그것들을 효과적으로 사용하는 방법?
리눅스 환경에서 grep과 정규 표현식(Regex)의 효과적인 활용법
리눅스 운영체제를 오랫동안 사용해 왔다면, 파일 및 디렉토리 내에서 텍스트를 검색하는 데 유용한 도구인 grep(Global Regular Expression Print)에 대해 이미 익숙할 것입니다. grep은 리눅스 고급 사용자에게 매우 유용한 도구이지만, 정규 표현식 없이 사용할 경우 그 기능이 제한적일 수 있습니다.
그렇다면 정규 표현식(Regex)이란 무엇일까요?
정규 표현식(Regex)은 grep 검색 기능을 향상시키는 데 사용되는 패턴입니다. 정의에 따르면 Regex는 고급 출력 필터링 패턴이며, 꾸준한 연습을 통해 다른 리눅스 명령어와 함께 효과적으로 활용할 수 있습니다.
이 튜토리얼에서는 grep과 정규 표현식을 결합하여 어떻게 효과적으로 사용하는지 자세히 알아보겠습니다.
사전 준비
정규 표현식과 함께 grep을 사용하려면 리눅스 운영체제에 대한 기본적인 지식이 필요합니다. 리눅스 초보자라면 먼저 리눅스 가이드를 참조하는 것이 좋습니다. 또한 리눅스 운영체제가 설치된 노트북이나 컴퓨터가 필요합니다. 원하는 리눅스 배포판을 사용할 수 있으며, 윈도우 시스템을 사용하는 경우 WSL2를 통해 리눅스를 사용할 수 있습니다. 자세한 내용은 관련 문서를 참고하시기 바랍니다.
명령줄 또는 터미널에 접근할 수 있다면 grep/regex 튜토리얼에서 제공하는 모든 명령을 실행할 수 있습니다.
또한 예제를 실행하는 데 필요한 텍스트 파일에 대한 접근 권한도 필요합니다. 이 튜토리얼에서는 ChatGPT를 사용하여 기술 관련 내용으로 구성된 텍스트를 생성하고, 그 내용을 tech.txt 파일로 저장하여 사용합니다. ChatGPT에 사용한 프롬프트는 다음과 같습니다.
“기술에 대한 400단어 분량의 텍스트를 생성하세요. 텍스트에는 다양한 기술 용어가 포함되어야 하며, 기술 이름은 반복적으로 사용되어야 합니다.”
마지막으로, grep 명령어에 대한 기본적인 이해가 필수적입니다. grep 명령어에 대한 지식을 복습하려면 16가지 grep 명령어 예제를 참고하거나, 아래 grep 명령어에 대한 간략한 소개를 읽어보세요.
grep 명령어 구문 및 예제
grep 명령어의 기본적인 구문은 다음과 같습니다.
$ grep -옵션 [정규식/패턴] [파일]
보시다시피, grep 명령어는 실행하려는 패턴과 파일 목록을 필요로 합니다.
grep 명령어는 기능을 수정할 수 있는 다양한 옵션을 제공합니다. 주요 옵션은 다음과 같습니다.
-i: 대소문자를 구분하지 않고 검색-r: 하위 디렉토리를 포함한 재귀 검색 수행-w: 전체 단어만 검색-v: 주어진 패턴과 일치하지 않는 모든 줄 표시-n: 일치하는 모든 줄의 줄 번호 표시-l: 일치하는 패턴이 있는 파일 이름 출력--color: 컬러로 결과 출력-c: 사용된 패턴과 일치하는 횟수 표시
#1. 전체 단어 검색
전체 단어 검색을 위해서는 grep 명령어와 함께 -w 옵션을 사용해야 합니다. 이 옵션을 사용하면 주어진 패턴과 정확히 일치하는 단어만 검색할 수 있습니다.
$ grep -w 'tech\|5G' tech.txt
위 명령은 tech.txt 파일에서 "5G"와 "tech"라는 두 단어를 검색하고 결과를 출력하며, 일치하는 단어를 빨간색으로 표시합니다. 여기서 | (파이프 기호)는 grep에 의해 메타 문자로 처리되지 않도록 이스케이프 처리되었습니다.
#2. 대소문자를 구분하지 않는 검색
대소문자를 구분하지 않고 검색하려면 -i 옵션과 함께 grep을 사용합니다.
$ grep -i 'tech' tech.txt
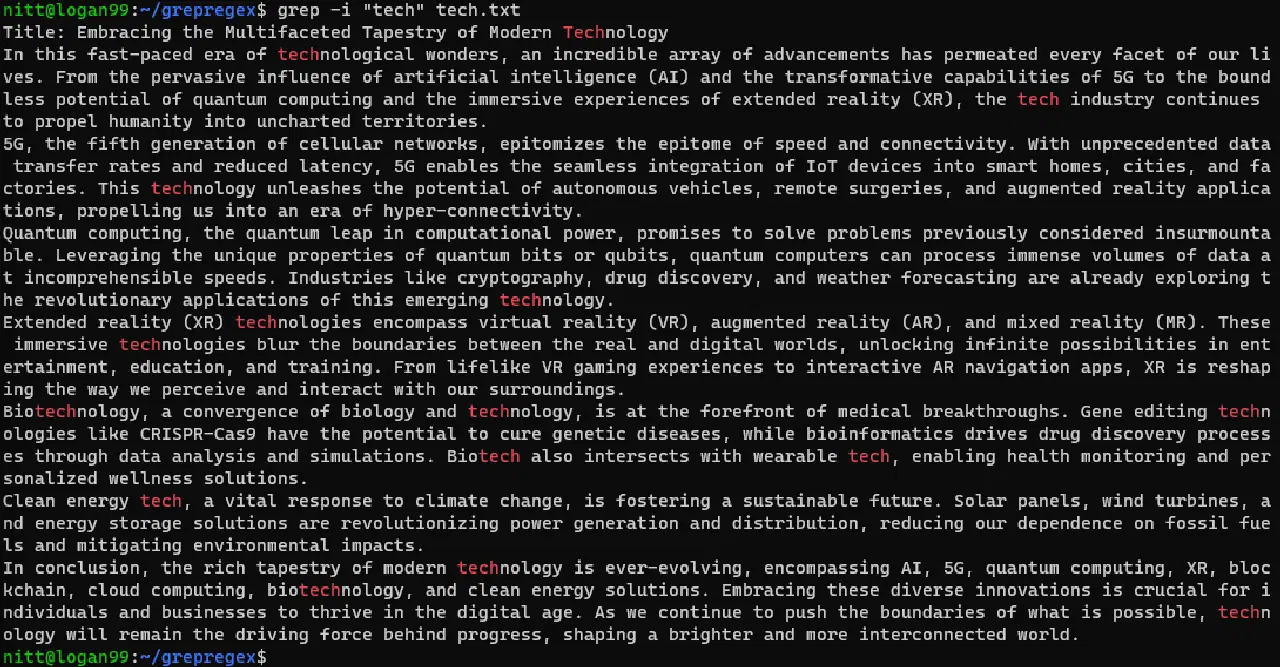
이 명령은 "tech" 문자열의 대소문자를 구분하지 않고, 전체 단어 또는 일부라도 일치하는 모든 인스턴스를 검색합니다.
#3. 일치하지 않는 라인 검색
주어진 패턴을 포함하지 않는 모든 행을 표시하려면 -v 옵션을 사용해야 합니다.
$ grep -v 'tech' tech.txt

출력 결과는 "tech"라는 단어를 포함하지 않는 모든 행을 보여줍니다. 또한 빈 줄도 표시되는데, 이는 단락 뒤에 오는 줄입니다.
#4. 재귀 검색 수행
재귀 검색을 수행하려면 grep 명령어와 함께 -r 옵션을 사용합니다.
$ grep -R 'error\|warning' /var/log/*.log
#출력 /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
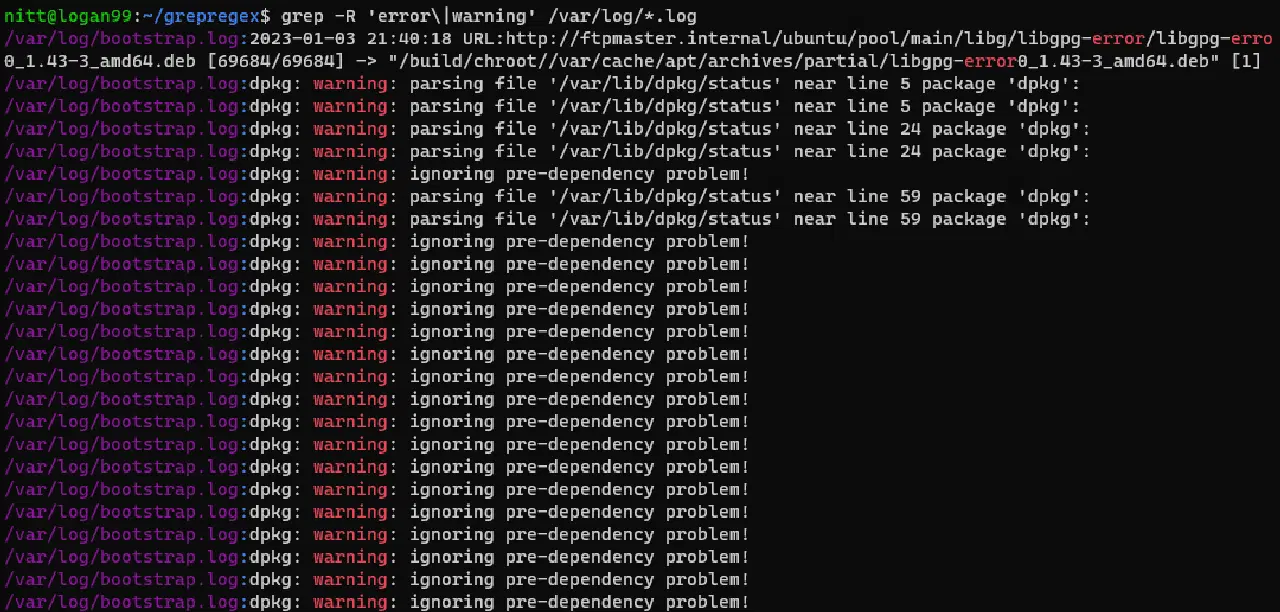
이 명령은 /var/log 디렉토리에서 "error"와 "warning"이라는 단어를 재귀적으로 검색합니다. 로그 파일에서 경고 및 오류를 찾을 때 유용하게 사용할 수 있습니다.
grep과 정규 표현식(Regex): 정의 및 예제
정규 표현식을 사용할 때, 정규 표현식에는 세 가지 구문 옵션이 있다는 것을 알아야 합니다. 이러한 옵션에는 다음과 같은 것들이 있습니다.
- 기본 정규 표현식(BRE)
- 확장 정규 표현식(ERE)
- 펄 호환 정규 표현식(PCRE)
grep 명령어는 기본적으로 BRE를 사용합니다. 따라서 다른 정규 표현식 모드를 사용하려면 해당 모드를 명시해야 합니다. grep 명령어는 또한 메타 문자를 있는 그대로 처리합니다. 따라서 ?, +, )와 같은 메타 문자를 사용하는 경우, 백슬래시(\)를 사용하여 이스케이프 처리해야 합니다.
정규 표현식을 사용한 grep 구문은 다음과 같습니다.
$ grep [정규표현식] [파일이름]
다음 예제를 통해 grep과 정규 표현식이 어떻게 작동하는지 살펴보겠습니다.
#1. 리터럴 단어 매칭
리터럴 단어 매칭을 수행하려면 문자열을 정규 표현식으로 제공해야 합니다. 단어 자체도 정규 표현식이기 때문입니다.
$ grep "technologies" tech.txt

마찬가지로 리터럴 매칭을 사용하여 현재 사용자를 찾을 수도 있습니다. 그렇게 하려면 다음 명령을 실행하십시오.
$ grep bash /etc/passwd
#출력 root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
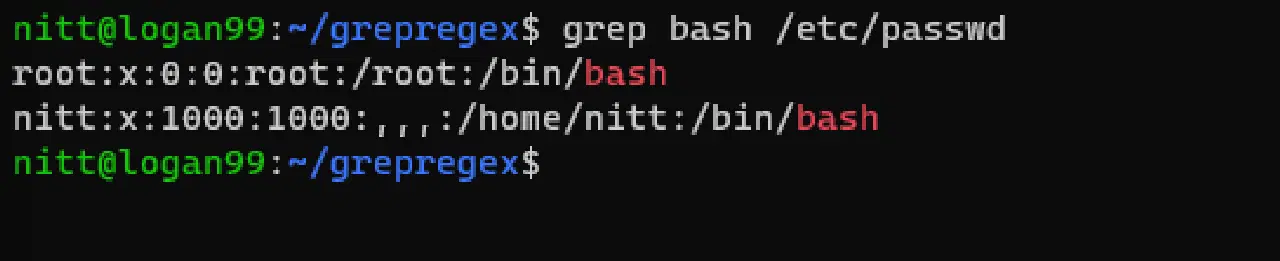
위 출력은 bash에 접근할 수 있는 사용자를 보여줍니다.
#2. 앵커 매칭
앵커 매칭은 특수 문자를 사용하여 고급 검색을 수행하는 유용한 기술입니다. 정규 표현식에는 텍스트 내의 특정 위치를 나타내는 데 사용할 수 있는 다양한 앵커 문자가 있습니다. 주요 앵커 문자는 다음과 같습니다.
^(캐럿 기호): 캐럿 기호는 입력 문자열 또는 줄의 시작 부분과 일치하며 빈 문자열을 찾습니다.$(달러 기호): 달러 기호는 입력 문자열 또는 줄의 끝 부분과 일치하며 빈 문자열을 찾습니다.
다른 두 개의 앵커 매칭 문자에는 \b (단어 경계) 및 \B (비 단어 경계)가 있습니다.
\b(단어 경계):\b를 사용하면 단어와 단어가 아닌 문자 사이의 위치를 지정할 수 있습니다. 간단히 말해서 전체 단어를 매치할 수 있습니다. 이를 통해 부분 일치를 피할 수 있으며, 문자열에서 단어를 바꾸거나 단어 발생 횟수를 세는 데 사용할 수도 있습니다.\B(비 단어 경계):\B는 두 단어 문자 또는 두 개의 비단어 문자 사이의 위치를 지정하므로 정규 표현식에서\b(단어 경계)와 반대되는 역할을 합니다.
더 명확하게 이해하기 위해 몇 가지 예제를 살펴보겠습니다.
$ grep '^From' tech.txt

캐럿을 사용하려면 단어 또는 패턴을 정확한 대소문자로 입력해야 합니다. 왜냐하면 대소문자를 구분하기 때문입니다. 따라서 다음 명령을 실행하면 아무 결과도 반환되지 않습니다.
$ grep '^from' tech.txt
마찬가지로 $ 기호를 사용하여 주어진 패턴, 문자열 또는 단어로 끝나는 문장을 찾을 수 있습니다.
$ grep 'technology.$' tech.txt

^ 및 $ 기호를 모두 결합할 수도 있습니다. 다음 예제를 살펴보겠습니다.
$ grep "^From \| technology.$" tech.txt
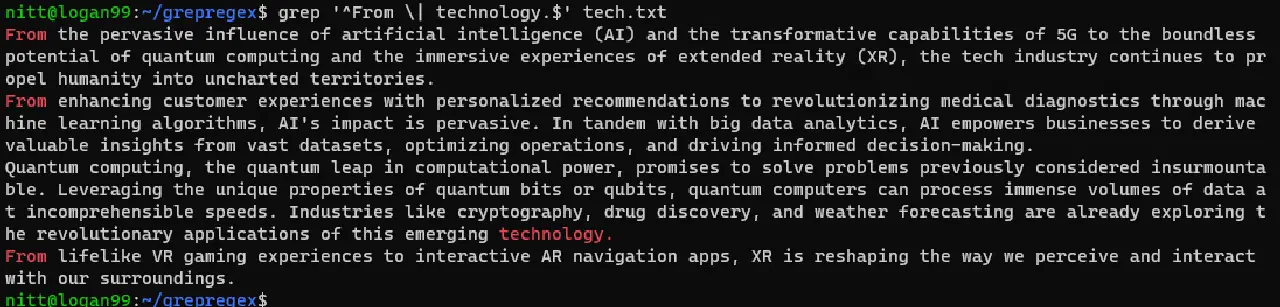
출력 결과는 "From"으로 시작하는 문장과 "technology"로 끝나는 문장을 보여줍니다.
#3. 그룹화
한 번에 여러 패턴을 검색하려면 그룹화를 사용해야 합니다. 그룹화는 단일 단위로 처리할 수 있는 문자 및 패턴의 작은 그룹을 만드는 데 도움이 됩니다. 예를 들어, 't', 'e', 'c', 'h'라는 용어를 포함하는 그룹 (기술)을 만들 수 있습니다.
더 명확하게 이해하기 위해 다음 예제를 살펴보겠습니다.
$ grep 'technol\(ogy\)\?' tech.txt

그룹화를 사용하면 반복되는 패턴과 일치시키고, 그룹을 캡처하고, 대안을 검색할 수 있습니다.
그룹화를 통한 대체 검색
대체 검색의 예를 살펴보겠습니다.
$ grep "\(tech\|technology\)" tech.txt
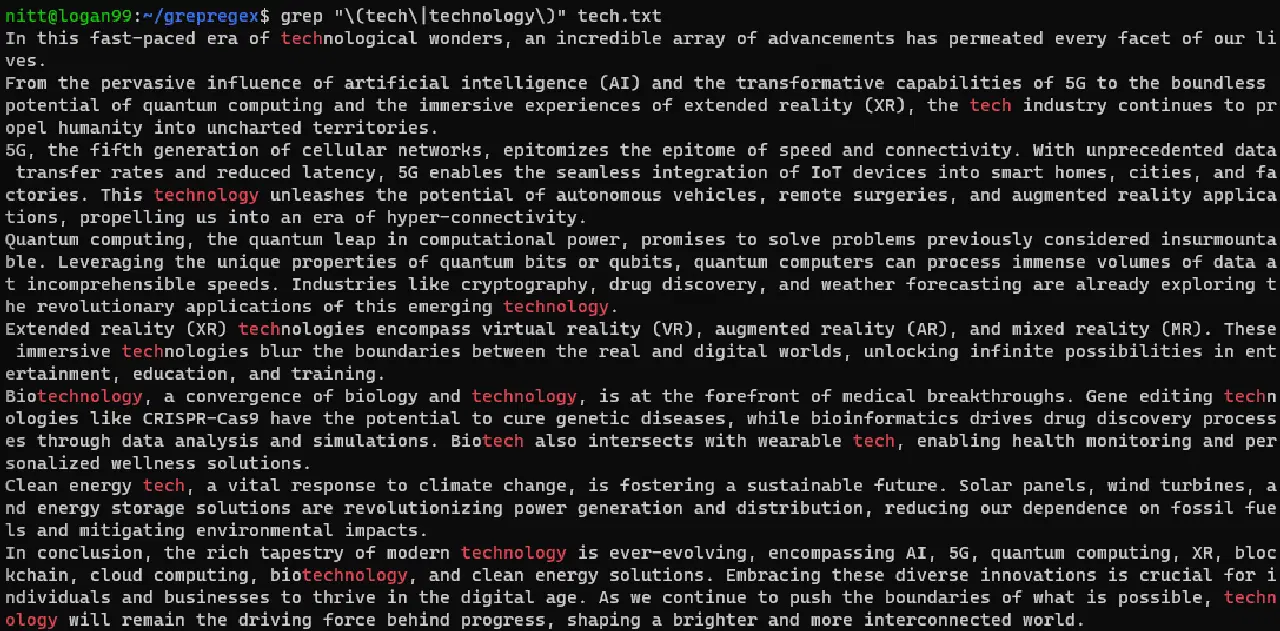
문자열에 대한 검색을 수행하려면 파이프 기호(|)와 함께 문자열을 전달해야 합니다. 아래 예에서 살펴보겠습니다.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#출력 “tech technological technologies technical”

캡처 그룹, 비 캡처 그룹 및 반복 패턴
캡처 및 비 캡처 그룹은 무엇일까요?
정규 표현식에서 그룹을 만들고 캡처하려면 문자열이나 파일에 전달해야 합니다.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#출력 tech655 tech655nical technologies655 tech655-oriented 655

그리고 비 캡처 그룹의 경우 괄호 안에 ?:를 사용해야 합니다.
마지막으로 반복되는 패턴이 있습니다. 반복되는 패턴을 확인하려면 정규 표현식을 수정해야 합니다.
$ echo 'teach tech ttrial tttechno attest' | grep '\(t\+\)'
#출력 'teach tech ttrial tttechno attest'
여기서 정규 표현식은 하나 이상의 't' 문자의 인스턴스를 찾습니다.
#4. 문자 클래스
문자 클래스를 사용하면 정규 표현식을 쉽게 작성할 수 있습니다. 이러한 문자 클래스는 대괄호를 사용합니다. 잘 알려진 몇 가지 문자 클래스는 다음과 같습니다.
[:digit:]– 0~9 사이의 숫자[:alpha:]– 알파벳 문자[:alnum:]– 영숫자 문자[:lower:]– 소문자[:upper:]– 대문자[:xdigit:]– 0-9, A-F, a-f를 포함한 16진수[:blank:]– 탭 또는 공백과 같은 공백 문자
등등!
몇 가지 예제를 통해 실제로 확인해 보겠습니다.
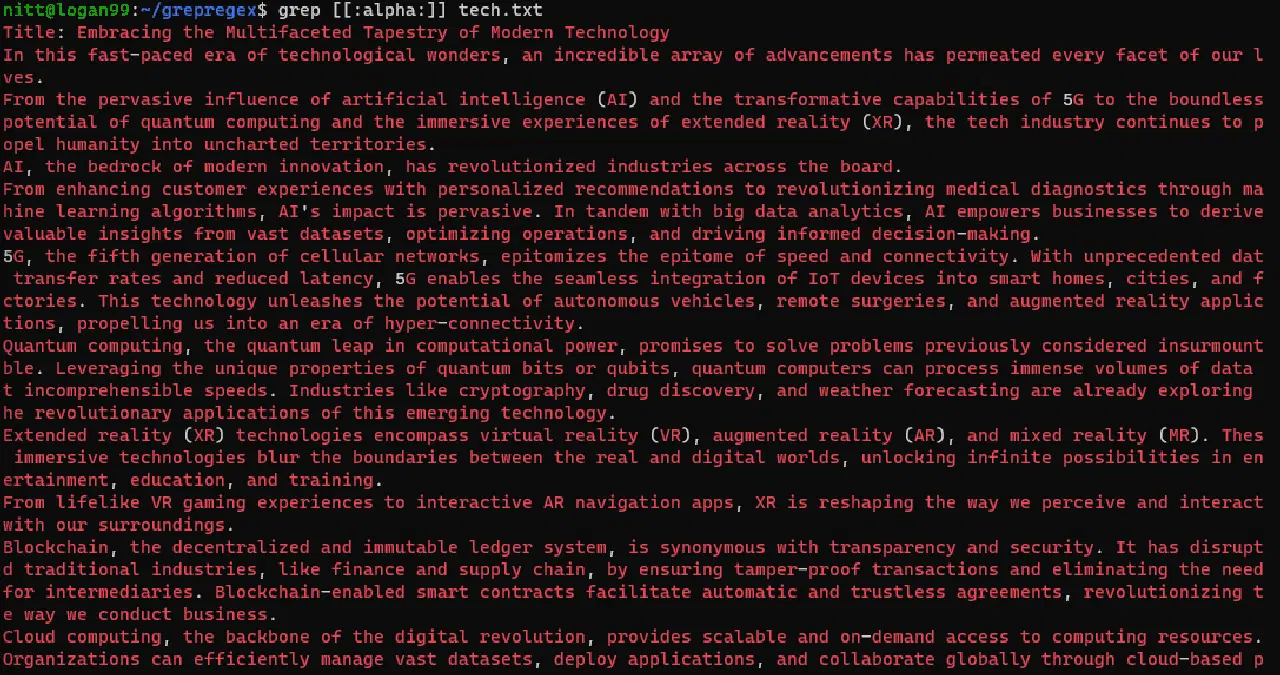
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
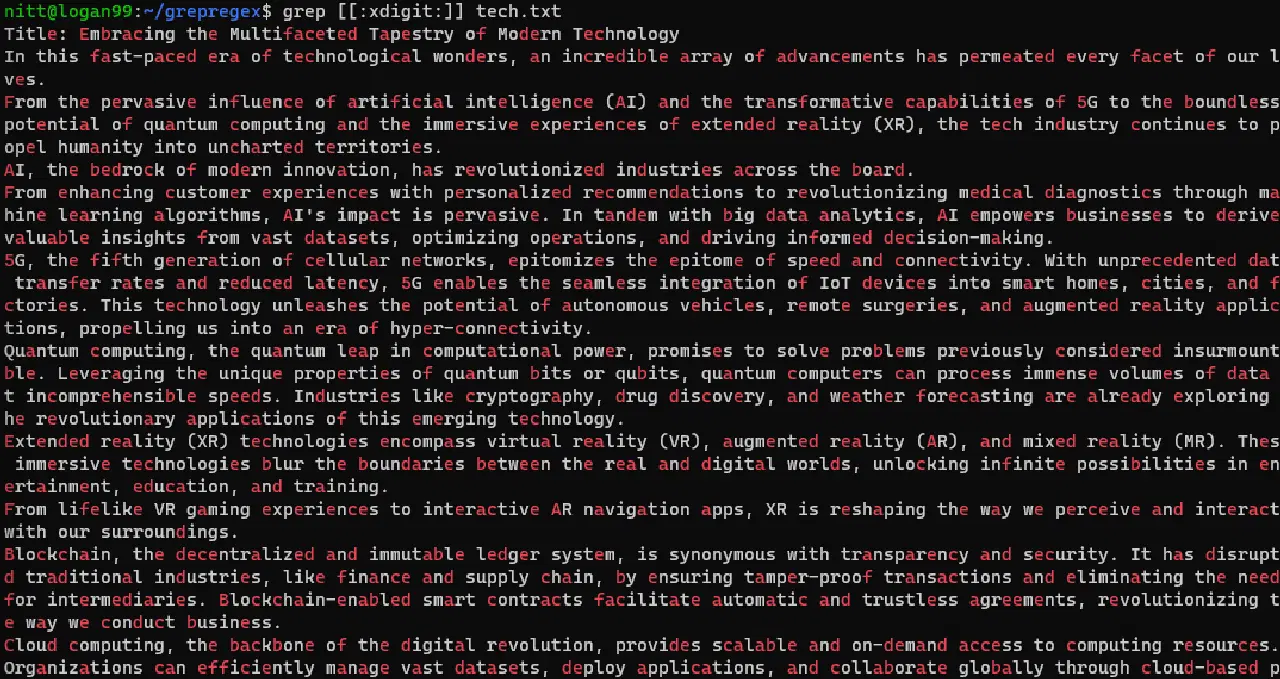
$ grep [[:xdigit:]] tech.txt
#5. 수량자
수량자는 메타 문자이며 정규 표현식의 핵심 요소입니다. 수량자를 사용하면 정확한 매칭 패턴을 지정할 수 있습니다. 주요 수량자는 다음과 같습니다.
*→ 0개 이상의 일치 항목+→ 하나 이상의 일치 항목?→ 0개 또는 1개 일치{x}→ x개의 일치 항목{x, }→ x개 이상의 일치 항목{x,z}→ x개에서 z개까지 일치{, z}→ 최대 z개까지 일치
$ echo 'teach tech ttrial tttechno attest' | grep -E 't+'
#출력 'teach tech ttrial tttechno attest'
위 명령은 하나 이상의 't' 문자의 인스턴스를 검색합니다. 여기서 -E는 확장 정규 표현식을 나타냅니다 (나중에 설명).

#6. 확장 정규 표현식
정규 표현식 패턴에 이스케이프 문자를 추가하는 것이 불편하다면 확장 정규 표현식을 사용해야 합니다. 확장 정규 표현식에서는 이스케이프 문자를 추가할 필요가 없습니다. 확장 정규 표현식을 사용하려면 -E 플래그를 사용해야 합니다.
$ grep -E 'in+ovation' tech.txt

#7. PCRE를 사용하여 복잡한 검색 수행
PCRE(Perl 호환 정규 표현식)를 사용하면 기본적인 표현식을 작성하는 것보다 더 많은 작업을 수행할 수 있습니다. 예를 들어 [0-9]을 나타내는 \d를 사용할 수 있습니다.
예를 들어, PCRE를 사용하여 이메일 주소를 검색할 수 있습니다.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#출력 Contact me at [email protected]

여기서 PCRE는 패턴이 일치하는지 확인합니다. 마찬가지로 PCRE 패턴을 사용하여 날짜 패턴을 확인할 수도 있습니다.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#출력 The Sparkain site launched on 2023-07-29

이 명령은 YYYY-MM-DD 형식으로 날짜를 찾습니다. 다른 날짜 형식과 일치하도록 수정할 수도 있습니다.
#8. 교대
대체 매칭을 원하면 이스케이프 처리된 파이프 문자(\|)를 사용할 수 있습니다.
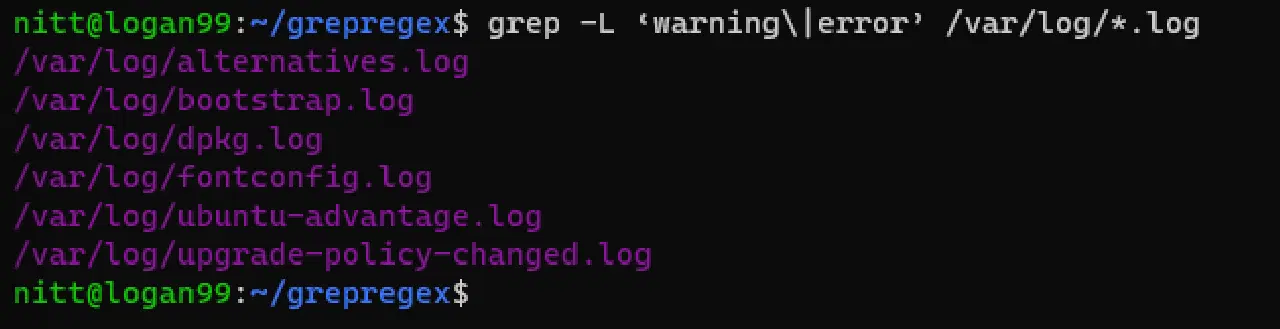
$ grep -L 'warning\|error' /var/log/*.log
#출력 /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
위 출력은 "warning" 또는 "error"를 포함하는 파일 이름을 나열합니다.
마지막 말
이것으로 grep 및 정규 표현식 가이드가 마무리되었습니다. 정규 표현식과 함께 grep을 사용하면 검색을 더욱 구체화할 수 있습니다. 올바르게 사용하면 시간을 절약하고 많은 작업을 자동화할 수 있습니다. 특히 스크립트를 작성하거나 정규 표현식을 사용하여 텍스트를 검색해야 하는 경우 더욱 그렇습니다.
다음으로 자주 묻는 리눅스 인터뷰 질문과 답변을 확인해 보세요.