더 간단한 용어로 설명되는 Java를 사용한 웹 스크래핑
웹 스크래핑은 인터넷에서 방대한 데이터를 신속하게 모을 수 있는 효과적인 방법입니다. 특히 웹사이트가 API(응용 프로그래밍 인터페이스)를 통해 구조화된 데이터 접근을 제공하지 않을 때 유용합니다.
예를 들어, 여러 온라인 쇼핑몰의 제품 가격을 비교하는 앱을 개발한다고 가정해 봅시다. 어떻게 이 문제를 해결할 수 있을까요? 한 가지 방법은 모든 사이트를 직접 방문하여 제품 가격을 확인하고 기록하는 것입니다. 하지만 수많은 제품과 데이터 추출에 많은 시간이 소요되므로 이는 비효율적인 방법입니다.
더 나은 방법은 웹 스크래핑을 활용하는 것입니다. 웹 스크래핑은 소프트웨어를 이용하여 웹페이지 및 웹사이트에서 자동으로 데이터를 수집하는 과정입니다.
웹 스크래퍼라고 불리는 소프트웨어 스크립트는 웹사이트에 접속하여 데이터를 가져오는 데 사용됩니다. 이렇게 얻은 비정형 데이터는 분석 및 저장이 용이하도록 구조화된 형태로 변환됩니다.
웹 스크래핑은 풍부한 데이터에 대한 접근성을 제공하고 자동화를 가능하게 하므로 데이터 추출에 있어 매우 중요합니다. 예를 들어, 특정 시간이나 이벤트에 반응하여 웹 스크래핑 스크립트를 실행하도록 예약할 수 있습니다. 또한 실시간으로 업데이트된 데이터를 확보하고 시장 조사를 쉽게 수행할 수 있도록 도와줍니다.

수많은 기업과 회사들이 웹 스크래핑을 통해 데이터 분석에 필요한 정보를 수집합니다. 인적 자원, 전자상거래, 금융, 부동산, 여행, 소셜 미디어, 그리고 연구 분야에 종사하는 기업들은 웹사이트에서 관련 정보를 추출하기 위해 웹 스크래핑을 적극적으로 활용합니다.
심지어 구글조차도 웹 스크래핑을 사용하여 인터넷상의 웹사이트들을 색인화하고 사용자에게 적합한 검색 결과를 제공합니다.
하지만 웹 스크래핑을 할 때에는 신중해야 합니다. 공개된 데이터를 스크래핑하는 것은 불법이 아니지만, 일부 웹사이트에서는 스크래핑을 허용하지 않습니다. 이는 민감한 사용자 정보를 보유하고 있거나, 서비스 약관에서 웹 스크래핑을 명시적으로 금지하거나, 지적 재산을 보호해야 하기 때문일 수 있습니다.
또한, 일부 웹사이트는 웹 스크래핑이 서버에 과부하를 유발하고 대역폭 비용을 증가시킬 수 있기 때문에 스크래핑을 허용하지 않습니다. 특히 대규모 스크래핑 작업의 경우 더욱 그렇습니다.
웹사이트를 스크래핑할 수 있는지 확인하려면 웹사이트 URL에 'robots.txt'를 추가하여 확인하세요. 'robots.txt' 파일은 웹사이트의 어떤 부분을 스크래핑해도 되는지 봇에게 알려주는 역할을 합니다. 예를 들어 구글을 스크래핑할 수 있는지 확인하려면 google.com/robots.txt로 접속해 보세요.
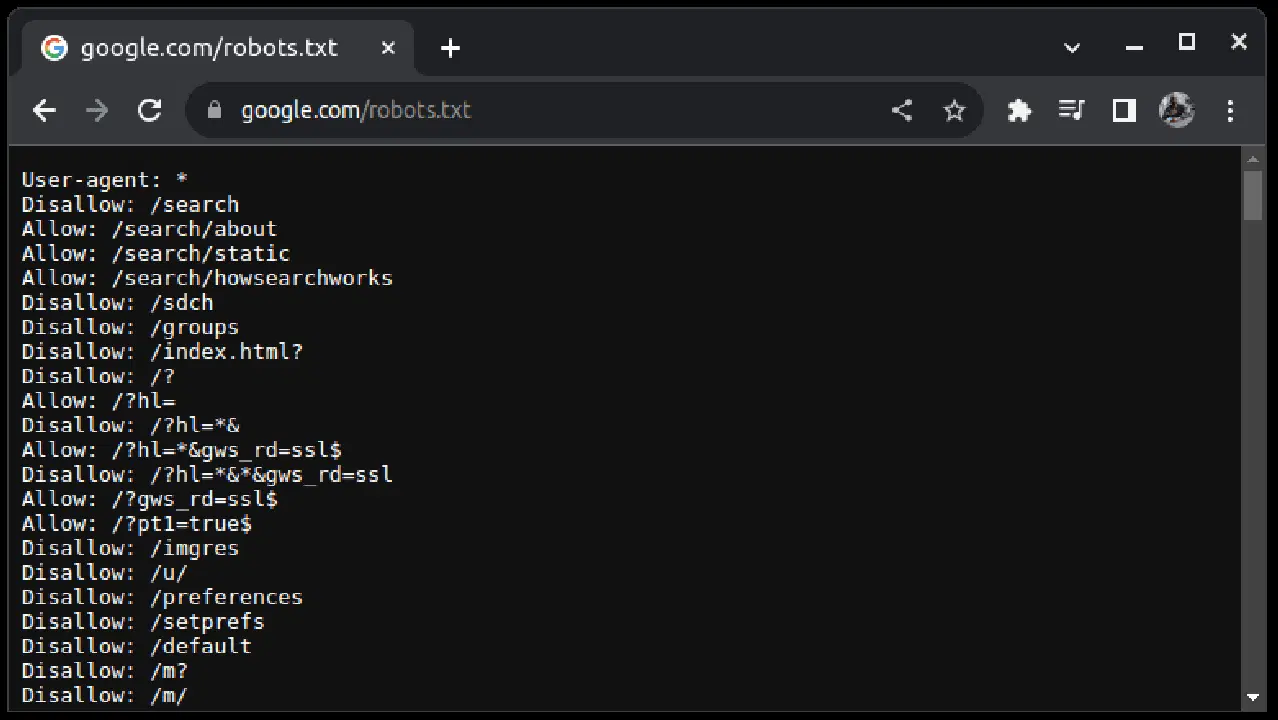
'User-agent: *'는 모든 봇, 소프트웨어 스크립트, 크롤러를 의미합니다. 'Disallow'는 봇에게 '/search'와 같은 특정 디렉터리 아래의 URL에 접근할 수 없음을 알려줍니다. 반면 'Allow'는 접근 가능한 디렉터리를 나타냅니다.
스크래핑을 허용하지 않는 대표적인 예시로 링크드인을 들 수 있습니다. 링크드인을 스크래핑할 수 있는지 확인하려면 linkedin.com/robots.txt로 접속해 보세요.
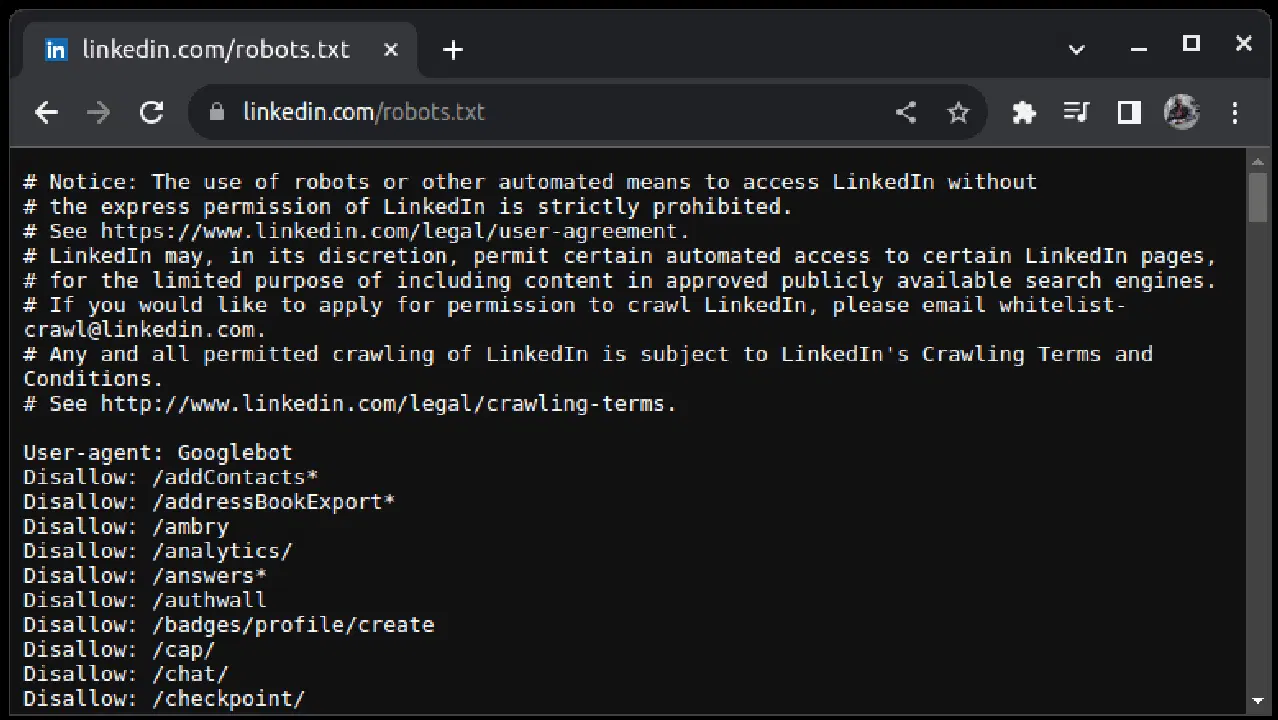
보시다시피, 허가 없이 링크드인을 스크래핑하는 것은 허용되지 않습니다. 법적인 문제를 피하려면, 항상 웹사이트가 스크래핑을 허용하는지 먼저 확인해야 합니다.
자바가 웹 스크래핑에 적합한 이유
웹 스크래퍼는 다양한 프로그래밍 언어로 개발할 수 있지만, 자바는 여러 가지 이유로 특히 효과적입니다. 먼저, 자바는 풍부한 생태계와 광범위한 커뮤니티를 자랑하며, JSoup, WebMagic, HTMLUnit 등 웹 스크래핑을 용이하게 하는 다양한 라이브러리를 제공합니다.

또한, HTML 문서에서 데이터를 추출하는 과정을 단순화하는 HTML 파싱 라이브러리와 여러 웹사이트 URL에 요청을 보내기 위한 HttpURLConnection과 같은 네트워킹 라이브러리를 제공합니다.
자바의 강력한 동시성 및 멀티스레딩 지원은 여러 요청을 포함하는 웹 스크래핑 작업을 병렬로 처리하여 효율성을 높여줍니다. 즉, 여러 페이지를 동시에 스크래핑할 수 있습니다. 자바의 뛰어난 확장성 덕분에 자바로 개발된 웹 스크래퍼는 대규모 웹사이트를 처리하는 데에도 유용합니다.
자바는 크로스 플랫폼을 지원하므로, 웹 스크래퍼를 작성한 후 자바 가상 머신이 설치된 모든 시스템에서 실행할 수 있습니다. 따라서 한 운영체제나 장치에서 개발한 웹 스크래퍼를 다른 운영체제에서 수정 없이 그대로 사용할 수 있습니다.
자바는 Headless Chrome, HTML Unit, Headless Firefox 및 PhantomJs와 같은 헤드리스 브라우저와 함께 사용할 수도 있습니다. 헤드리스 브라우저는 그래픽 사용자 인터페이스가 없는 브라우저입니다. 사용자 상호 작용을 필요로 하는 웹사이트를 스크래핑할 때 유용하게 활용됩니다.
무엇보다도 자바는 널리 사용되는 언어이며, 데이터베이스나 데이터 처리 프레임워크 등 다양한 도구와 쉽게 통합할 수 있습니다. 이는 데이터 스크래핑, 처리, 저장에 필요한 대부분의 도구가 자바를 지원할 가능성이 높다는 것을 의미합니다.
이제 자바를 사용하여 웹 스크래핑을 어떻게 수행할 수 있는지 자세히 살펴보겠습니다.
웹 스크래핑을 위한 자바: 필수 조건
자바를 사용하여 웹 스크래핑을 하려면 다음의 전제 조건이 충족되어야 합니다.
1. 자바 설치: 컴퓨터에 자바가 설치되어 있어야 합니다. 최신 장기 지원 버전 사용을 권장합니다. 자바가 설치되어 있지 않다면, 공식 자바 설치 가이드를 참고하여 설치하세요.
2. 통합 개발 환경(IDE): 컴퓨터에 IDE가 설치되어 있어야 합니다. 이 튜토리얼에서는 IntelliJ IDEA를 사용하지만, 선호하는 IDE를 사용해도 괜찮습니다.
3. Maven: 웹 스크래핑 라이브러리 설치 및 종속성 관리에 사용됩니다.
Maven이 설치되어 있지 않은 경우, 터미널을 열고 다음 명령어를 실행하여 설치할 수 있습니다.
sudo apt install maven
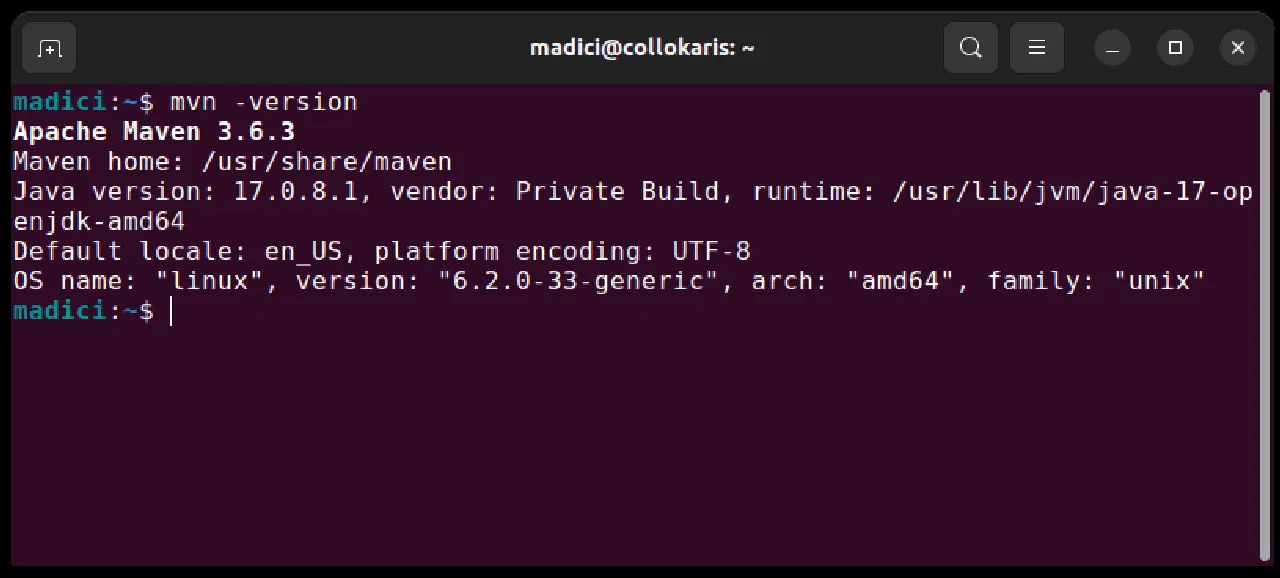
이 명령어는 공식 저장소에서 Maven을 설치합니다. 설치가 완료되었는지 확인하려면 다음 명령어를 실행해 보세요.
mvn -version
설치가 성공적으로 완료되었다면 다음과 같은 결과가 표시됩니다.
개발 환경 설정
개발 환경을 설정하는 방법은 다음과 같습니다.
1. IntelliJ IDEA를 실행합니다. 왼쪽 메뉴에서 '프로젝트'를 클릭한 다음 '새 프로젝트'를 선택합니다.
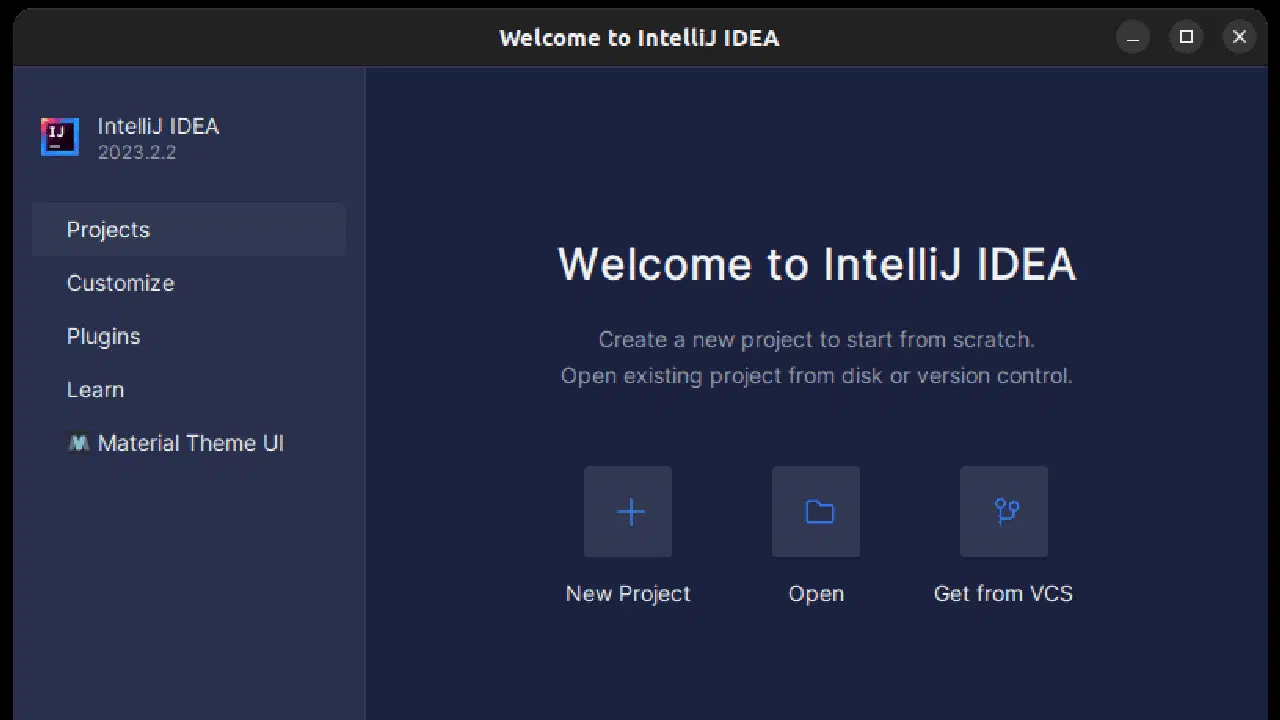
2. 나타나는 '새 프로젝트' 창에서 다음 정보를 입력합니다. '언어'가 자바로, '빌드 시스템'이 Maven으로 설정되어 있는지 확인하세요. 프로젝트 이름을 원하는 대로 지정하고, 프로젝트를 생성할 폴더 위치를 선택합니다. 완료되면 '만들기' 버튼을 클릭합니다.
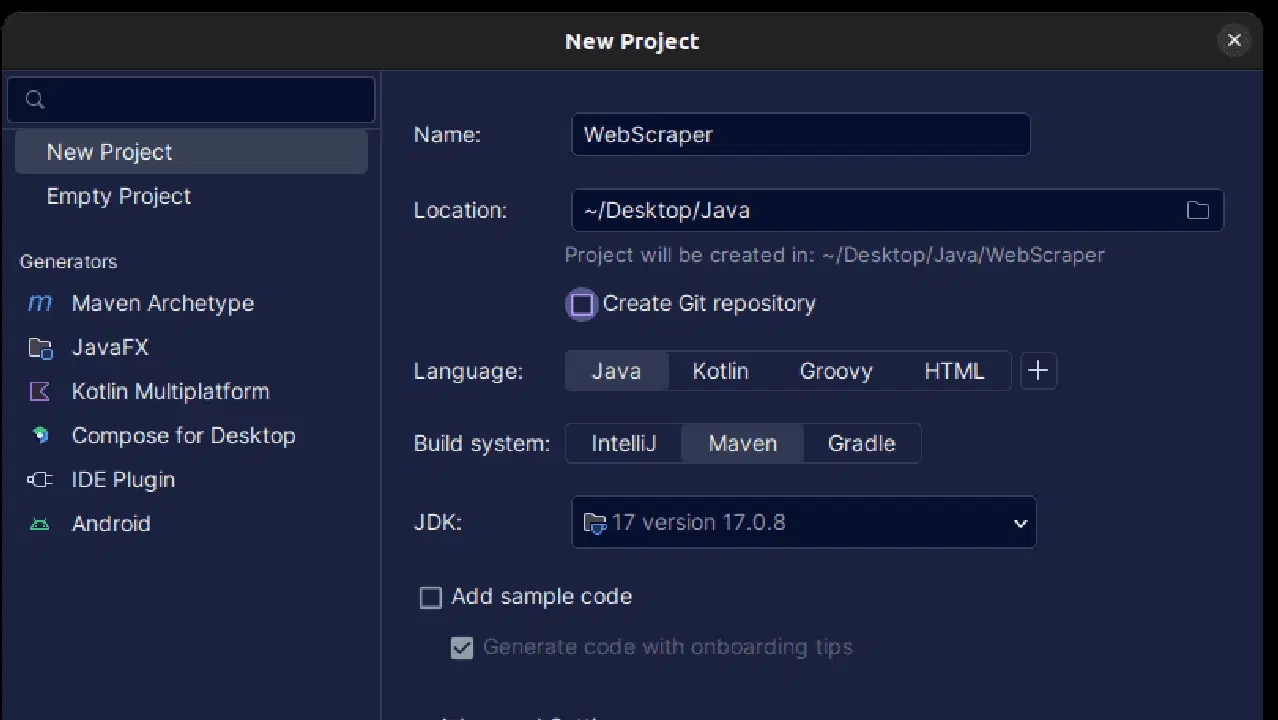
3. 프로젝트가 생성되면 아래와 같이 프로젝트 내부에 'pom.xml' 파일이 생성된 것을 확인할 수 있습니다.
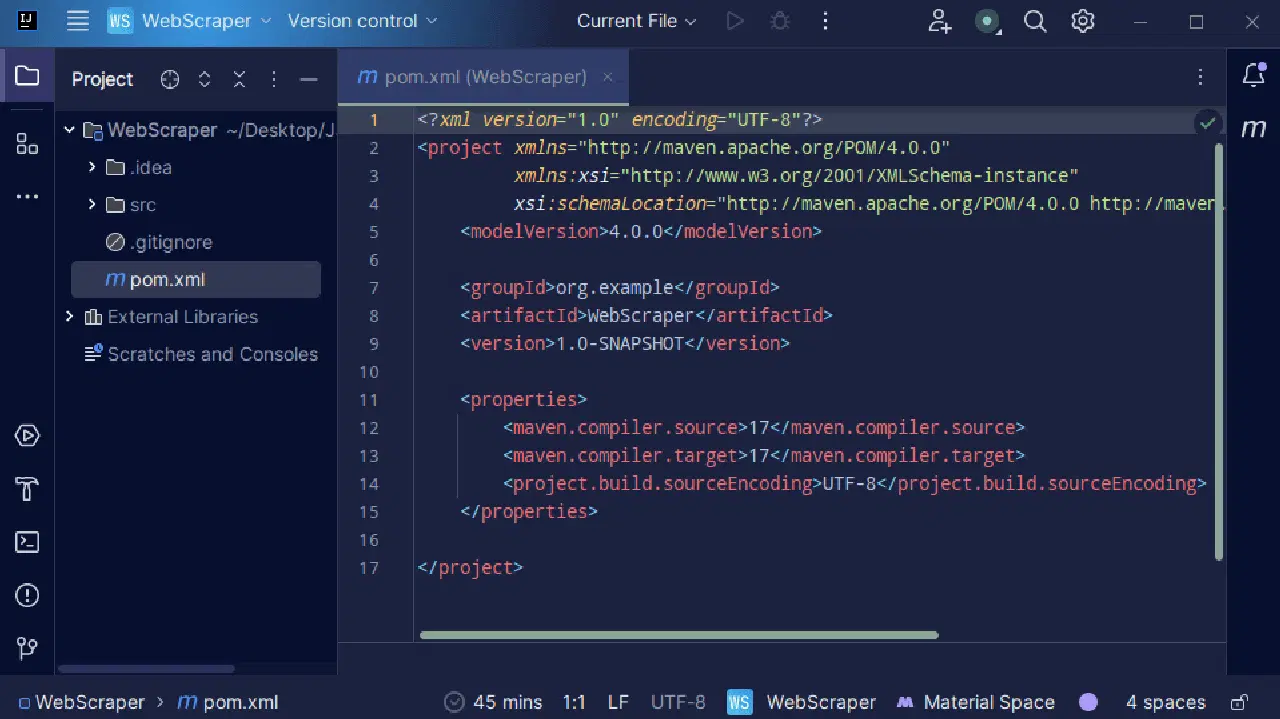
'pom.xml' 파일은 Maven에 의해 자동으로 생성되며, 프로젝트의 구성 정보와 Maven이 프로젝트를 빌드하는 데 필요한 세부 정보를 담고 있습니다. 또한 외부 라이브러리를 프로젝트에서 사용하겠다고 명시하는 데도 사용됩니다.
웹 스크래퍼를 개발할 때에는 jsoup 라이브러리를 사용할 예정입니다. 따라서 Maven이 이 라이브러리를 프로젝트에서 사용할 수 있도록 'pom.xml' 파일에 종속성으로 추가해야 합니다.
4. 아래 코드를 복사하여 'pom.xml' 파일에 추가하여 jsoup 종속성을 추가합니다.
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
결과는 다음과 같아야 합니다.
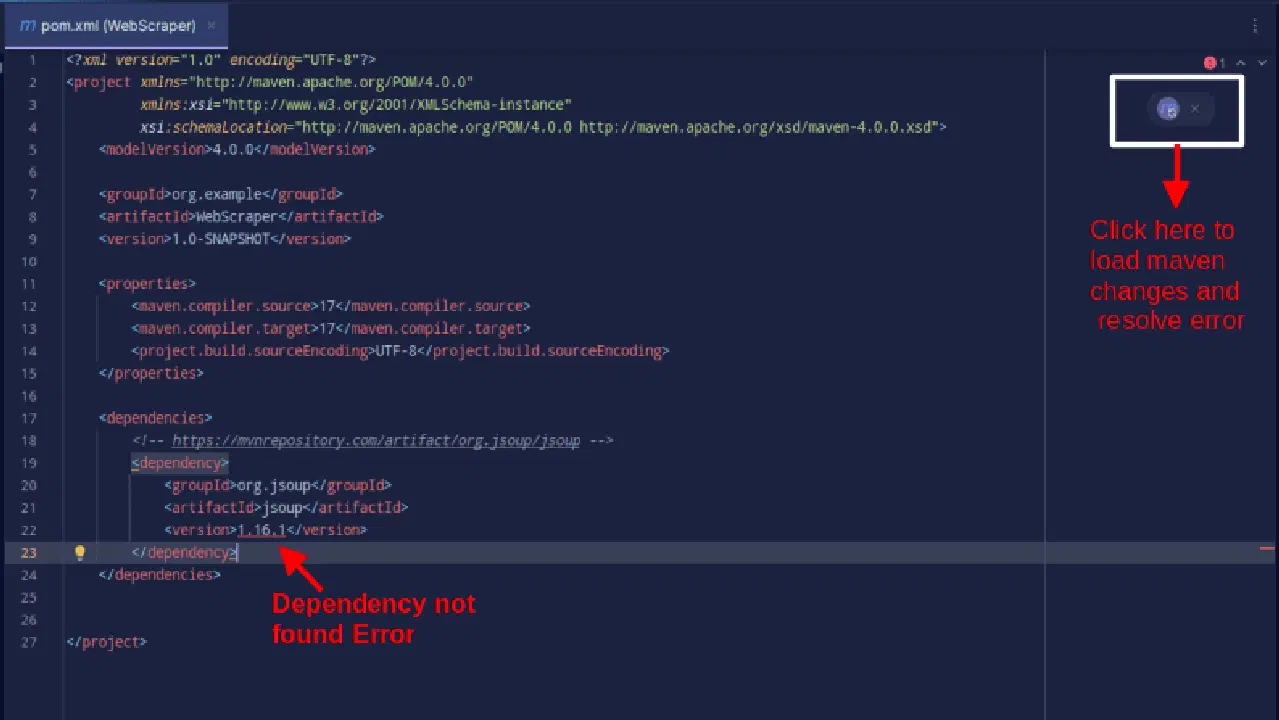
종속성을 찾을 수 없다는 오류가 발생하는 경우, Maven 아이콘을 클릭하여 변경 사항을 로드하고 종속성을 불러온 후 오류를 해결하세요.
이것으로 개발 환경 설정이 완료되었습니다.
자바를 이용한 웹 스크래핑
웹 스크래핑 실습을 위해 다음 웹사이트에서 데이터를 가져올 예정입니다. 이 사이트를 스크랩하세요는 개발자들이 법적 문제없이 웹 스크래핑을 연습할 수 있도록 샌드박스를 제공합니다.
자바로 웹사이트를 스크래핑하는 방법은 다음과 같습니다.
1. IntelliJ의 왼쪽 메뉴에서 'src' 디렉터리를 연 다음, 'src' 디렉터리 안에 있는 'main' 디렉터리를 엽니다. 'main' 디렉터리 안에 'java'라는 디렉터리가 있습니다. 'java' 디렉터리 위에서 마우스 오른쪽 버튼을 클릭하고, '새로 만들기'를 선택한 다음 'Java 클래스'를 선택합니다.
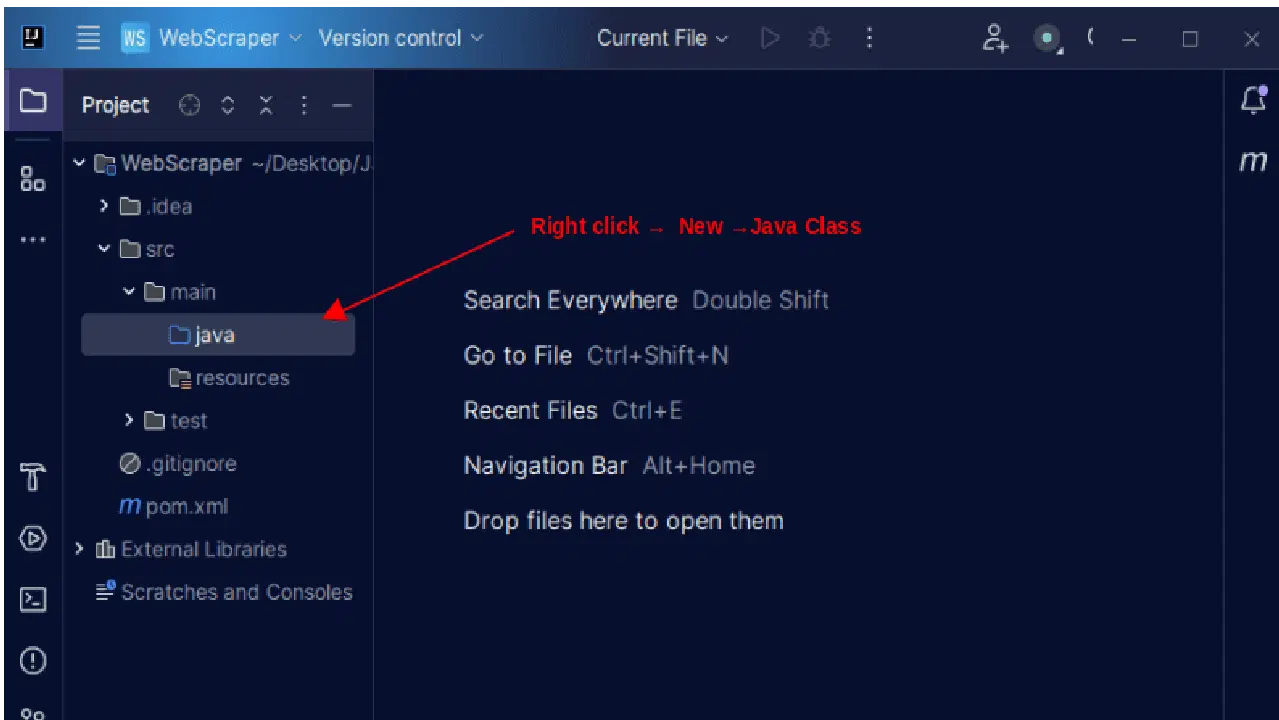
클래스 이름을 'WebScraper'와 같이 원하는 이름으로 지정하고, 'Enter' 키를 눌러 새로운 자바 클래스를 만듭니다.
생성한 자바 클래스가 포함된 새로운 파일을 엽니다.
2. 웹 스크래핑은 웹사이트에서 데이터를 가져오는 작업입니다. 따라서 데이터를 스크래핑할 URL을 지정해야 합니다. URL을 지정한 후에는 해당 URL에 연결하고 GET 요청을 수행하여 페이지의 HTML 콘텐츠를 가져와야 합니다.
이 작업을 수행하는 코드는 다음과 같습니다.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
결과:
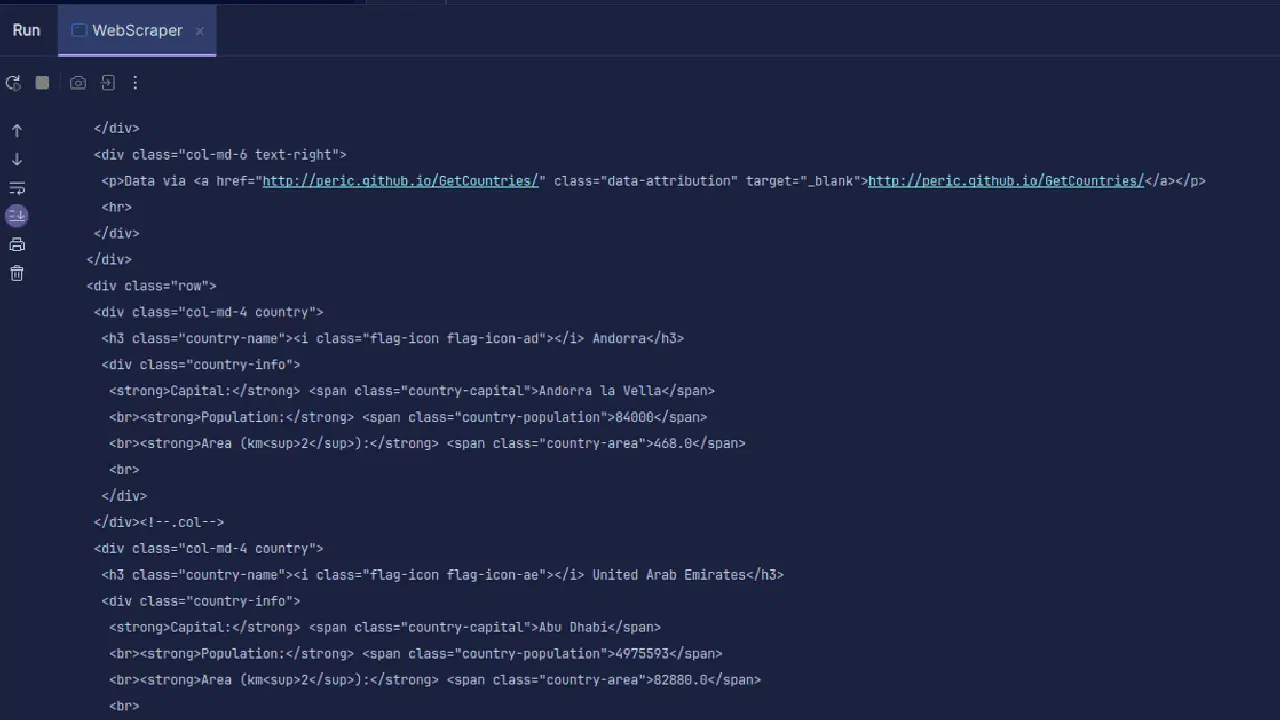
보시다시피, 페이지의 HTML이 반환됩니다. 스크래핑 시 지정한 URL에 오류가 있을 수도 있고, 스크래핑하려는 리소스가 존재하지 않을 수도 있습니다. 그렇기 때문에 코드를 try-catch 문으로 감싸는 것이 중요합니다.
코드:
Document doc = Jsoup.connect(url).get();
은 스크래핑하려는 URL에 연결하는 데 사용됩니다. 'get()' 메소드는 GET 요청을 생성하고 해당 페이지의 HTML 코드를 가져오는 데 사용됩니다. 가져온 HTML 코드는 'doc'라는 이름의 JSOUP Document 객체에 저장됩니다. 이렇게 JSOUP Document 객체에 저장하면 JSOUP API를 사용하여 반환된 HTML 코드를 쉽게 조작할 수 있습니다.
3. 이 사이트를 스크랩하세요에 접속하여 페이지의 구조를 살펴봅시다. HTML 코드에서 다음과 같은 구조를 볼 수 있습니다.
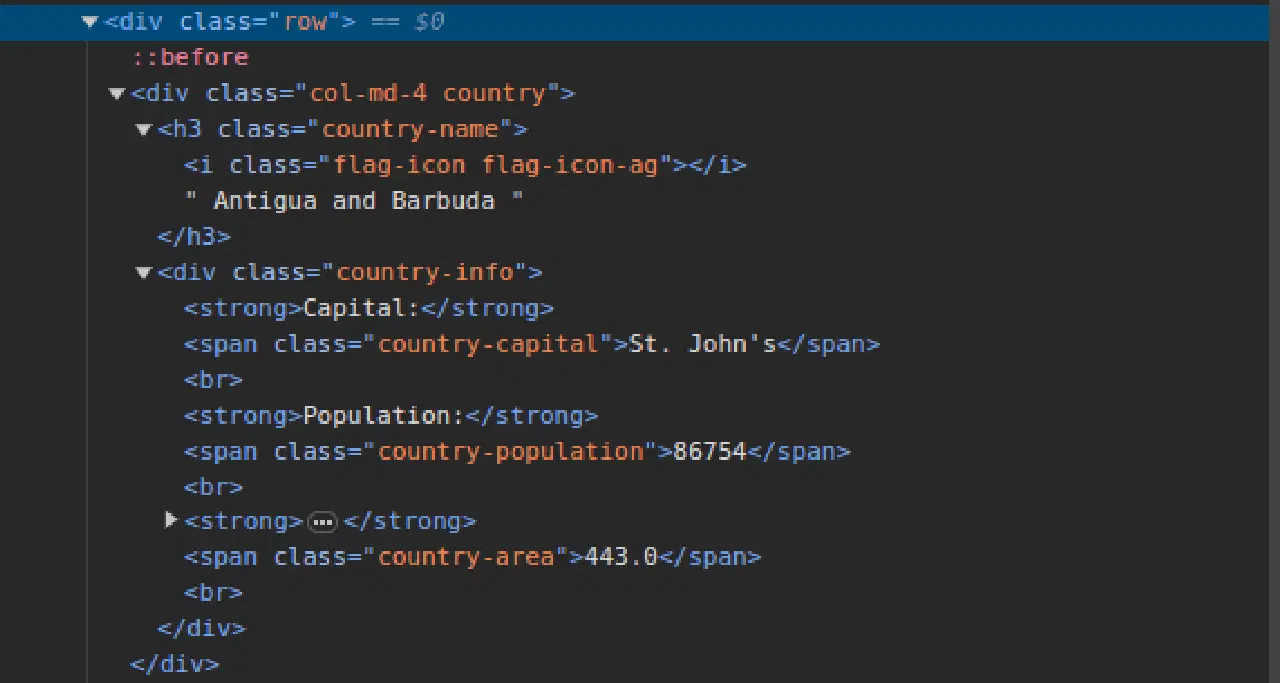
페이지에 있는 모든 국가 정보는 유사한 구조로 저장되어 있습니다. 각 국가의 정보는 'country' 클래스를 가진 'div' 태그로 감싸져 있으며, 그 안에 국가 이름을 포함하는 'country-name' 클래스를 가진 'h3' 요소가 있습니다.
기본 'div' 태그 안에는 수도, 인구, 국토 면적 등 국가 정보를 담고 있는 'country-info' 클래스를 가진 또 다른 'div' 태그가 있습니다. 이러한 클래스 이름을 사용하여 HTML 요소를 선택하고 해당 요소에서 정보를 추출할 수 있습니다.
4. 다음 코드를 사용하여 페이지의 HTML 코드에서 특정 내용을 추출해 보세요.
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " Population - " + population);
}
위 코드에서 'select()' 메소드는 특정 CSS 선택자와 일치하는 HTML 요소들을 선택하는 데 사용됩니다. 여기서는 클래스 이름을 전달합니다. 웹 페이지를 분석해 보면, 모든 국가 정보가 'country' 클래스를 가진 'div' 태그 아래에 저장되어 있음을 알 수 있습니다.
각 국가 정보는 'country' 클래스를 포함하는 'div' 태그 안에 있으며, 그 안에는 국가 이름, 수도, 인구 등의 정보가 있습니다.
따라서 먼저 '.country' 클래스를 사용하여 페이지의 모든 국가 정보를 선택합니다. 그리고 선택된 정보들을 'Elements' 타입의 변수 'countries'에 저장합니다. 'Elements'는 리스트처럼 작동합니다. for 루프를 사용하여 'countries'를 탐색하면서 국가 이름, 수도, 인구를 추출하고 결과를 출력합니다.
전체 코드는 다음과 같습니다.
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Population - " + population);
}
} catch (IOException e) {
System.out.println("An IOException occurred. Please try again.");
}
}
}
결과:
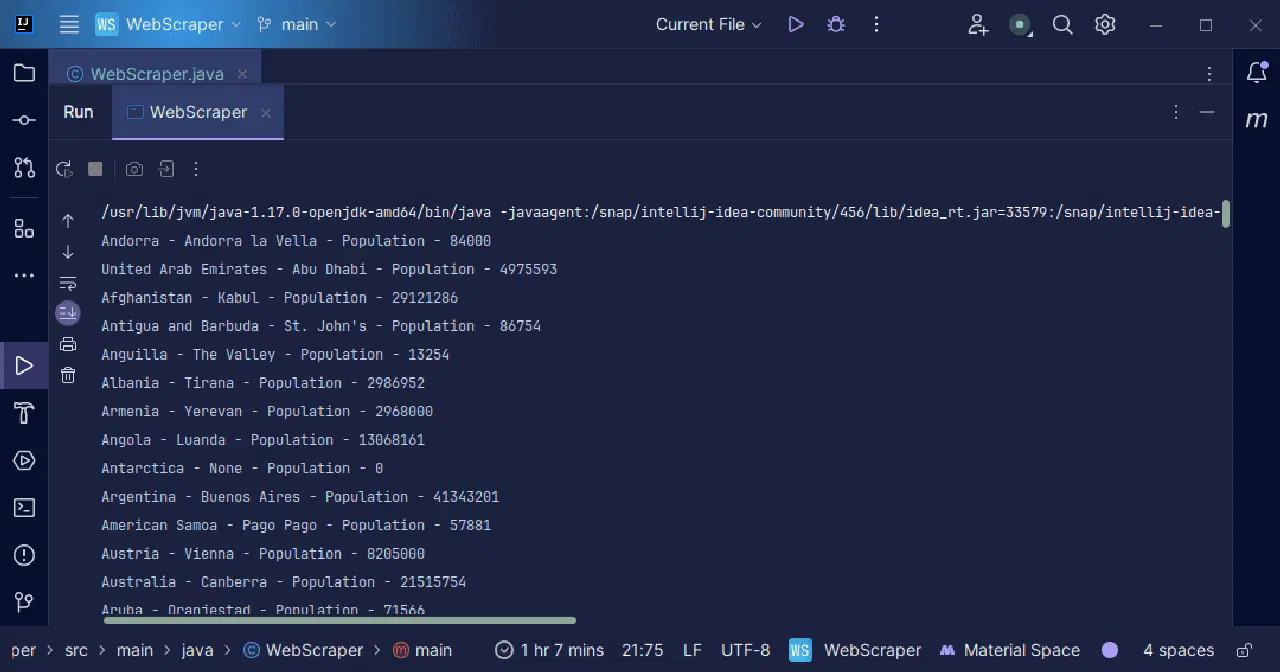
방금 수행한 것처럼 페이지에서 가져온 정보를 출력하거나, 파일에 저장하는 등 추가적인 데이터 처리를 할 수 있습니다.
결론
웹 스크래핑은 웹사이트에서 비정형 데이터를 추출하고, 구조화된 형태로 저장하며, 데이터를 처리하여 유의미한 정보를 얻는 훌륭한 방법입니다. 그러나 일부 웹사이트에서는 웹 스크래핑을 허용하지 않으므로, 웹 스크래핑을 수행할 때는 주의해야 합니다.
안전을 위해 샌드박스를 제공하는 웹사이트를 이용하여 스크래핑 연습을 해보세요. 그렇지 않은 경우에는 항상 스크래핑하려는 웹사이트의 'robots.txt' 파일을 확인하여 해당 웹사이트가 스크래핑을 허용하는지 확인해야 합니다.
웹 스크래퍼를 개발할 때 자바는 웹 스크래핑 작업을 더욱 쉽고 효율적으로 만들어주는 다양한 라이브러리를 제공하므로 매우 좋은 선택입니다. 자바 개발자로서 웹 스크래퍼를 개발하는 것은 프로그래밍 기술을 더욱 향상시키는 데 도움이 됩니다. 그러니 여러분만의 웹 스크래퍼를 직접 개발하거나 이 기사에 사용된 코드를 수정하여 다양한 종류의 정보를 추출해 보세요. 즐거운 코딩 되세요!
클라우드 기반 웹 스크래핑 솔루션도 고려해 볼 수 있습니다.