10 파이썬 데이터 구조 [Explained With Examples]
프로그래밍 작업에 적합한 데이터 구조를 찾고 계신가요? Python의 다양한 데이터 구조를 익혀 첫 걸음을 내딛어 보세요.
새로운 프로그래밍 언어를 배울 때, 그 언어가 제공하는 기본적인 데이터 유형과 내장 데이터 구조를 이해하는 것은 매우 중요합니다. 이 Python 데이터 구조 가이드에서는 다음 내용을 자세히 살펴보겠습니다.
- 데이터 구조 활용의 이점
- Python의 핵심 데이터 구조인 리스트, 튜플, 딕셔너리, 세트
- 스택 및 큐와 같은 추상 데이터 타입의 구현
지금 바로 시작해 보겠습니다!
데이터 구조가 왜 중요할까요?
다양한 데이터 구조를 살펴보기 전에, 데이터 구조를 사용하는 것이 어떤 이점을 제공하는지 먼저 알아보겠습니다.
- 데이터 처리 효율성 향상: 적절한 데이터 구조를 선택하면 데이터를 더욱 효율적으로 처리할 수 있습니다. 예를 들어, 조회 시간이 일정하고 데이터가 밀접하게 연관된 동일한 유형의 항목들을 저장해야 할 때는 배열을 사용하는 것이 유리합니다.
- 메모리 관리 최적화: 대규모 프로젝트에서는 동일한 데이터를 저장하는 데 있어 특정 데이터 구조가 다른 구조보다 메모리 효율성이 높을 수 있습니다. Python에서는 리스트와 튜플 모두 동일하거나 다양한 데이터 유형의 모음을 저장할 수 있습니다. 하지만 컬렉션의 내용이 변경될 필요가 없다면, 리스트보다 메모리 사용량이 적은 튜플을 선택하는 것이 좋습니다.
- 코드 구성 개선: 특정 기능에 최적화된 데이터 구조를 사용하면 코드를 더욱 체계적으로 구성할 수 있습니다. 다른 개발자들은 특정 작업에 적합한 데이터 구조를 사용할 것이라고 기대하며 코드를 읽게 됩니다. 예를 들어, 키-값 매핑이 필요하고 조회 및 삽입 시간이 일정한 경우에는 딕셔너리를 사용하는 것이 적합합니다.
리스트
코딩 인터뷰에서부터 실제 애플리케이션까지, Python에서 동적 배열이 필요할 때 리스트는 가장 먼저 떠오르는 데이터 구조입니다.
Python 리스트는 가변적이며 동적인 컨테이너 데이터 유형으로, 복사본을 만들지 않고도 요소를 추가하거나 제거할 수 있습니다.
Python 리스트 사용 시 고려 사항:
- 리스트의 특정 인덱스에 있는 요소에 접근하는 것은 상수 시간 연산입니다.
- 리스트 끝에 요소를 추가하는 것 역시 상수 시간 연산입니다.
- 특정 인덱스에 요소를 삽입하는 것은 선형 시간 연산입니다.
리스트에는 효율적인 작업을 돕는 다양한 메서드들이 있습니다. 다음 코드 예시는 이러한 작업을 수행하는 방법을 보여줍니다.
>>> nums = [5,4,3,2] >>> nums.append(7) >>> nums [5, 4, 3, 2, 7] >>> nums.pop() 7 >>> nums [5, 4, 3, 2] >>> nums.insert(0,9) >>> nums [9, 5, 4, 3, 2]
Python 리스트는 슬라이싱 및 `in` 연산자를 이용한 멤버십 테스트도 지원합니다.
>>> nums[1:4] [5, 4, 3] >>> 3 in nums True
리스트는 유연하고 사용하기 쉬울 뿐만 아니라 다양한 데이터 유형의 요소를 저장할 수 있습니다. Python은 동일한 데이터 유형의 요소를 효율적으로 저장하기 위한 전용 배열 데이터 구조도 제공합니다. 이 내용은 가이드의 뒷부분에서 자세히 살펴보겠습니다.
튜플
Python에서 튜플은 널리 사용되는 또 다른 내장 데이터 구조입니다. 튜플은 일정한 시간에 인덱싱하고 슬라이스할 수 있다는 점에서 Python 리스트와 유사하지만, 불변하기 때문에 직접 수정할 수 없습니다. 다음 코드 예시는 튜플을 사용하여 이러한 특징을 보여줍니다.
>>> nums = (5,4,3,2) >>> nums[0] 5 >>> nums[0:2] (5, 4) >>> 5 in nums True >>> nums[0] = 7 # 올바르지 않은 연산! Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment
따라서 불변 컬렉션을 만들고 효율적으로 처리하려면 튜플을 고려해 보는 것이 좋습니다. 컬렉션을 변경 가능하게 만들어야 하는 경우에는 리스트를 사용해야 합니다.
📋 Python 리스트와 튜플의 유사점과 차이점을 자세히 알아보세요.
배열
배열은 Python에서 비교적 덜 알려진 데이터 구조입니다. 배열은 일정한 시간에 인덱싱하고 선형 시간에 특정 인덱스에 요소를 삽입할 수 있다는 점에서 Python 리스트와 유사합니다.
그러나 리스트와 배열의 주요 차이점은 배열이 단일 데이터 유형의 요소를 저장한다는 것입니다. 따라서 배열은 더 밀접하게 결합되어 있고 메모리 효율성이 더 높습니다.
배열을 생성하려면 내장 `array` 모듈에서 `array()` 생성자를 사용해야 합니다. `array()` 생성자는 요소와 요소의 데이터 유형을 나타내는 문자열을 입력으로 받습니다. 아래 예시에서는 부동 소수점 숫자의 배열인 `nums_f`를 생성합니다.
>>> from array import array
>>> nums_f = array('f',[1.5,4.5,7.5,2.5])
>>> nums_f
array('f', [1.5, 4.5, 7.5, 2.5])
배열은 리스트와 마찬가지로 인덱싱을 통해 요소에 접근할 수 있습니다.
>>> nums_f[0] 1.5
배열은 변경 가능하므로 수정할 수 있습니다.
>>> nums_f[0]=3.5
>>> nums_f
array('f', [3.5, 4.5, 7.5, 2.5])
그러나 요소의 데이터 유형을 변경할 수는 없습니다.
>>> nums_f[0]='zero' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be real number, not str
문자열
Python에서 문자열은 변경 불가능한 유니코드 문자 시퀀스입니다. C와 같은 프로그래밍 언어와 달리 Python에는 전용 문자 데이터 유형이 없습니다. 따라서 단일 문자는 길이가 1인 문자열로 표현됩니다.
앞서 언급했듯이 문자열은 변경할 수 없습니다.
>>> str_1 = 'python' >>> str_1[0] = 'c' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
Python 문자열은 문자열 슬라이싱과 서식 지정에 유용한 다양한 메서드를 제공합니다. 다음은 몇 가지 예시입니다.
>>> str_1[1:4] 'yth' >>> str_1.title() 'Python' >>> str_1.upper() 'PYTHON' >>> str_1.swapcase() 'PYTHON'
⚠ 위의 모든 작업은 문자열의 복사본을 반환하며, 원래 문자열은 변경되지 않는다는 점을 기억해야 합니다. 더 자세한 내용은 Python 문자열 연산 가이드를 참조하세요.
세트
Python에서 세트는 고유하고 해시 가능한 항목의 모음입니다. 세트는 합집합, 교집합, 차집합과 같은 일반적인 집합 연산을 지원합니다.
>>> set_1 = {3,4,5,7}
>>> set_2 = {4,6,7}
>>> set_1.union(set_2)
{3, 4, 5, 6, 7}
>>> set_1.intersection(set_2)
{4, 7}
>>> set_1.difference(set_2)
{3, 5}
세트는 기본적으로 가변적이므로 요소를 추가하거나 수정할 수 있습니다.
>>> set_1.add(10)
>>> set_1
{3, 4, 5, 7, 10}
📚 Python 세트 자세히 알아보기: 코드 예제 전체 가이드
프로즌 세트
불변 세트를 원한다면 프로즌 세트를 사용할 수 있습니다. 프로즌 세트는 기존 세트나 다른 이터러블에서 만들 수 있습니다.
>>> frozenset_1 = frozenset(set_1)
>>> frozenset_1
frozenset({3, 4, 5, 7, 10})
`frozenset_1`은 프로즌 세트이므로 요소를 추가하거나 수정하려고 하면 오류가 발생합니다.
>>> frozenset_1.add(15) Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'frozenset' object has no attribute 'add'
딕셔너리
Python 딕셔너리는 해시 맵과 유사한 기능을 제공합니다. 딕셔너리는 키-값 쌍을 저장하는 데 사용되며, 키는 해시 가능해야 합니다. 즉, 키의 해시 값이 변경되지 않아야 합니다.
딕셔너리를 사용하면 키를 통해 값에 접근하거나, 새 항목을 삽입하거나, 기존 항목을 상수 시간에 삭제할 수 있습니다. 딕셔너리에는 이러한 작업을 수행하는 데 필요한 메서드들이 있습니다.
>>> favorites = {'book':'Orlando'}
>>> favorites
{'book': 'Orlando'}
>>> favorites['author']='Virginia Woolf'
>>> favorites
{'book': 'Orlando', 'author': 'Virginia Woolf'}
>>> favorites.pop('author')
'Virginia Woolf'
>>> favorites
{'book': 'Orlando'}
OrderedDict
Python 딕셔너리는 키-값 매핑을 제공하지만, 원래는 정렬되지 않은 데이터 구조입니다. Python 3.7부터는 요소 삽입 순서가 유지되지만, `collections` 모듈의 `OrderedDict`를 사용하면 순서를 더욱 명시적으로 관리할 수 있습니다.
보시는 것처럼 `OrderedDict`는 키의 순서를 유지합니다.
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['first']='one'
>>> od['second']='two'
>>> od['third']='three'
>>> od
OrderedDict([('first', 'one'), ('second', 'two'), ('third', 'three')])
>>> od.keys()
odict_keys(['first', 'second', 'third'])
defaultdict
Python 딕셔너리 작업을 할 때 발생하는 일반적인 오류 중 하나는, 딕셔너리에 없는 키에 접근하려고 할 때 `KeyError` 예외가 발생하는 것입니다.
하지만 `collections` 모듈의 `defaultdict`를 사용하면 이러한 상황을 기본적으로 처리할 수 있습니다. 딕셔너리에 없는 키에 접근하려고 할 때마다 키가 추가되고 기본 팩토리에서 지정한 기본값으로 초기화됩니다.
>>> from collections import defaultdict >>> prices = defaultdict(int) >>> prices['carrots'] 0
스택
스택은 후입선출(LIFO) 데이터 구조입니다. 스택에서 수행할 수 있는 작업은 다음과 같습니다.
- 스택 맨 위에 요소를 추가하는 푸시 작업
- 스택 맨 위에서 요소를 제거하는 팝 작업
다음 그림은 스택 푸시 및 팝 작업의 작동 방식을 보여줍니다.

리스트를 사용하여 스택 구현하는 방법
Python에서는 Python 리스트를 사용하여 스택 데이터 구조를 구현할 수 있습니다.
스택 동작 | 리스트 동작 | |---|---| | 스택 상단으로 푸시 | `append()` 메서드를 사용하여 리스트 끝에 추가 | | 스택 상단에서 팝 | `pop()` 메서드를 사용하여 마지막 요소를 제거하고 반환 |
아래 코드 예시는 Python 리스트를 사용하여 스택 동작을 구현하는 방법을 보여줍니다.
>>> l_stk = [] >>> l_stk.append(4) >>> l_stk.append(3) >>> l_stk.append(7) >>> l_stk.append(2) >>> l_stk.append(9) >>> l_stk [4, 3, 7, 2, 9] >>> l_stk.pop() 9
Deque를 사용하여 스택 구현하는 방법
스택을 구현하는 또 다른 방법은 `collections` 모듈에서 `deque`를 사용하는 것입니다. Deque는 양방향 큐를 의미하며 양쪽 끝에서 요소를 추가하거나 제거할 수 있습니다.
스택을 시뮬레이션하기 위해 다음을 수행할 수 있습니다.
- `append()`를 사용하여 deque 끝에 요소를 추가
- `pop()`을 사용하여 마지막에 추가된 요소 제거
>>> from collections import deque >>> stk = deque() >>> stk.append(4) >>> stk.append(3) >>> stk.append(7) >>> stk.append(2) >>> stk.append(9) >>> stk deque([4, 3, 7, 2,9]) >>> stk.pop() 9
큐
큐는 선입선출(FIFO) 데이터 구조입니다. 요소는 큐의 끝에 추가되고 큐의 시작 부분(헤드)에서 제거됩니다.
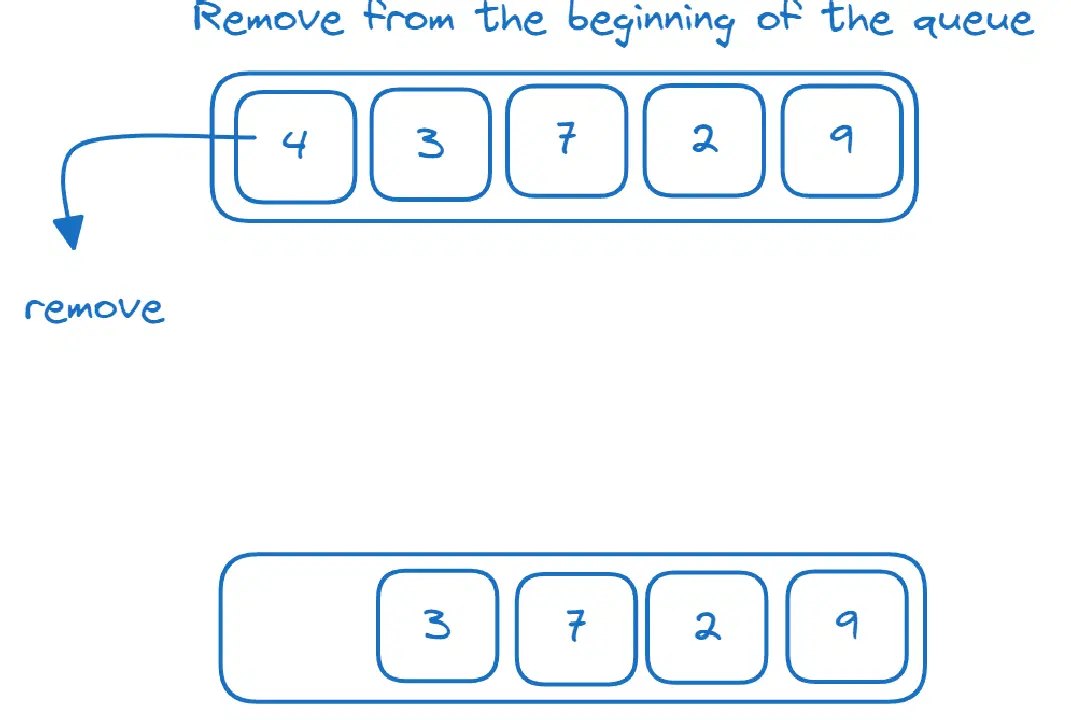
`deque`를 사용하여 큐 데이터 구조를 구현할 수 있습니다.
- `append()`를 사용하여 큐의 끝에 요소 추가
- `popleft()` 메서드를 사용하여 큐의 시작 부분에서 요소 제거
>>> from collections import deque >>> q = deque() >>> q.append(4) >>> q.append(3) >>> q.append(7) >>> q.append(2) >>> q.append(9) >>> q.popleft() 4
힙
이 섹션에서는 이진 힙, 특히 최소 힙에 대해 알아보겠습니다.
최소 힙은 완전 이진 트리입니다. 완전 이진 트리란 다음을 의미합니다.
- 이진 트리는 각 노드가 최대 두 개의 자식 노드를 가지는 트리 데이터 구조입니다. 모든 노드는 자식 노드보다 작습니다.
- 트리는 마지막 레벨을 제외하고 완전히 채워져 있으며, 마지막 레벨은 왼쪽에서 오른쪽으로 채워져 있습니다.
모든 노드에는 최대 두 개의 하위 노드가 있으며, 루트는 항상 최소 힙의 최소 요소가 됩니다.
다음은 최소 힙의 예입니다.
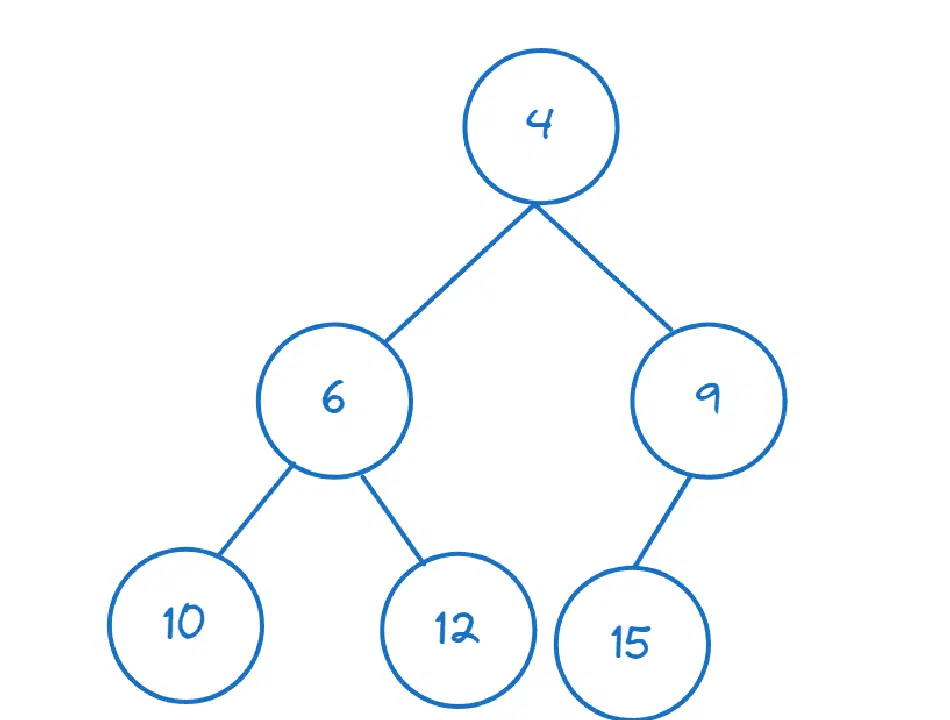
Python의 `heapq` 모듈은 힙을 구성하고 힙 연산을 수행하는 데 유용합니다. 필요한 함수를 가져오겠습니다.
>>> from heapq import heapify, heappush, heappop
리스트나 다른 이터러블이 있다면 `heapify()`를 호출하여 힙을 구성할 수 있습니다.
>>> nums = [11,8,12,3,7,9,10] >>> heapify(nums)
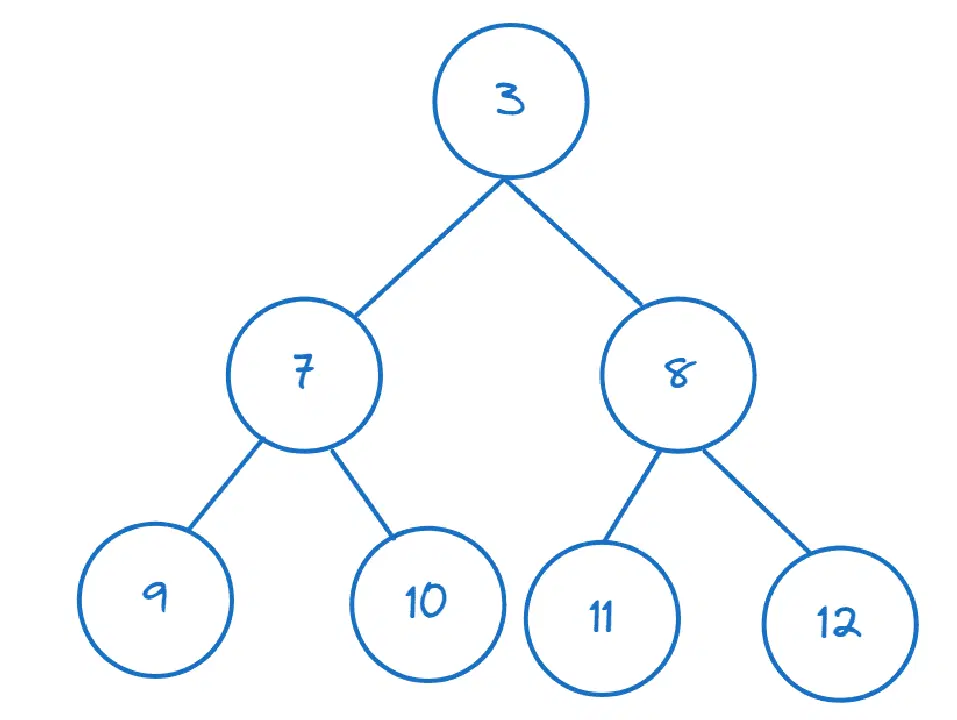
첫 번째 요소를 인덱싱하여 최소 요소인지 확인할 수 있습니다.
>>> nums[0] 3
힙에 요소를 삽입하면 노드가 최소 힙 속성을 만족하도록 재배열됩니다.
>>> heappush(nums,1)
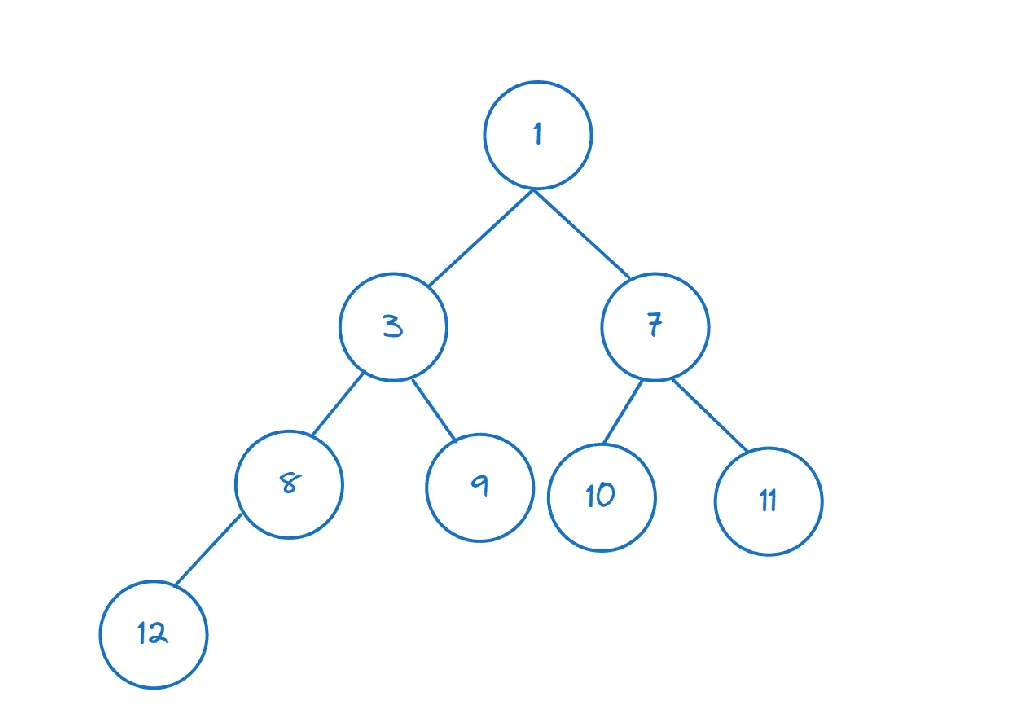
1(1 < 3)을 삽입하면 `nums[0]`은 최소 요소(및 루트 노드)인 1을 반환합니다.
>>> nums[0] 1
`heappop()` 함수를 호출하여 최소 힙에서 요소를 제거할 수 있습니다.
>>> while nums: ... print(heappop(nums)) ...
# 출력 1 3 7 8 9 10 11 12
Python에서 최대 힙 구현하는 방법
최소 힙을 이해했다면, 최대 힙을 구현하는 방법을 짐작할 수 있을 것입니다.
각 숫자에 -1을 곱하여 최소 힙 구현을 최대 힙으로 변환할 수 있습니다. 최소 힙에 배열된 음수는 최대 힙에 배열된 원래 숫자와 동일합니다.
Python 구현에서 `heappush()`를 사용하여 힙에 요소를 추가할 때 요소에 -1을 곱할 수 있습니다.
>>> maxHeap = [] >>> heappush(maxHeap,-2) >>> heappush(maxHeap,-5) >>> heappush(maxHeap,-7)
-1을 곱한 루트 노드가 최대 요소가 됩니다.
>>> -1*maxHeap[0] 7
힙에서 요소를 제거할 때는 `heappop()`을 사용하고 -1을 곱하여 원래 값을 되돌립니다.
>>> while maxHeap: ... print(-1*heappop(maxHeap)) ...
# 출력 7 5 2
우선순위 큐
Python의 우선순위 큐 데이터 구조를 마지막으로 살펴보겠습니다.
큐에서 요소는 큐에 들어온 순서대로 제거됩니다. 그러나 우선순위 큐는 우선순위에 따라 요소를 제공하므로 스케줄링과 같은 애플리케이션에 유용합니다. 우선순위가 가장 높은 요소가 항상 먼저 반환됩니다.
키를 사용하여 우선순위를 정의할 수 있습니다. 여기서는 키에 숫자 가중치를 사용합니다.
heapq를 사용하여 우선순위 큐 구현하는 방법
다음은 `heapq`와 Python 리스트를 사용한 우선순위 큐 구현 예시입니다.
>>> from heapq import heappush,heappop >>> pq = [] >>> heappush(pq,(2,'write')) >>> heappush(pq,(1,'read')) >>> heappush(pq,(3,'code')) >>> while pq: ... print(heappop(pq)) ...
요소를 제거할 때 큐는 우선순위가 가장 높은 요소인 `(1, 'read')`를 먼저 제공하고, 그 다음으로 `(2, 'write')`, `(3, 'code')`를 제공합니다.
# 출력 (1, 'read') (2, 'write') (3, 'code')
PriorityQueue를 사용하여 우선순위 큐 구현하는 방법
우선순위 큐를 구현하기 위해 `queue` 모듈의 `PriorityQueue` 클래스를 사용할 수도 있습니다. 이것 또한 내부적으로 힙을 사용합니다.
다음은 `PriorityQueue`를 사용한 우선순위 큐 구현 예시입니다.
>>> from queue import PriorityQueue >>> pq = PriorityQueue() >>> pq.put((2,'write')) >>> pq.put((1,'read')) >>> pq.put((3,'code')) >>> pq <queue.PriorityQueue object at 0x00BDE730> >>> while not pq.empty(): ... print(pq.get()) ...
# 출력 (1, 'read') (2, 'write') (3, 'code')
정리
이 튜토리얼에서는 Python의 다양한 내장 데이터 구조에 대해 살펴보았습니다. 또한 이러한 데이터 구조에서 지원하는 다양한 연산과 이를 수행하는 내장 메서드들을 알아봤습니다.
더 나아가 스택, 큐, 우선순위 큐와 같은 데이터 구조와 `collections` 모듈의 기능을 활용한 Python 구현도 살펴봤습니다.
다음으로, 초보자에게 친숙한 Python 프로젝트 목록을 확인해 보세요.