확인하는 것이 더 유용할 수 있습니다.
참고: 집합의 요소가 집합에 있으면 `True`를 반환합니다. 그렇지 않으면 `False`를 반환합니다.
이 예시에서 `py_set`은 'C++'를 포함하고 'Julia'는 포함하지 않으므로, `in` 연산자는 각각 `True`와 `False`를 반환합니다.
'C++' in py_set # True 'Julia' in py_set # False
파이썬 집합의 길이 확인 방법
앞서 보았듯이 `len()` 함수를 사용하여 집합에 있는 요소의 수를 확인할 수 있습니다.
py_set = {'C++', 'JavaScript', 'Python', 'Rust', 'C'}
len(py_set)
# 출력 결과: 5
파이썬 집합 초기화 방법
모든 요소를 제거하여 집합을 초기화하려면 `.clear()` 메서드를 사용할 수 있습니다.
`py_set`에서 `.clear()` 메서드를 호출해 보겠습니다.
py_set.clear()
출력을 해보면 `set()`이 표시되는데, 이는 집합이 비어있다는 것을 나타냅니다. `len()` 함수를 호출하여 집합의 길이가 0인지 확인할 수도 있습니다.
print(py_set) # set() print(len(py_set)) # 0
지금까지 파이썬 집합에서 기본적인 CRUD 작업을 수행하는 방법을 배웠습니다.
- 생성: `set()` 함수를 사용한 타입 변환 및 초기화
- 읽기: 멤버 테스트를 위해 루프 및 `in` 연산자를 사용하여 집합의 요소에 접근
- 업데이트: 집합에 요소 추가, 제거 및 집합 업데이트
- 삭제: 집합에서 모든 요소를 제거하여 집합 초기화
파이썬 코드로 설명하는 일반적인 집합 연산
파이썬 집합을 사용하면 기본적인 집합 연산도 수행할 수 있습니다. 이번 섹션에서 이에 대해 배우게 될 것입니다.
#1. 파이썬 집합의 합집합
집합 이론에서 두 집합의 합집합은 두 집합 중 적어도 하나에 속하는 모든 요소의 집합입니다. A와 B라는 두 개의 집합이 있을 때, 합집합은 A에만 있는 요소, B에만 있는 요소, A와 B 모두에 있는 요소를 포함합니다.
집합의 합집합을 찾으려면 `|` 연산자 또는 `.union()` 메서드(`setA.union(setB)`)를 사용합니다.
setA = {1,3,5,7,9}
setB = {2,4,6,8,9}
print(setA | setB)
# 출력 결과
{1, 2, 3, 4, 5, 6, 7, 8, 9}
setA.union(setB)
# 출력 결과
{1, 2, 3, 4, 5, 6, 7, 8, 9}
집합 합집합은 교환 법칙이 성립하는 연산입니다. 따라서 AUB는 BUA와 같습니다. `.union()` 메서드 호출 시 `setA`와 `setB`의 위치를 바꿔서 이를 확인해 보겠습니다.
setB.union(setA)
# 출력 결과
{1, 2, 3, 4, 5, 6, 7, 8, 9}
#2. 파이썬 집합의 교집합
또 다른 결합 집합 연산은 두 집합 A와 B의 교집합입니다. 교집합 연산은 A와 B 모두에 있는 모든 요소를 포함하는 집합을 반환합니다.
교집합을 계산하려면, 아래 코드 조각에서 설명하는 것처럼 `&` 연산자나 `.intersection()` 메서드를 사용할 수 있습니다.
print(setA & setB)
# 출력 결과
{9}
setA.intersection(setB)
# 출력 결과
{9}
이 예시에서, 요소 9는 `setA`와 `setB` 모두에 있습니다. 따라서 교집합에는 이 요소만 포함됩니다.
집합 합집합과 마찬가지로, 집합 교집합도 교환 법칙이 성립하는 연산입니다.
setB.intersection(setA)
# 출력 결과
{9}
#3. 파이썬의 집합 차이
두 집합이 주어졌을 때, 합집합과 교집합은 각각 두 집합 중 적어도 하나에 속하는 요소와 두 집합 모두에 속하는 요소를 찾는 데 유용합니다. 반면, 집합 차이는 한 집합에는 있지만 다른 집합에는 없는 요소를 찾는 데 유용합니다.
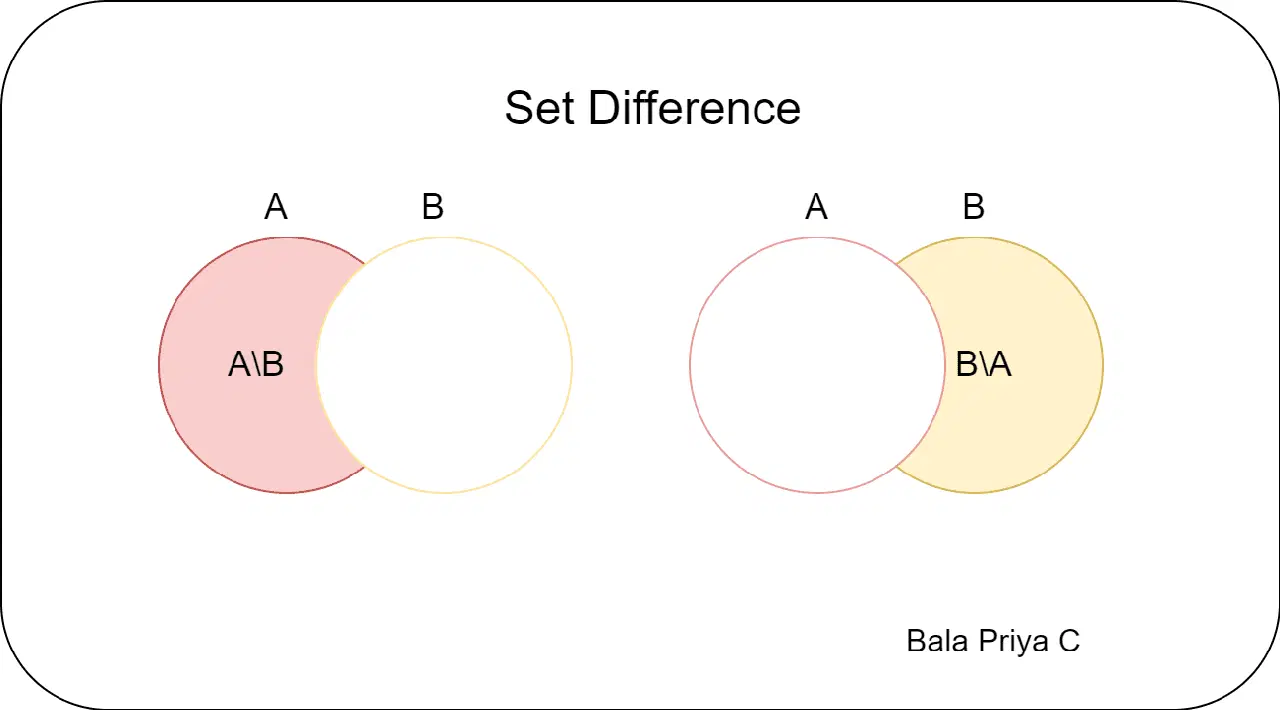
– `setA.difference(setB)`는 `setA`에는 있지만 `setB`에는 없는 요소들의 집합을 제공합니다.
– `setB.difference(setA)`는 `setB`에는 있지만 `setA`에는 없는 요소들의 집합을 제공합니다.
print(setA - setB)
print(setB - setA)
# 출력 결과
{1, 3, 5, 7}
{8, 2, 4, 6}
분명히, AB는 BA와 같지 않으므로, 집합 차이는 교환 법칙이 성립하지 않는 연산입니다.
setA.difference(setB)
# {1, 3, 5, 7}
setB.difference(setA)
# {2, 4, 6, 8}
#4. 파이썬의 대칭 집합 차이
집합 교집합은 두 집합 모두에 있는 요소를 제공하지만, 대칭 집합 차이는 정확히 한 집합에만 있는 요소의 집합을 반환합니다.
다음 예시를 고려해 봅시다.
setA = {1,3,5,7,10,12}
setB = {2,4,6,8,10,12}
대칭 차이 집합을 계산하려면 `^` 연산자나 `.symmetric_difference()` 메서드를 사용할 수 있습니다.
print(setA ^ setB)
# 출력 결과
{1, 2, 3, 4, 5, 6, 7, 8}
요소 10과 12는 `setA`와 `setB` 모두에 있습니다. 따라서 대칭 차이 집합에는 포함되지 않습니다.
setA.symmetric_difference(setB)
# 출력 결과
{1, 2, 3, 4, 5, 6, 7, 8}
대칭 집합 차이 연산은 두 집합 중 정확히 하나에 나타나는 모든 요소를 모으기 때문에, 결과 집합은 요소가 모이는 순서와 상관없이 동일합니다. 따라서, 대칭 집합 차이는 교환 법칙이 성립하는 연산입니다.
setB.symmetric_difference(setA)
# 출력 결과
{1, 2, 3, 4, 5, 6, 7, 8}
#5. 파이썬의 부분집합과 상위집합
집합 이론에서 부분집합과 상위집합은 두 집합 간의 관계를 이해하는 데 도움을 줍니다.
두 집합 A와 B가 주어졌을 때, 집합 B의 모든 요소가 집합 A에도 존재하면 집합 B는 집합 A의 부분집합입니다. 그리고 집합 A는 집합 B의 상위집합입니다.
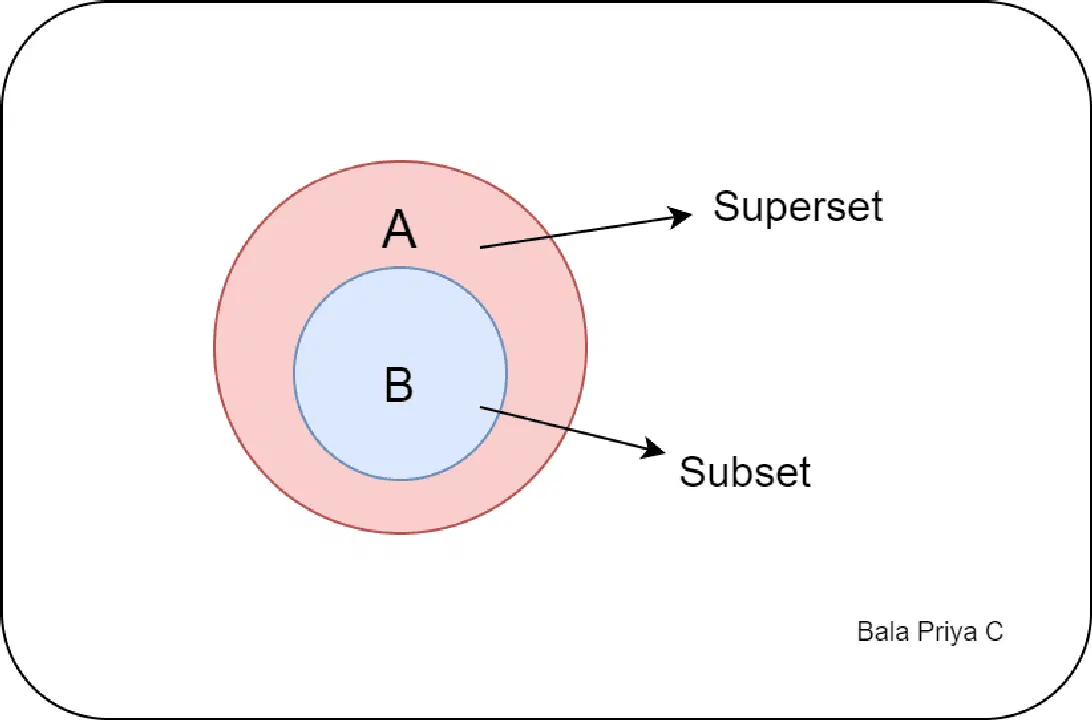
`languages`와 `languages_extended` 두 가지 예를 고려해 봅시다.
languages = {'Python', 'JavaScript','C','C++'}
languages_extended = {'Python', 'JavaScript','C','C++','Rust','Go','Scala'}
파이썬에서는 `.issubset()` 메서드를 사용하여 주어진 집합이 다른 집합의 부분집합인지 확인할 수 있습니다.
`setA.issubset(setB)`는 `setA`가 `setB`의 부분집합이면 `True`를 반환합니다. 그렇지 않으면 `False`를 반환합니다.
이 예시에서, `languages`는 `languages_extended`의 부분집합입니다.
languages.issubset(languages_extended) # 출력 결과 True
마찬가지로, `.issuperset()` 메서드를 사용하여 주어진 집합이 다른 집합의 상위집합인지 확인할 수 있습니다.
`setA.issuperset(setB)`는 `setA`가 `setB`의 상위집합이면 `True`를 반환합니다. 그렇지 않으면 `False`를 반환합니다.
languages_extended.issuperset(languages) # 출력 결과 True
`languages_extended`는 `languages`의 상위집합이므로, 위에서 볼 수 있듯이 `languages_extended.issuperset(languages)`는 `True`를 반환합니다.
결론
이 튜토리얼이 파이썬 집합의 작동 방식, CRUD 작업을 위한 집합 메서드, 일반적인 집합 연산을 이해하는 데 도움이 되었기를 바랍니다. 다음 단계로, 파이썬 프로젝트에서 직접 사용해 볼 수 있습니다.
다른 심층적인 파이썬 가이드도 확인해 보시기 바랍니다. 즐거운 학습 되세요!