알아야 할 11가지 MongoDB 쿼리 및 작업
MongoDB는 전문가 개발 분야에서 가장 인기 있고 높이 평가받는 NoSQL 데이터베이스 중 하나입니다. 뛰어난 유연성, 확장성, 그리고 방대한 양의 데이터 처리 능력은 현대적인 애플리케이션 개발에 있어 최고의 선택지로 자리매김했습니다. 만약 여러분이 MongoDB의 기본적인 쿼리와 작동 방식을 완전히 이해하고 싶으시다면, 제대로 찾아오셨습니다.
오늘의 MUO 비디오
계속해서 내용을 확인하시려면 스크롤해주세요.
데이터를 효율적으로 검색하고 조작하는 것부터, 강력한 데이터 모델을 구축하고, 사용자 반응성이 뛰어난 애플리케이션을 만드는 것까지, MongoDB의 기본적인 쿼리 및 작동 방식에 대한 깊이 있는 이해는 여러분의 기술 수준을 한 단계 더 끌어올릴 것입니다.
1. 데이터베이스 생성 또는 변경
MongoDB 셸을 통해 로컬에서 데이터베이스를 만드는 것은, 특히 원격 클러스터를 설정한 경우 매우 간단합니다. `use` 명령어를 사용하면 MongoDB에서 새로운 데이터베이스를 만들 수 있습니다.
use db_이름
위 명령어는 새로운 데이터베이스를 생성하는 동시에, 기존 데이터베이스로 전환하는 데에도 사용될 수 있습니다.
2. 데이터베이스 삭제
먼저, 이전과 같이 `use` 명령어를 사용하여 삭제하고자 하는 데이터베이스로 전환해야 합니다. 그 후, `dropDatabase()` 명령어를 사용하여 해당 데이터베이스를 삭제할 수 있습니다.
use db_이름
db.dropDatabase()
3. 컬렉션 생성
컬렉션을 생성하려면, 먼저 해당 데이터베이스로 전환해야 합니다. `createCollection()` 키워드를 사용하면 새로운 MongoDB 컬렉션을 만들 수 있습니다.
db.createCollection("컬렉션_이름")
`컬렉션_이름` 부분을 여러분이 원하는 컬렉션 이름으로 바꿔주세요.
4. 컬렉션에 문서 삽입
컬렉션에 데이터를 추가할 때, 하나의 문서 또는 문서들의 배열을 삽입할 수 있습니다.
하나의 문서를 삽입하는 방법:
db.컬렉션_이름.insertOne({"이름":"이도우", "좋아하는것":"체스"})
위와 같은 방식으로, 하나의 ID로 구성된 문서 배열도 삽입할 수 있습니다.
db.컬렉션_이름.insertOne([{"이름":"이도우", "좋아하는것":"체스"}, {"언어": "몽고", "관리자여부": true}])
여러 개의 문서를 각각 다른 ID를 가지도록 한 번에 삽입하려면, `insertMany` 키워드를 사용하세요.
db.컬렉션_이름.insertMany([{"이름":"이도우", "좋아하는것":"체스"}, {"이름": "폴", "좋아하는것": "워들"}])
5. 컬렉션에서 모든 문서 가져오기
`find()` 키워드를 사용하여 컬렉션 내의 모든 문서를 쿼리할 수 있습니다.
db.컬렉션_이름.find()
위 명령어는 해당 컬렉션 내의 모든 문서를 반환합니다.
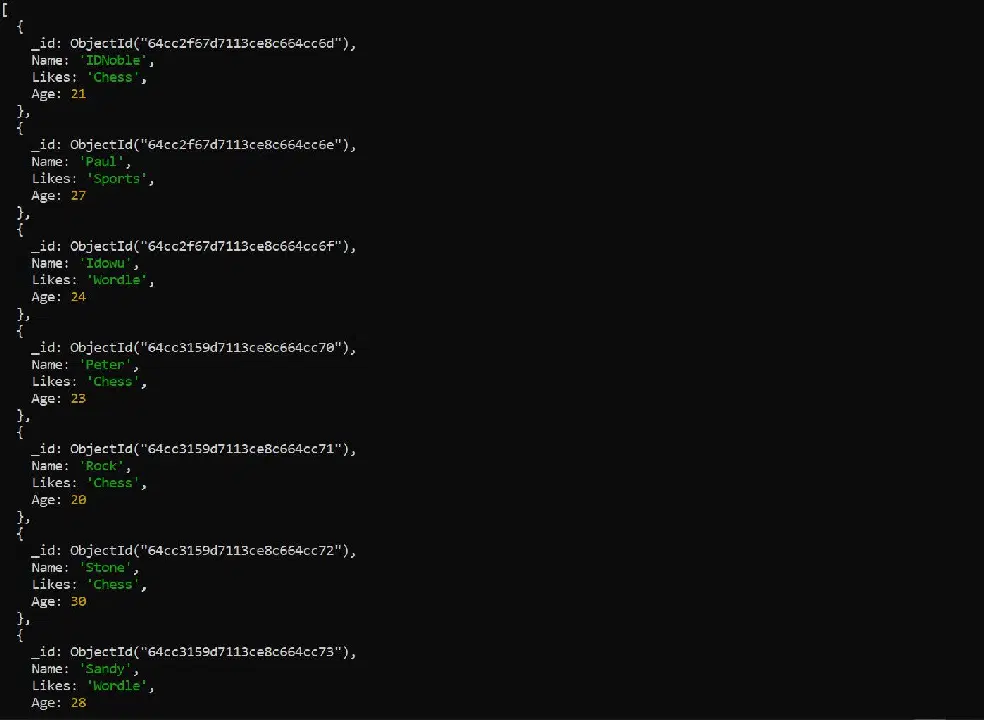
반환되는 데이터의 양을 특정 숫자로 제한할 수도 있습니다. 예를 들어, 다음 명령을 사용하여 처음 두 개의 문서만 가져올 수 있습니다.
db.컬렉션_이름.find().limit(2)
6. 컬렉션 내의 문서 필터링
MongoDB에서 문서를 필터링하는 여러 가지 방법이 존재합니다. 다음 데이터를 예시로 들어보겠습니다.
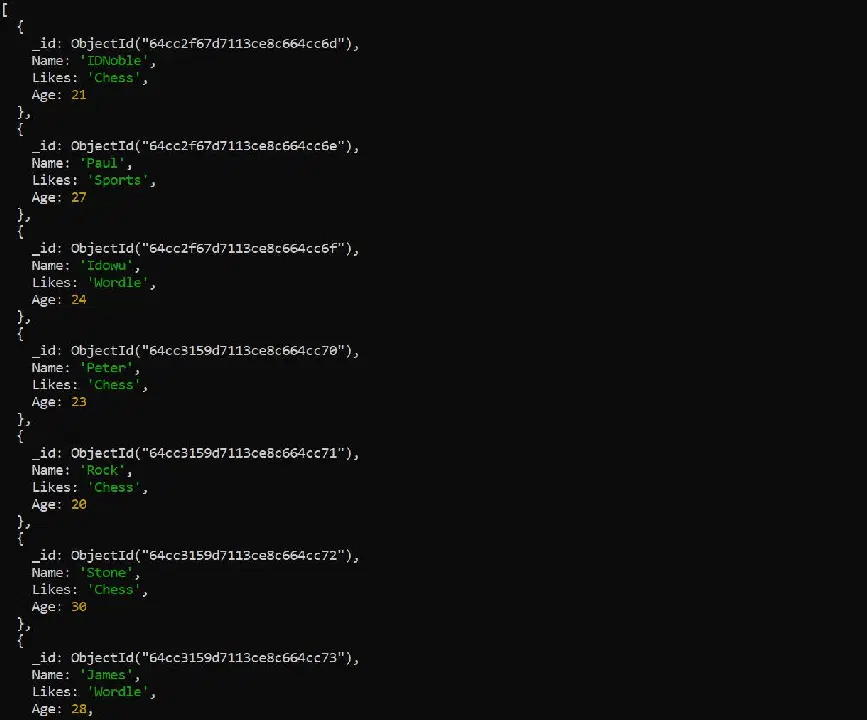
만약 문서의 특정 필드만 쿼리하고 싶다면, `find` 메서드를 사용하면 됩니다.
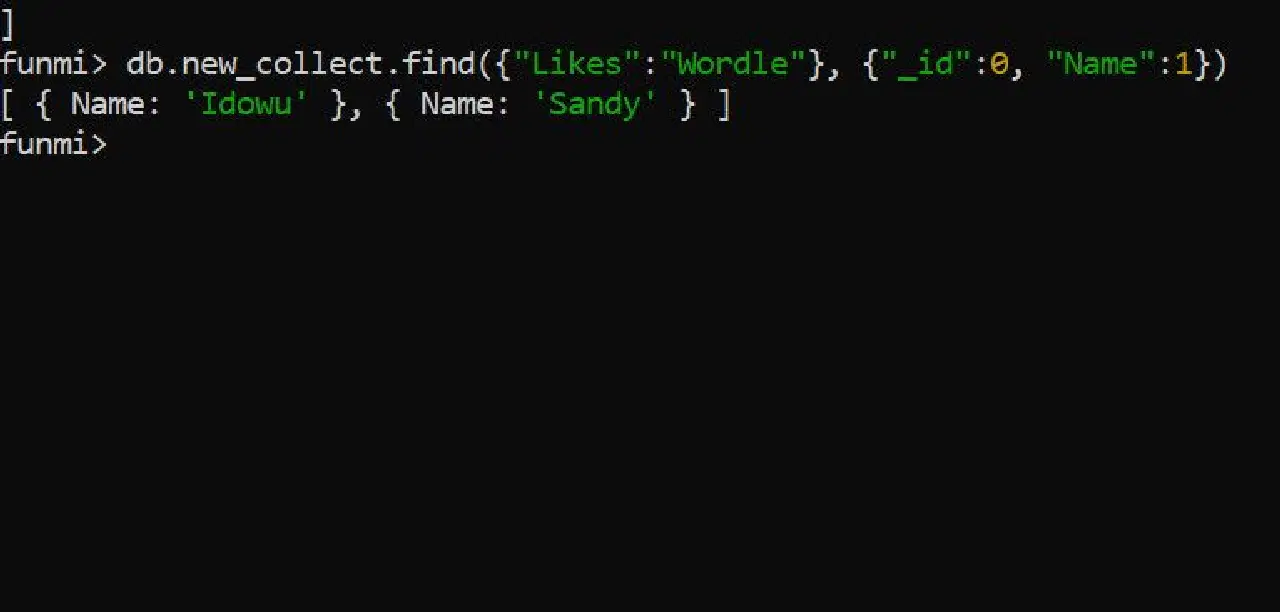
db.컬렉션_이름.find({"좋아하는것":"워들"}, {"_id":0, "이름":1})
위 명령어는 '좋아하는것' 값이 '워들'인 모든 문서를 반환하며, 이름만 출력하고 문서 ID는 제외합니다.
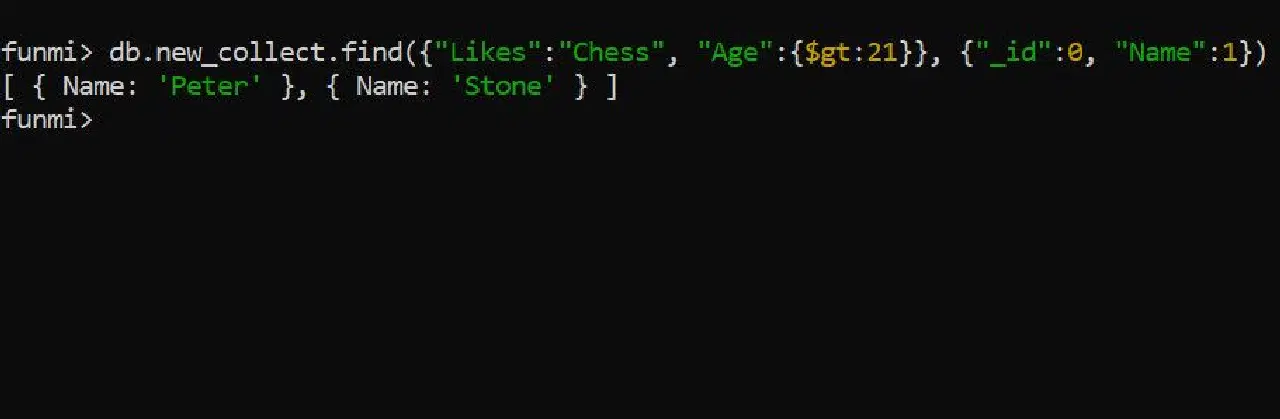
숫자 요소를 기준으로 컬렉션을 필터링하는 것도 가능합니다. 21세 이상의 모든 사용자 이름을 가져오려면 `$gt` 연산자를 사용하세요.
db.컬렉션_이름.find({"좋아하는것":"체스", "나이":{"$gt":21}}, {"_id":0, "이름":1})
결과 출력은 다음과 같습니다.
`find`를 `findOne`으로 바꿔서 어떤 결과가 나타나는지 확인해보세요. 이 외에도 다양한 필터링 키워드가 있습니다.
- $lt: 지정된 값보다 작은 모든 값.
- $gte: 지정된 값보다 크거나 같은 값.
- $lte: 지정된 값보다 작거나 같은 값.
- $eq: 지정된 값과 동일한 모든 값.
- $ne: 지정된 값과 같지 않은 모든 값.
- $in: 배열을 기반으로 쿼리할 때 사용되며, 배열의 항목과 일치하는 모든 값을 가져옵니다. 반대로 `$nin` 키워드는 일치하지 않는 값을 가져옵니다.
7. 쿼리 정렬
정렬은 쿼리 결과를 특정 순서로 정렬하는 데 사용됩니다. 내림차순 또는 오름차순으로 정렬할 수 있으며, 이를 위해서는 숫자 참조가 필요합니다.
예를 들어 오름차순으로 정렬하려면 다음과 같이 합니다.
db.컬렉션_이름.find({"좋아하는것":"체스"}).sort({"나이":1})
위 쿼리를 내림차순으로 정렬하고 싶다면 "1"을 "-1"로 바꾸면 됩니다.
db.컬렉션_이름.find({"좋아하는것":"체스"}).sort({"나이":-1})
8. 문서 업데이트
MongoDB에서 문서를 업데이트할 때는, 업데이트 방식을 지정하기 위해 원자 연산자가 필요합니다. 아래는 업데이트 쿼리에 자주 사용되는 원자 연산자 목록입니다.
- $set: 새로운 필드를 추가하거나 기존 필드를 변경합니다.
- $push: 새로운 항목을 배열에 삽입합니다. 여러 항목을 한 번에 추가하려면 `$each` 연산자와 함께 사용합니다.
- $pull: 배열에서 특정 항목을 제거합니다. 여러 항목을 한 번에 제거하려면 `$in`과 함께 사용합니다.
- $unset: 문서에서 특정 필드를 제거합니다.
예를 들어, 문서를 업데이트하고 새로운 필드를 추가하려면 다음과 같이 합니다.
db.컬렉션_이름.updateOne({"이름":"샌디"}, {"$set":{"이름":"제임스", "이메일":"[email protected]"}})
위 명령어는 지정된 문서를 다음과 같이 업데이트합니다.
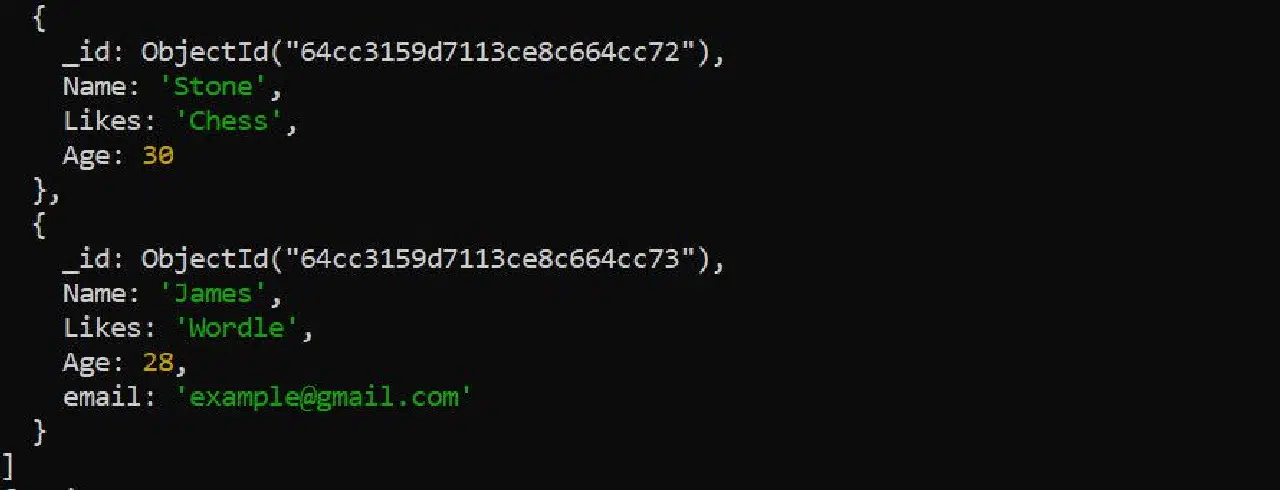
이메일 필드를 제거하는 것은 `$unset` 연산자를 사용하면 간단합니다.
db.컬렉션_이름.updateOne({"이름":"샌디"}, {"$unset":{"이메일":"[email protected]"}})
다음 샘플 데이터를 참고하세요.
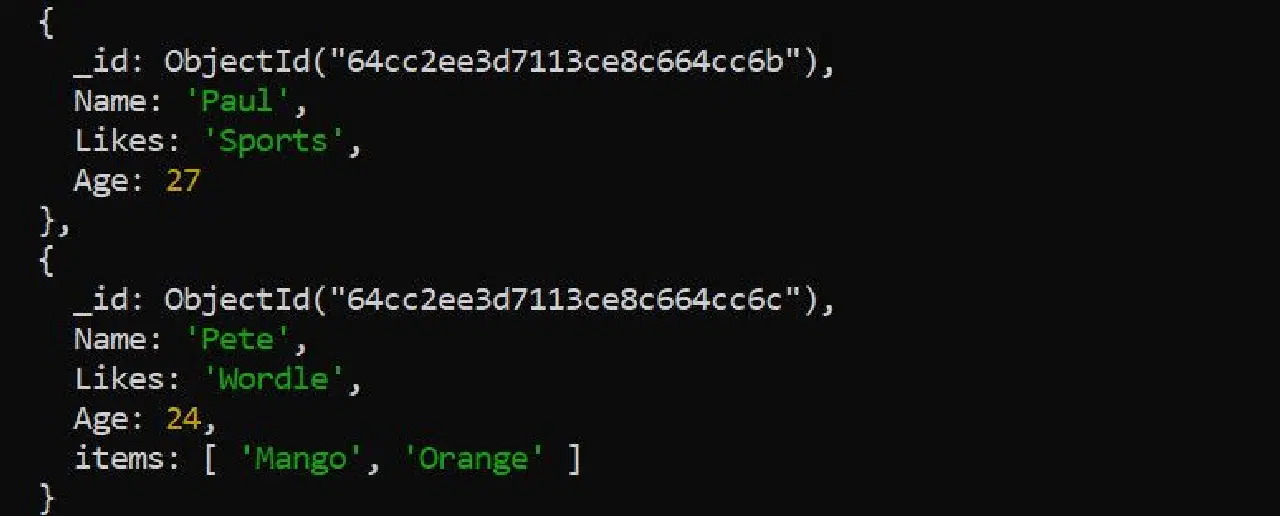
`$push` 연산자를 사용하여 기존 항목 배열 필드에 항목을 추가할 수 있습니다.
db.컬렉션_이름.updateOne({"이름":"피트"}, {"$push":{"항목들":"플랜테인"}})
결과는 다음과 같습니다.
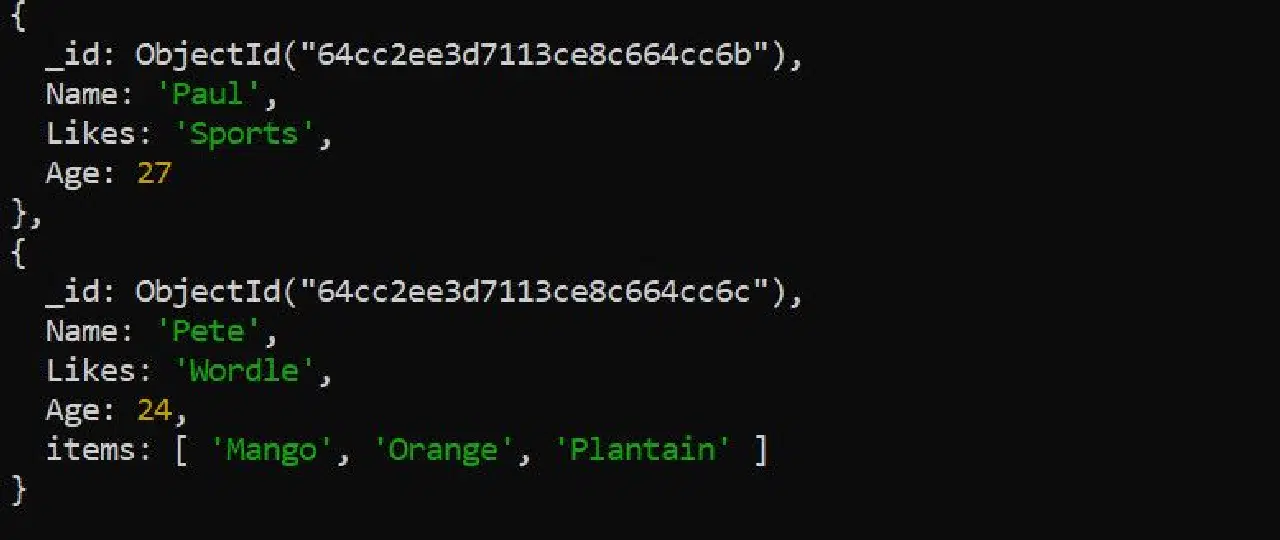
여러 개의 항목을 한 번에 삽입하려면 `$each` 연산자를 사용하세요.
db.컬렉션_이름.updateOne({"이름":"피트"}, {"$push":{"항목들": {"$each":["아몬드", "멜론"]}}})
결과는 다음과 같습니다.
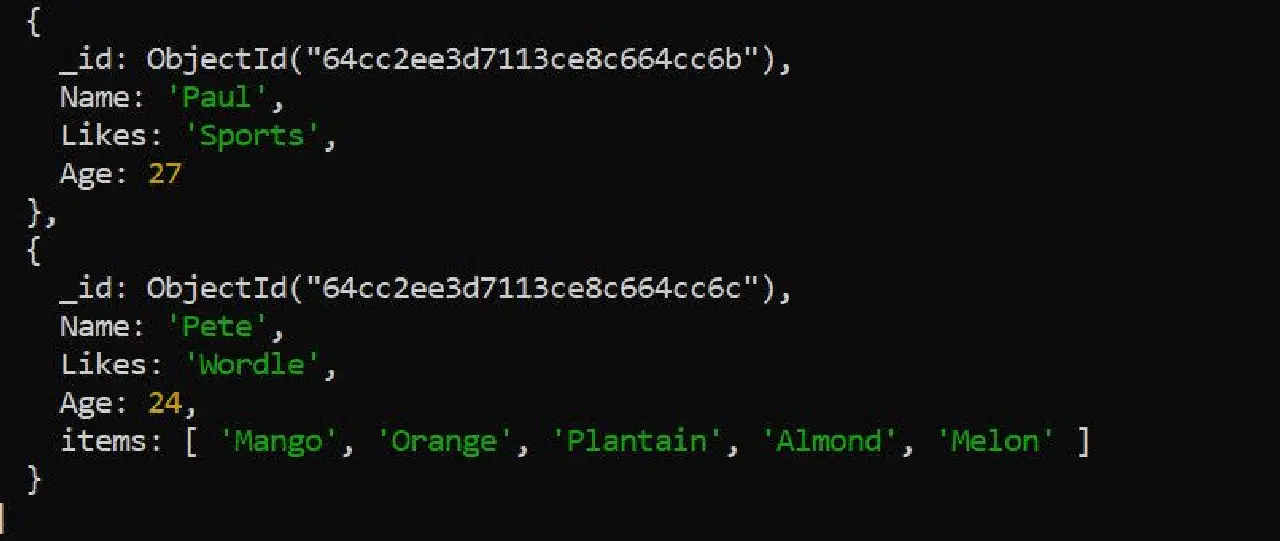
언급했듯이, `$pull` 연산자는 배열에서 특정 항목을 제거합니다.
db.컬렉션_이름.updateOne({"이름":"피트"}, {"$pull":{"항목들":"플랜테인"}})
업데이트된 데이터는 다음과 같습니다.
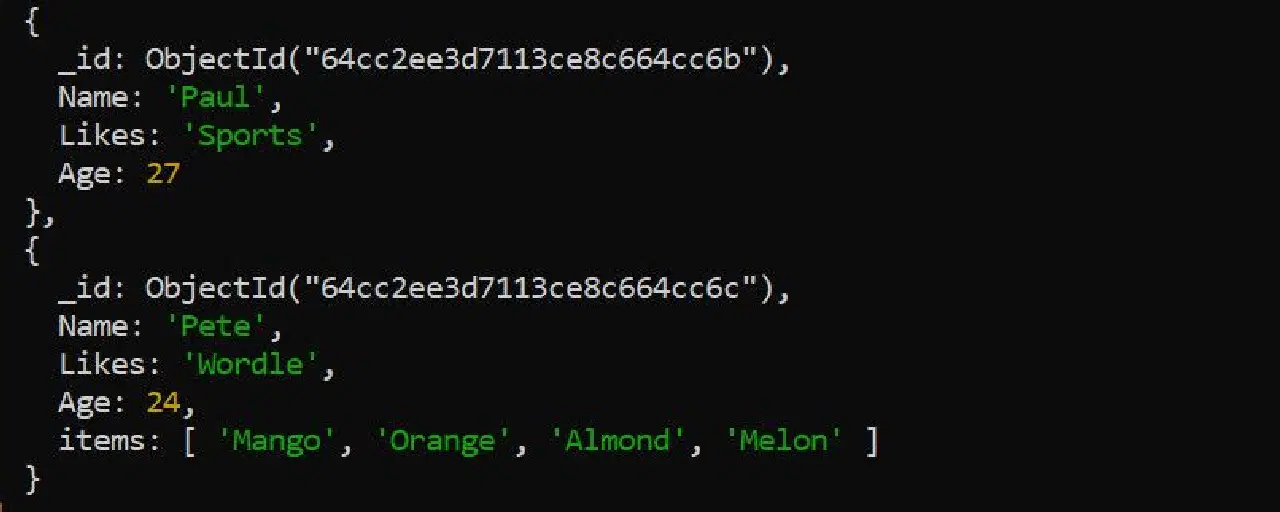
한 번에 배열에서 여러 항목을 제거하려면 `$in` 키워드를 포함합니다.
db.컬렉션_이름.updateOne({"이름":"피트"}, {"$pull":{"항목들": {"$in":["아몬드", "멜론"]} }})
9. 문서 또는 필드 삭제
`deleteOne` 또는 `deleteMany` 키워드를 사용하여 컬렉션에서 문서를 삭제할 수 있습니다. `deleteOne`을 사용하면 지정된 필드를 기준으로 문서를 제거합니다.
db.컬렉션_이름.deleteOne({"이름":"ID노블"})
만약 공통된 키를 가진 여러 문서를 삭제하고 싶다면, `deleteMany`를 대신 사용하세요. 아래 쿼리는 '좋아하는것'이 '체스'인 모든 문서를 삭제합니다.
db.컬렉션.deleteMany({"좋아하는것":"체스"})
10. 인덱싱 작업
인덱싱은 MongoDB가 스캔해야 하는 문서 수를 줄여 쿼리 성능을 향상시키는 방법입니다. 자주 쿼리되는 필드에 인덱스를 생성하는 것이 가장 좋습니다.
MongoDB 인덱싱은 인덱스를 사용하여 SQL 쿼리를 최적화하는 방법과 유사합니다. 예를 들어, '이름' 필드에 오름차순 인덱스를 생성하려면 다음과 같이 합니다.
db.컬렉션.createIndex({"이름":1})
인덱스를 나열하려면 다음을 실행하세요.
db.컬렉션.getIndexes()
위 내용은 MongoDB 인덱싱의 기본적인 부분일 뿐이며, 인덱스를 생성하는 더 다양한 방법이 존재합니다.
11. 집계
MapReduce의 향상된 버전인 집계 파이프라인을 사용하면 MongoDB 내부에서 복잡한 계산을 실행하고 저장할 수 있습니다. Map과 Reduce 함수를 별도의 JavaScript 함수로 작성해야 했던 MapReduce와 달리, 집계는 내장된 MongoDB 메서드만 사용하여 보다 간편하게 수행할 수 있습니다.
다음 판매 데이터를 예시로 들어보겠습니다.
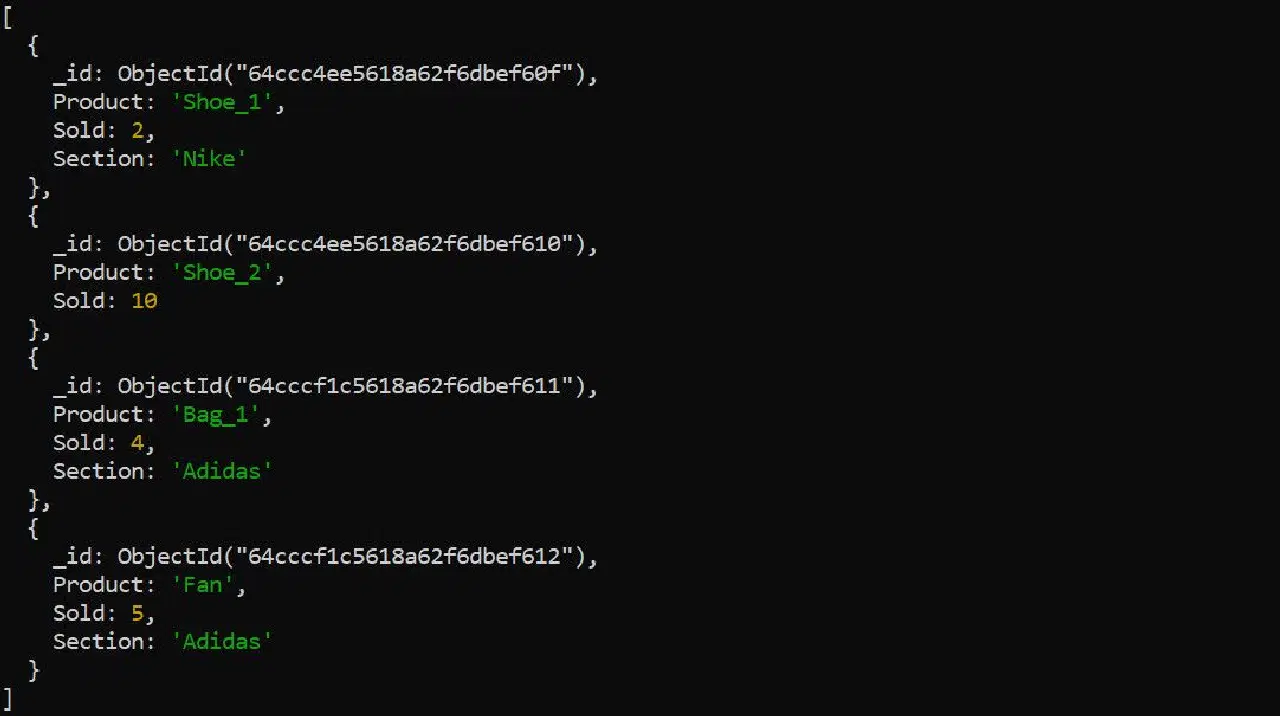
MongoDB의 집계를 사용하면, 다음 쿼리를 통해 카테고리별로 판매된 총 제품 수를 계산하고 저장할 수 있습니다.
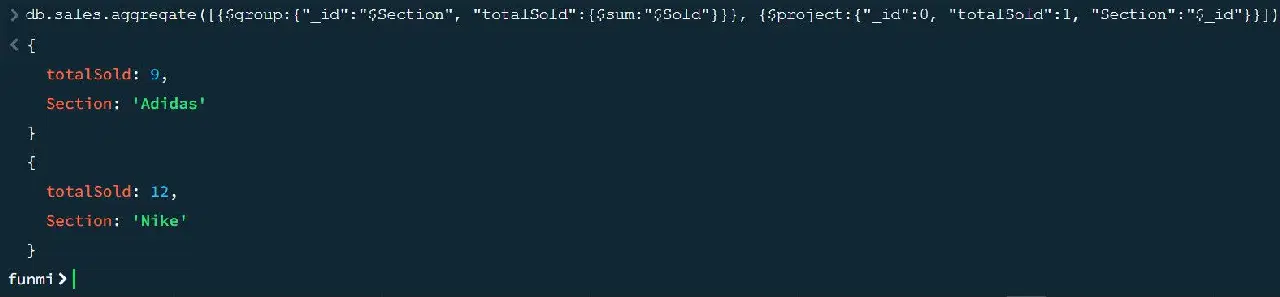
db.sales.aggregate([{$group:{"_id":"$섹션", "총판매수":{$sum:"$판매수"}}}, {$project:{"_id":0, "총판매수":1, "섹션":"$_id"}}])
위 쿼리는 다음과 같은 결과를 반환합니다.
MongoDB 쿼리 마스터하기
MongoDB는 쿼리 성능을 향상시키는 기능을 포함하여 다양한 쿼리 방법을 제공합니다. 프로그래밍 언어에 관계없이 위에서 소개된 쿼리 구조는 MongoDB 데이터베이스와 상호 작용하기 위한 기본적인 토대가 됩니다.
하지만 기본 문법에는 약간의 차이가 있을 수 있습니다. 예를 들어, Python과 같은 일부 프로그래밍 언어는 스네이크 케이스를 사용하지만, JavaScript를 포함한 다른 언어에서는 카멜 케이스를 사용합니다. 따라서 여러분이 선택한 기술에 맞춰 적절한 문법을 사용하는 것이 중요합니다.