제로샷 학습이란 무엇이며 AI를 어떻게 향상시킬 수 있나요?
주요 핵심 사항
- 딥러닝에서 일반화는 새로운 데이터에 대한 정확한 예측을 보장하는 데 매우 중요합니다. 제로샷 학습은 AI가 기존 지식을 활용하여 라벨링된 데이터 없이도 새로운 범주 또는 미지의 범주에 대해 정확한 예측을 가능하게 함으로써 이러한 일반화를 지원합니다.
- 제로샷 학습은 인간이 데이터를 학습하고 처리하는 방식을 모방합니다. 인간이 속이 빈 기타의 특징을 이해하고 식별할 수 있는 것처럼, 사전 학습된 모델은 추가적인 의미 정보를 제공함으로써 새로운 범주를 정확히 구별할 수 있습니다.
- 제로샷 학습은 일반화 능력과 확장성을 높이고, 과적합을 줄이며, 비용 효율성을 개선하여 AI를 발전시킵니다. 이를 통해 모델은 더 큰 데이터 세트로 훈련될 수 있고, 전이 학습을 통해 더 많은 지식을 습득하며, 상황 맥락에 대한 이해가 향상되고, 광범위한 라벨링된 데이터의 필요성이 줄어듭니다. AI 기술이 계속 발전함에 따라 제로샷 학습은 다양한 분야의 복잡한 문제를 해결하는 데 점점 더 중요한 역할을 할 것입니다.
딥러닝의 주요 목표 중 하나는 일반화된 지식을 습득한 모델을 훈련하는 것입니다. 일반화는 모델이 의미 있는 패턴을 학습했는지 확인하고 새로운 데이터 또는 이전에 접하지 못한 데이터에 대해 정확한 예측이나 결정을 내릴 수 있도록 하는 데 필수적입니다. 이러한 모델을 훈련하는 데에는 많은 양의 라벨링된 데이터가 필요하지만, 이러한 데이터는 비용이 많이 들고 수동 작업이 필요하며 때로는 얻기 어려울 수도 있습니다.
이러한 어려움을 극복하기 위해 제로샷 학습이 도입되었으며, 이를 통해 AI는 라벨링된 데이터가 부족한 상황에서도 기존 지식을 활용하여 높은 수준의 정확도를 가진 예측을 수행할 수 있습니다.
제로샷 학습이란 무엇인가?
제로샷 학습은 전이 학습 기술의 한 유형입니다. 사전 학습된 모델을 사용하고 새로운 범주의 세부 정보를 설명하는 추가 정보를 제공하여 새롭거나 이전에 본 적이 없는 범주를 식별하는 데 초점을 맞춥니다.
특정 주제에 대한 모델의 일반적인 지식을 활용하고 무엇을 찾아야 하는지에 대한 추가적인 의미를 제공함으로써, 식별해야 할 주제가 무엇인지 매우 정확하게 파악할 수 있습니다.
예를 들어, 얼룩말을 식별해야 한다고 가정해 보겠습니다. 하지만 이러한 동물을 식별할 수 있도록 훈련된 모델이 없습니다. 대신, 말을 식별하도록 훈련된 기존 모델을 가져와서 검은색과 흰색 줄무늬가 있는 말이 얼룩말이라는 정보를 제공합니다. 얼룩말과 말의 이미지를 모델에 제공하면, 모델은 각 동물을 정확하게 식별할 가능성이 높습니다.
많은 딥러닝 기술과 마찬가지로 제로샷 학습은 인간이 데이터를 배우고 처리하는 방식을 모방합니다. 인간은 본질적으로 제로샷 학습 능력이 있다고 알려져 있습니다. 만약 당신에게 음반 가게에서 속이 빈 기타를 찾아오라는 임무가 주어진다면, 당신은 어려움을 겪을 수 있습니다. 하지만 만약 속이 빈 기타가 기본적으로 한쪽 또는 양쪽에 'f'자 모양의 구멍이 있는 기타라고 알려준다면, 당신은 아마도 즉시 찾을 수 있을 것입니다.

실제 예로, 오픈 소스 LLM 호스팅 사이트인 Hugging Face에서 Clip-vit-large 모델을 사용하는 제로샷 분류 앱을 사용해 보겠습니다.
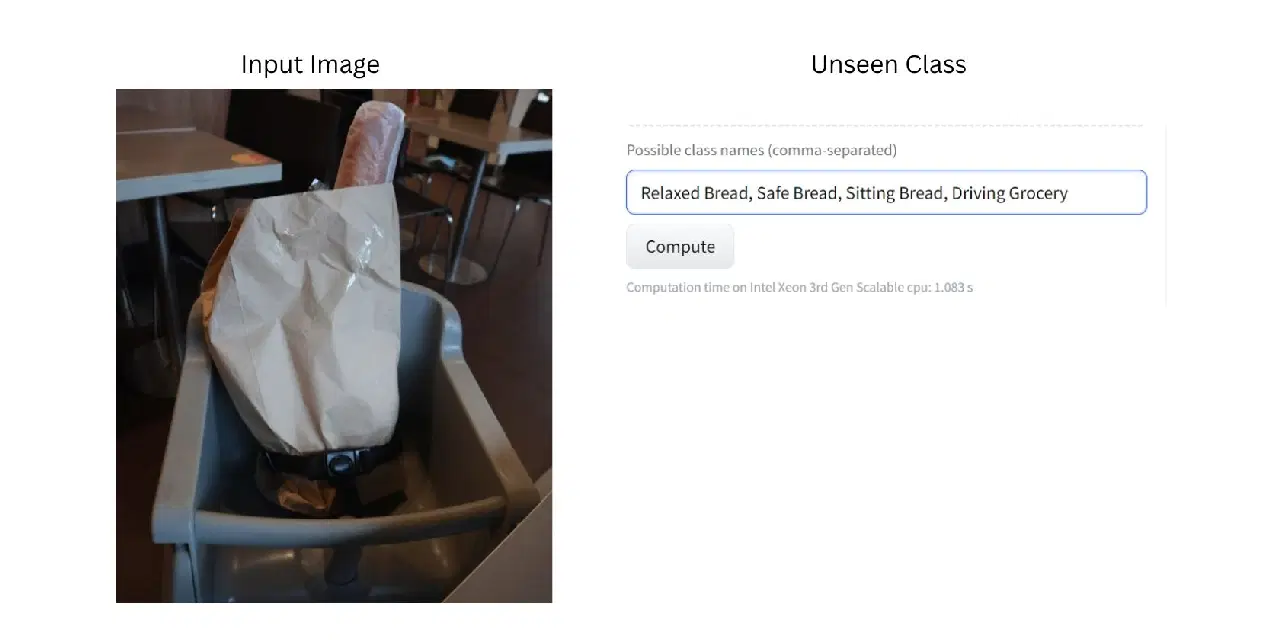
제공된 사진에는 높은 의자에 묶인 식료품 봉지에 담긴 빵 이미지가 있습니다. 이 모델은 방대한 이미지 데이터 세트를 학습했기 때문에 빵, 식료품, 의자, 안전벨트 등 사진에 있는 각 항목을 식별할 수 있습니다.
이제 모델이 이전에 본 적이 없는 범주를 사용하여 이미지를 분류하도록 시도해 보겠습니다. 이 경우 새로운 범주는 "편안한 빵", "안전한 빵", "앉아있는 빵", "운전하는 식료품", "안전한 식료품"이 될 것입니다.
이미지에 대한 제로샷 분류의 효율성을 보여주기 위해, 의도적으로 일반적이지 않은 범주와 이미지를 사용했습니다.
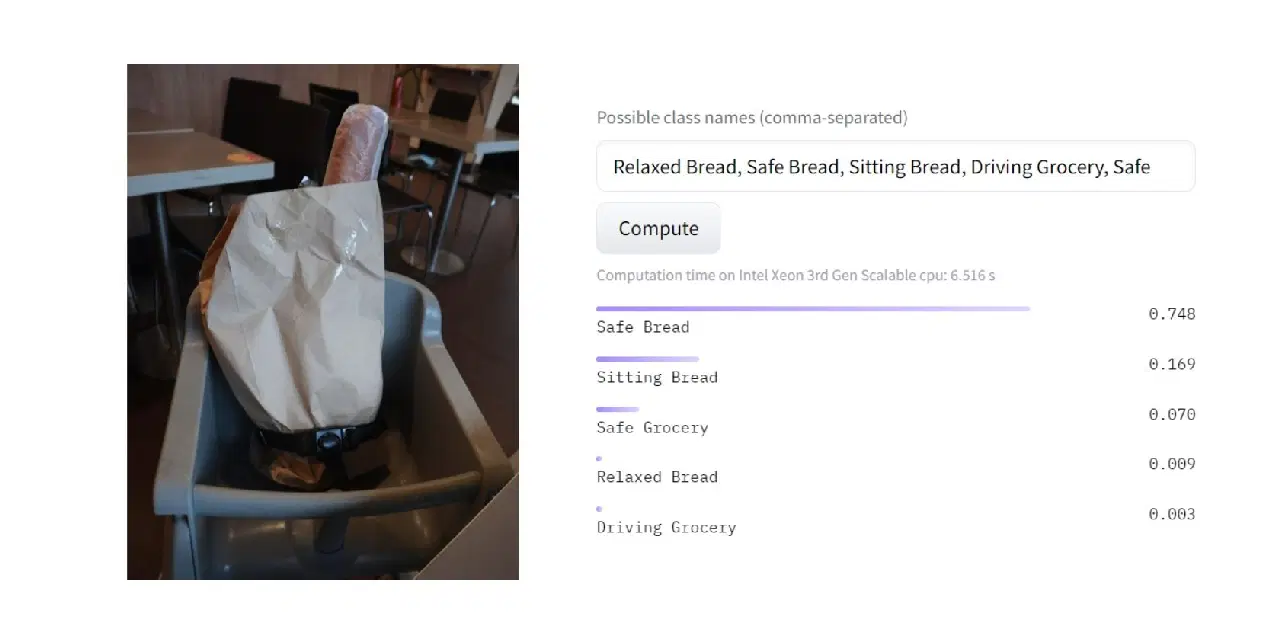
모델을 통해 추론한 결과, 약 80%의 확신도로 이미지에 가장 적합한 분류가 '안전한 빵'이라는 것을 알아냈습니다. 이는 모델이 높은 의자가 앉아 있거나 휴식을 취하거나 운전하는 것보다 안전에 더 중요하다고 인식했기 때문일 수 있습니다.
놀랍습니다! 개인적으로 모델의 결과에 동의합니다. 하지만 모델은 정확히 어떻게 이러한 결과를 도출했을까요? 다음은 제로샷 학습이 작동하는 방식에 대한 일반적인 설명입니다.
제로샷 학습은 어떻게 작동하는가?
제로샷 학습은 사전 학습된 모델이 라벨링된 데이터 없이도 새로운 범주를 식별할 수 있도록 돕습니다. 가장 단순한 형태의 제로샷 학습은 세 단계를 거쳐 이루어집니다.
1. 준비
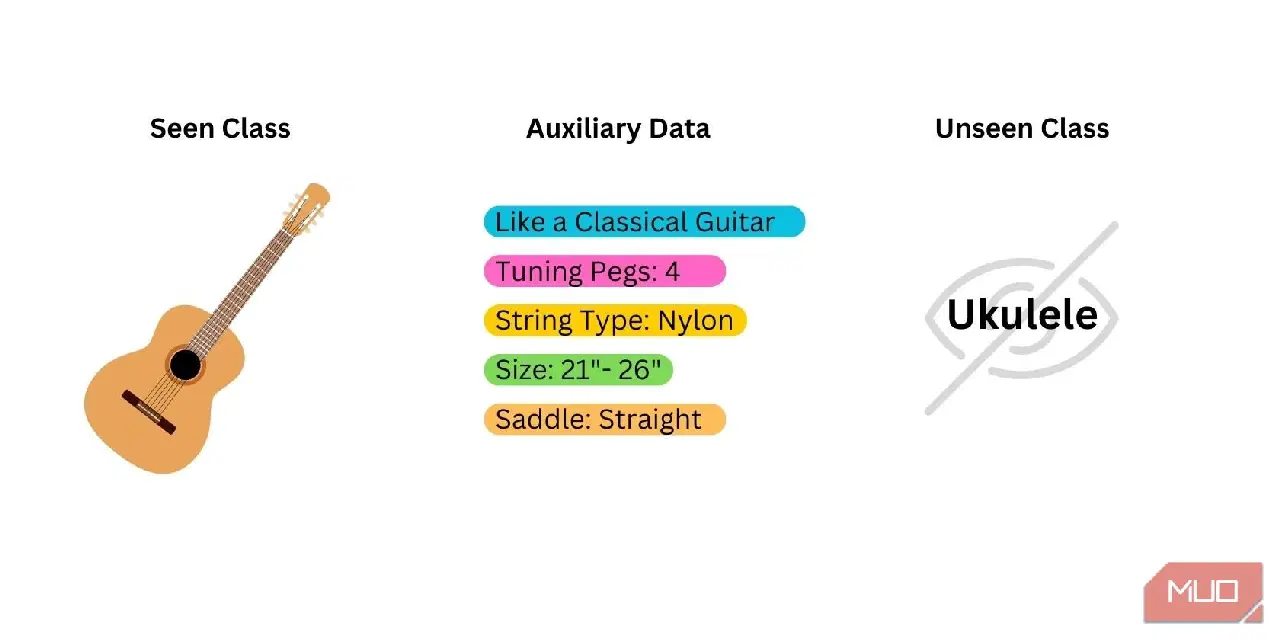
제로샷 학습은 세 가지 유형의 데이터를 준비하는 것으로 시작됩니다.
- 관찰된 범주: 사전 학습된 모델을 훈련하는 데 사용된 데이터입니다. 모델은 이미 본 범주를 제공합니다. 제로샷 학습에 가장 적합한 모델은 모델이 식별하기를 원하는 새로운 범주와 밀접하게 관련된 범주에 대해 훈련된 모델입니다.
- 보이지 않는/새로운 범주: 모델을 훈련하는 데 한 번도 사용되지 않은 데이터입니다. 이 데이터는 모델에서 얻을 수 없으므로 직접 관리해야 합니다.
- 의미/보조 데이터: 모델이 새로운 범주를 식별하는 데 도움이 될 수 있는 추가 데이터 비트입니다. 이것은 단어, 구문, 단어 임베딩 또는 범주 이름이 될 수 있습니다.
2. 의미론적 매핑
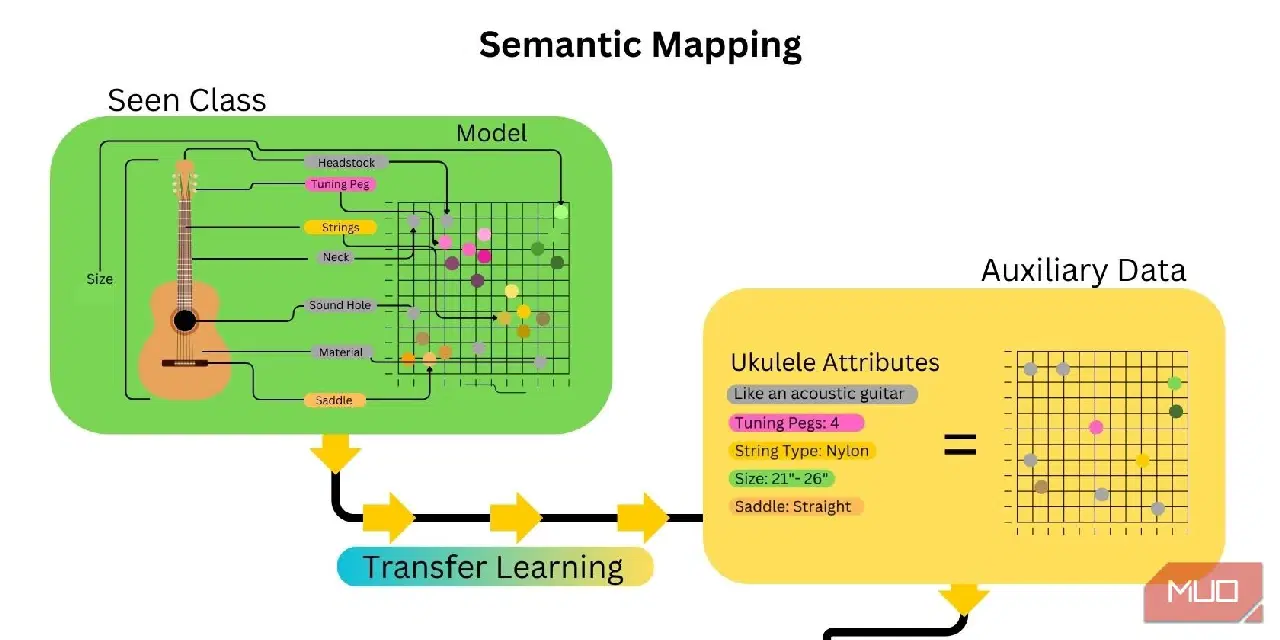
다음 단계는 보이지 않는 범주의 기능을 파악하는 것입니다. 이는 단어 임베딩을 생성하고 제공된 보조 데이터에 보이지 않는 범주의 속성 또는 특징을 연결하는 의미 체계 맵을 만들어 수행됩니다. AI 전이 학습은 보이지 않는 범주와 관련된 많은 속성이 이미 매핑되어 있기 때문에 이 과정을 훨씬 빠르게 만듭니다.
3. 추론
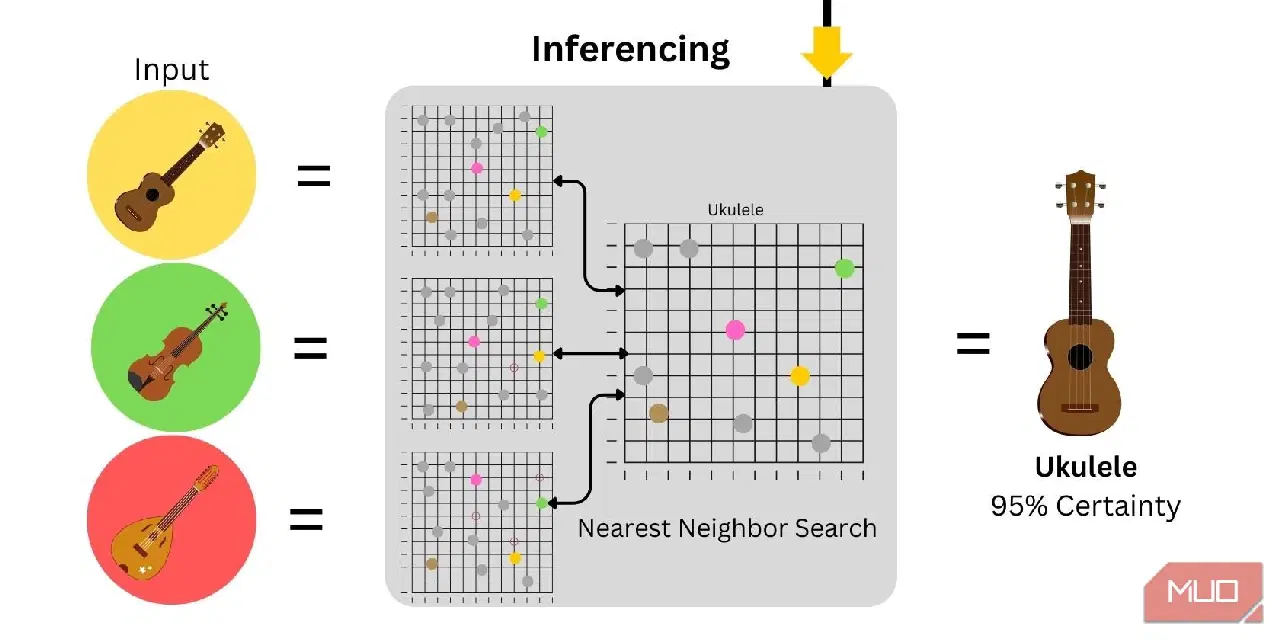
추론은 예측 또는 결과를 생성하기 위해 모델을 사용하는 것입니다. 제로샷 이미지 분류에서, 주어진 이미지 입력에 대한 단어 임베딩이 생성된 후 플롯되어 보조 데이터와 비교됩니다. 확신도는 입력과 제공된 보조 데이터 간의 유사성에 따라 달라집니다.
제로샷 학습이 AI를 향상시키는 방법
제로샷 학습은 기계 학습의 몇 가지 과제를 해결하여 AI 모델을 개선합니다. 여기에는 다음이 포함됩니다.
- 향상된 일반화: 라벨링된 데이터에 대한 의존도를 줄임으로써 더 큰 데이터 세트에서 모델을 훈련할 수 있으며, 이는 일반화 능력을 향상시켜 모델을 더욱 강력하고 신뢰할 수 있게 만듭니다. 모델이 더 많은 경험과 일반화 능력을 갖춤에 따라, 정보를 분석하는 일반적인 방법이 아닌 상식을 학습하는 것도 가능할 수 있습니다.
- 확장성: 전이 학습을 통해 모델을 지속적으로 훈련하고 더 많은 지식을 습득할 수 있습니다. 기업과 독립 연구자는 모델을 지속적으로 개선하여 미래에 더 많은 능력을 발휘할 수 있도록 할 수 있습니다.
- 과적합 가능성 감소: 과적합은 가능한 모든 입력을 표현하기에 충분한 다양성을 포함하지 않는 작은 데이터 세트로 모델을 훈련시킬 때 발생할 수 있습니다. 제로샷 학습을 통해 모델을 훈련하면 모델이 주제에 대한 더 나은 상황적 이해를 갖도록 함으로써 과적합 가능성을 줄일 수 있습니다.
- 비용 효율성: 대량의 라벨링된 데이터를 제공하는 데는 시간과 리소스가 많이 필요할 수 있습니다. 제로샷 전이 학습을 사용하면 훨씬 적은 시간과 라벨링된 데이터로 강력한 모델을 훈련할 수 있습니다.
AI 기술이 발전함에 따라 제로샷 학습과 같은 기술이 점점 더 중요해질 것입니다.
제로샷 학습의 미래
제로샷 학습은 머신 러닝의 필수적인 부분이 되었습니다. 이를 통해 모델은 명시적인 훈련 없이도 새로운 범주를 인식하고 분류할 수 있습니다. 모델 아키텍처, 속성 기반 접근 방식, 다중 모드 통합이 계속 발전함에 따라, 제로샷 학습은 로봇 공학, 의료, 컴퓨터 비전 분야의 복잡한 문제를 해결하는 데 모델의 적응력을 더욱 높이는 데 중요한 역할을 할 것입니다.