

Apache Parquet은 CSV와 같은 기존 방법과 비교할 때 데이터 저장 및 검색에 대한 몇 가지 이점을 제공합니다.
Parquet 형식은 복잡한 유형의 더 빠른 데이터 처리를 위해 설계되었습니다. 이 기사에서는 Parquet 형식이 오늘날의 계속 증가하는 데이터 요구 사항에 어떻게 적합한지 설명합니다.
Parquet 형식에 대해 자세히 알아보기 전에 CSV 데이터가 무엇이며 데이터 저장에 대한 문제를 이해해야 합니다.
목차
CSV 스토리지란 무엇입니까?
데이터를 구성하고 형식을 지정하는 가장 일반적인 방법 중 하나인 CSV(쉼표로 구분된 값)에 대해 많이 들었습니다. CSV 데이터 저장소는 행 기반입니다. CSV 파일은 .csv 확장자로 저장됩니다. Excel, Google 스프레드시트 또는 모든 텍스트 편집기를 사용하여 CSV 데이터를 저장하고 열 수 있습니다. 파일을 열면 데이터를 쉽게 볼 수 있습니다.
글쎄요, 그것은 좋지 않습니다. 확실히 데이터베이스 형식에는 적합하지 않습니다.
또한 데이터 양이 증가함에 따라 쿼리, 관리 및 검색이 어려워집니다.
다음은 .CSV 파일에 저장된 데이터의 예입니다.
EmpId,First name,Last name, Division 2012011,Sam,Butcher,IT 2013031,Mike,Johnson,Human Resource 2010052,Bill,Matthew,Architect 2010079,Jose,Brian,IT 2012120,Adam,James,Solutions
Excel에서 보면 아래와 같은 행-열 구조를 볼 수 있습니다.
CSV 저장소의 과제
CSV와 같은 행 기반 저장소는 생성, 업데이트 및 삭제 작업에 적합합니다.
그렇다면 CRUD에서 읽기는 어떻습니까?
위의 .csv 파일에 백만 개의 행이 있다고 상상해 보십시오. 파일을 열고 원하는 데이터를 검색하려면 상당한 시간이 걸립니다. 그렇게 멋지지 않습니다. AWS와 같은 대부분의 클라우드 제공업체는 스캔하거나 저장된 데이터의 양에 따라 회사에 요금을 부과합니다. 다시 말하지만 CSV 파일은 많은 공간을 소비합니다.
CSV 저장소에는 메타데이터를 저장하는 독점적인 옵션이 없으므로 데이터 스캔을 지루한 작업으로 만듭니다.
그렇다면 모든 CRUD 작업을 수행하기 위한 비용 효율적이고 최적의 솔루션은 무엇입니까? 탐색해 봅시다.
Parquet 데이터 스토리지란 무엇입니까?
쪽매 세공 데이터를 저장하는 오픈 소스 저장 형식입니다. Hadoop 및 Spark 생태계에서 널리 사용됩니다. Parquet 파일은 .parquet 확장자로 저장됩니다.
마루는 고도로 구조화된 형식입니다. 또한 데이터 레이크에 대량으로 존재하는 복잡한 원시 데이터를 최적화하는 데 사용할 수도 있습니다. 이렇게 하면 쿼리 시간을 크게 줄일 수 있습니다.
Parquet은 행 및 열 기반(하이브리드) 스토리지 형식이 혼합되어 있기 때문에 데이터 스토리지를 효율적으로 만들고 더 빠르게 검색할 수 있습니다. 이 형식에서는 데이터가 가로 및 세로로 분할됩니다. Parquet 형식은 또한 구문 분석 오버헤드를 상당 부분 제거합니다.
형식은 전체 I/O 작업 수와 궁극적으로 비용을 제한합니다.
Parquet은 또한 데이터 스키마, 값 수, 열 위치, 최소값, 행 그룹의 최대값 수, 인코딩 유형 등과 같은 데이터에 대한 정보를 저장하는 메타데이터를 저장합니다. 메타데이터는 파일의 다른 수준에 저장됩니다. , 데이터 액세스를 더 빠르게 만듭니다.
CSV와 같은 행 기반 액세스에서는 쿼리가 각 행을 탐색하고 특정 열 값을 가져와야 하므로 데이터 검색에 시간이 걸립니다. Parquet 스토리지를 사용하면 필요한 모든 열을 한 번에 액세스할 수 있습니다.
요약해서 말하자면,
- Parquet은 데이터 저장을 위한 기둥 구조를 기반으로 합니다.
- 스토리지 시스템에 복잡한 데이터를 대량으로 저장하는 데 최적화된 데이터 형식입니다.
- Parquet 형식에는 데이터 압축 및 인코딩을 위한 다양한 방법이 포함됩니다.
- CSV와 같은 다른 저장 형식에 비해 데이터 스캔 시간 및 쿼리 시간을 크게 줄이고 디스크 공간을 덜 차지합니다.
- IO 작업 수를 최소화하여 스토리지 및 쿼리 실행 비용 절감
- 데이터를 더 쉽게 찾을 수 있는 메타데이터 포함
- 오픈 소스 지원 제공
쪽모이 세공 데이터 형식
예제를 시작하기 전에 데이터가 Parquet 형식으로 저장되는 방식을 더 자세히 이해하겠습니다.
하나의 파일에 행 그룹으로 알려진 여러 수평 파티션을 가질 수 있습니다. 각 행 그룹 내에서 수직 분할이 적용됩니다. 열은 여러 열 청크로 분할됩니다. 데이터는 열 청크 내부에 페이지로 저장됩니다. 각 페이지에는 인코딩된 데이터 값과 메타데이터가 포함되어 있습니다. 앞에서 언급했듯이 전체 파일에 대한 메타데이터는 행 그룹 수준의 파일 바닥글에도 저장됩니다.
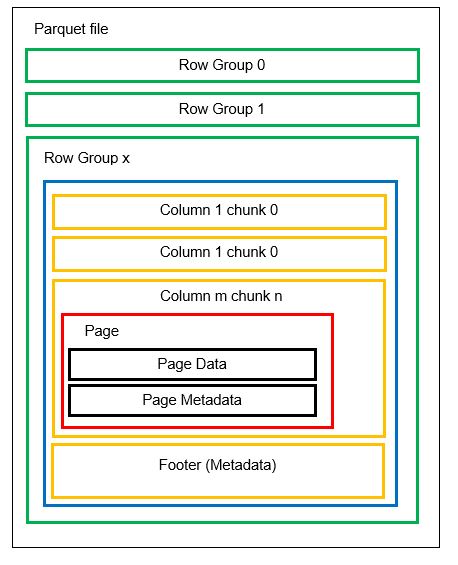
데이터가 컬럼 청크로 분할되기 때문에 새로운 값을 새로운 청크와 파일로 인코딩하여 새로운 데이터를 추가하는 것도 쉽습니다. 그런 다음 영향을 받는 파일 및 행 그룹에 대한 메타데이터가 업데이트됩니다. 따라서 Parquet은 유연한 형식이라고 말할 수 있습니다.
Parquet은 기본적으로 페이지 압축 및 사전 인코딩 기술을 사용하여 데이터 압축을 지원합니다. 사전 압축의 간단한 예를 살펴보겠습니다.
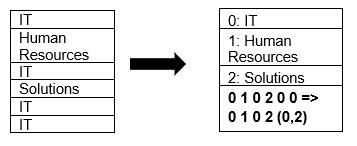
위의 예에서는 IT 부서가 4번 나타납니다. 그래서 사전에 저장하면서 계속 반복되는 횟수와 함께 저장하기 쉬운 또 다른 값(0,1,2…)으로 데이터를 인코딩하여 저장합니다. 더 많은 공간. 압축된 데이터를 쿼리하는 데 시간이 덜 걸립니다.
일대일 비교
이제 우리는 CSV 및 Parquet 형식이 어떻게 생겼는지에 대한 공정한 아이디어를 얻었으므로 일부 통계에서 두 형식을 비교할 시간입니다.
CSV
쪽매 세공
행 기반 스토리지 형식입니다.
행 기반 및 열 기반 스토리지 형식의 하이브리드입니다.
기본 압축 옵션을 사용할 수 없기 때문에 많은 공간을 소비합니다. 예를 들어 1TB 파일은 Amazon S3 또는 다른 클라우드에 저장할 때 동일한 공간을 차지합니다.
저장하는 동안 데이터를 압축하여 공간을 덜 차지합니다. Parquet 형식으로 저장된 1TB 파일은 130GB의 공간만 차지합니다.
행 기반 검색 때문에 쿼리 실행 시간이 느립니다. 각 열에 대해 모든 데이터 행을 검색해야 합니다.
열 기반 저장 및 메타데이터의 존재로 인해 쿼리 시간이 약 34배 더 빠릅니다.
쿼리당 더 많은 데이터를 스캔해야 합니다.
쿼리 실행을 위해 스캔되는 데이터가 약 99% 적어 성능이 최적화됩니다.
대부분의 저장 장치는 저장 공간에 따라 요금이 청구되므로 CSV 형식은 저장 비용이 많이 듭니다.
데이터가 압축되고 인코딩된 형식으로 저장되므로 저장 비용이 줄어듭니다.
파일 스키마는 유추(오류 발생)하거나 제공(지루)해야 합니다.
파일 스키마는 메타데이터에 저장됩니다.
형식은 단순 데이터 유형에 적합합니다.
Parquet은 중첩된 스키마, 배열, 사전과 같은 복잡한 유형에도 적합합니다.
결론 👩💻
비용, 유연성 및 성능 측면에서 Parquet이 CSV보다 더 효율적이라는 것을 예제를 통해 확인했습니다. 특히 전 세계가 클라우드 스토리지 및 공간 최적화로 이동할 때 데이터를 저장하고 검색하는 효과적인 메커니즘입니다. Azure, AWS 및 BigQuery와 같은 모든 주요 플랫폼은 Parquet 형식을 지원합니다.