
이 자습서에서는 Python 집합의 기본 사항과 Python 집합을 수정하는 데 사용할 수 있는 다양한 집합 메서드를 배웁니다.
집합은 Python의 기본 제공 데이터 구조 중 하나입니다. 반복되지 않는 요소 컬렉션으로 작업해야 하는 경우 집합을 이동 데이터 구조로 사용합니다.
다음 여러 섹션에서 파이썬 집합의 기본 사항과 이를 사용하여 작업할 수 있는 집합 메서드를 살펴보겠습니다. 그런 다음 Python에서 일반적인 집합 연산을 수행하는 방법을 배웁니다.
의 시작하자!
목차
파이썬 세트의 기초
Python에서 집합은 반복되지 않는 요소의 정렬되지 않은 컬렉션입니다. 이는 집합의 요소가 모두 구별되어야 함을 의미합니다.
세트에서 요소를 추가 및 제거할 수 있습니다. 따라서 집합은 변경 가능한 컬렉션입니다. 다른 데이터 유형의 요소를 포함할 수 있습니다. 그러나 집합의 개별 요소는 다음과 같아야 합니다. 해시 가능한.
파이썬에서 객체의 해시 값이 절대 변경되지 않으면 객체를 해시 가능하다고 합니다. Python 문자열, 튜플 및 사전과 같은 대부분의 변경할 수 없는 개체는 해시 가능합니다.
세트 생성에 대해 자세히 알아보겠습니다. 지금은 다음 두 세트를 고려하십시오.
py_set = {0,1,2,(2,3,4),'Cool!'}
py_set = {0,1,2,[2,3,4],'Oops!'}
# Output
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-40-2d3716c7fe01> in <module>()
----> 1 py_set = {0,1,2,[2,3,4],'Oops!'}
TypeError: unhashable type: 'list'
첫 번째 집합에는 세 개의 숫자, 튜플 및 문자열이 포함됩니다. 세트 초기화는 오류 없이 실행됩니다. 반면 두 번째 세트에는 튜플 대신 목록이 포함됩니다. 목록은 변경 가능한 컬렉션이며 해시할 수 없으며 초기화 시 TypeError가 발생합니다.
📑 이 모든 것을 종합하면 Python 집합을 고유하고 해시 가능한 요소의 변경 가능한 컬렉션으로 정의할 수 있습니다.
파이썬 세트를 만드는 방법
Python에서 집합을 만드는 방법을 배우는 것으로 시작하겠습니다.
#1. 명시적 초기화 사용
쉼표(,)로 구분하고 한 쌍의 중괄호 {}로 묶은 집합의 요소를 지정하여 Python에서 집합을 생성할 수 있습니다.
py_set1 = {'Python','C','C++','JavaScript'}
type(py_set1)
# Output
set
이전에 Python 목록으로 작업한 적이 있다면 [] 빈 목록을 초기화합니다. Python 집합이 한 쌍의 중괄호 {}로 묶인 경우에도 {} 쌍을 사용하여 집합을 초기화할 수 없습니다. 이는 {}가 Python 세트가 아니라 Python 사전을 초기화하기 때문입니다.
py_set2 = {}
type(py_set2)
# Output
dict
다시 type() 함수를 호출하여 py_set이 사전(dict)인지 확인할 수 있습니다.
#2. set() 함수 사용
빈 집합을 초기화한 다음 요소를 추가하려면 set() 함수를 사용하면 됩니다.
py_set3 = set() type(py_set3) # Output set
#삼. 다른 이터러블을 세트로 캐스팅하기
집합을 만드는 또 다른 방법은 set(iterable)을 사용하여 목록 및 튜플과 같은 다른 이터러블을 집합으로 캐스팅하는 것입니다.
py_list = ['Python','C','C++','JavaScript','C']
py_set4 = set(py_list)
print(py_set4)
# {'C++', 'C', 'JavaScript', 'Python'} # repeating element 'C' removed
type(py_set4)
# set
위의 예에서 py_list는 ‘C’를 두 번 포함합니다. 그러나 py_set4에서 ‘C’는 집합이 고유한 요소의 모음이므로 한 번만 나타납니다. 집합으로 캐스팅하는 이 기술은 종종 Python 목록에서 중복을 제거하는 데 사용됩니다.
Python 세트에 요소를 추가하는 방법
빈 집합 py_set을 생성하여 시작하고 이 자습서의 나머지 부분에서 작업해 보겠습니다.
py_set = set() len(py_set) # returns the length of a set # Output 0
#1. .add() 메서드 사용
세트에 요소를 추가하려면 .add() 메서드를 사용할 수 있습니다. set.add(element)는 집합에 요소를 추가합니다.
명확성을 위해 Python 세트에 요소를 추가하고 각 단계에서 세트를 인쇄합니다.
▶️ py_set에 ‘Python’ 문자열을 요소로 추가해 봅시다.
py_set.add('Python')
print(py_set)
# Output
{'Python'}
다음으로 다른 요소를 추가합니다.
py_set.add('C++')
print(py_set)
# Output
{'Python', 'C++'}
.add() 메서드는 요소가 아직 없는 경우에만 집합에 요소를 추가한다는 것을 이해하는 것이 중요합니다. 세트에 추가하려는 요소가 이미 포함되어 있는 경우 추가 작업은 효과가 없습니다.
이를 확인하기 위해 py_set에 ‘C++’를 추가해 보겠습니다.
py_set.add('C++')
print(py_set)
# Output
{'Python', 'C++'}
세트에 ‘C++’가 포함되어 있으므로 추가 작업은 효과가 없습니다.
▶️ 세트에 몇 가지 요소를 더 추가해 봅시다.
py_set.add('C')
print(py_set)
py_set.add('JavaScript')
print(py_set)
py_set.add('Rust')
print(py_set)
# Output
{'Python', 'C++', 'C'}
{'JavaScript', 'Python', 'C++', 'C'}
{'Rust', 'JavaScript', 'Python', 'C++', 'C'}
#2. .update() 메서드 사용
지금까지 한 번에 한 요소씩 기존 집합에 요소를 추가하는 방법을 살펴보았습니다.
요소 시퀀스에 둘 이상의 요소를 추가하려면 어떻게 해야 합니까?
set.update(collection) 구문과 함께 .update() 메서드를 사용하여 컬렉션의 요소를 집합에 추가할 수 있습니다. 컬렉션은 목록, 튜플, 사전 등이 될 수 있습니다.
py_set.update(['Julia','Ruby','Scala','Java'])
print(py_set)
# Output
{'C', 'C++', 'Java', 'JavaScript', 'Julia', 'Python', 'Ruby', 'Rust', 'Scala'}
이 방법은 메모리에 다른 객체를 생성하지 않고 집합에 요소 컬렉션을 추가하려는 경우에 유용합니다.
다음 섹션에서는 집합에서 요소를 제거하는 방법을 알아보겠습니다.
Python 세트에서 요소를 제거하는 방법
다음 세트(업데이트 작업 전의 py_set)를 고려해 보겠습니다.
py_set = {'C++', 'JavaScript', 'Python', 'Rust', 'C'}
#1. .pop() 메서드 사용
set.pop()은 세트에서 무작위로 요소를 제거하고 반환합니다. py_set에서 pop 메소드를 호출하고 그것이 무엇을 반환하는지 봅시다.
py_set.pop() # Output 'Rust'
이번에는 .pop() 메서드 호출이 ‘Rust’ 문자열을 반환했습니다.
참고: .pop() 메서드는 임의의 요소를 반환하므로 끝에서 코드를 실행할 때 다른 요소를 얻을 수도 있습니다.
세트를 검사할 때 ‘녹’은 더 이상 세트에 존재하지 않습니다.
print(py_set)
# Output
{'JavaScript', 'Python', 'C++', 'C'}
#2. .remove() 및 폐기() 메서드 사용
실제로는 집합에서 특정 요소를 제거할 수 있습니다. 이렇게 하려면 .remove() 및 .discard() 메서드를 사용할 수 있습니다.
set.remove(element)는 집합에서 요소를 제거합니다.
py_set.remove('C')
print(py_set)
# Output
{'JavaScript', 'Python', 'C++'}
세트에 없는 요소를 제거하려고 하면 KeyError가 발생합니다.
py_set.remove('Scala')
# Output
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-58-a1abab3a8892> in <module>()
----> 1 py_set.remove('Scala')
KeyError: 'Scala'
다시 py_set을 살펴보겠습니다. 이제 세 가지 요소가 있습니다.
print(py_set)
# Output
{'JavaScript', 'Python', 'C++'}
set.discard(element) 구문을 사용하면 .discard() 메서드도 집합에서 요소를 제거합니다.
py_set.discard('C++')
print(py_set)
# Output
{'JavaScript', 'Python'}
그러나 존재하지 않는 요소를 제거하려고 할 때 KeyError를 발생시키지 않는다는 점에서 .remove() 메서드와 다릅니다.
.discard() 메서드를 사용하여 목록에서 ‘Scala'(존재하지 않음)를 제거하려고 하면 오류가 표시되지 않습니다.
py_set.discard('Scala') #no error!
print(py_set)
# Output
{'JavaScript', 'Python'}
Python 세트의 요소에 액세스하는 방법
지금까지 Python 집합에서 요소를 추가하고 제거하는 방법을 배웠습니다. 그러나 집합의 개별 요소에 액세스하는 방법을 아직 보지 못했습니다.
집합은 순서가 지정되지 않은 컬렉션이므로 인덱싱할 수 없습니다. 따라서 인덱스를 사용하여 집합의 요소에 액세스하려고 하면 그림과 같이 오류가 발생합니다.
py_set = {'C++', 'JavaScript', 'Python', 'Rust', 'C'}
print(py_set[0])
# Output
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-27-0329274f4580> in <module>()
----> 1 print(py_set[0])
TypeError: 'set' object is not subscriptable
그렇다면 집합의 요소에 어떻게 액세스합니까?
이를 수행하는 두 가지 일반적인 방법이 있습니다.
- 집합을 반복하고 각 요소에 액세스
- 특정 요소가 집합의 구성원인지 확인
▶️ for 루프를 사용하여 집합 및 액세스 요소를 반복합니다.
for elt in py_set: print(elt) # Output C++ JavaScript Python Rust C
실제로는 in 연산자를 사용하여 주어진 요소가 집합에 있는지 확인하고 싶을 수 있습니다.
참고: 집합의 요소는 요소가 집합에 있으면 True를 반환합니다. 그렇지 않으면 False를 반환합니다.
이 예에서 py_set은 ‘C++’를 포함하고 ‘ Julia’는 포함하지 않으며 in 연산자는 각각 True 및 False를 반환합니다.
'C++' in py_set # True 'Julia' in py_set # False
파이썬 세트의 길이를 찾는 방법
앞에서 보았듯이 len() 함수를 사용하여 집합에 있는 요소의 수를 가져올 수 있습니다.
py_set = {'C++', 'JavaScript', 'Python', 'Rust', 'C'}
len(py_set)
# Output: 5
파이썬 세트를 지우는 방법
모든 요소를 제거하여 집합을 지우려면 .clear() 메서드를 사용할 수 있습니다.
py_set에서 .clear() 메소드를 호출합시다.
py_set.clear()
출력하려고 하면 set()이 표시되며 이는 집합이 비어 있음을 나타냅니다. len() 함수를 호출하여 집합의 길이가 0인지 확인할 수도 있습니다.
print(py_set) # set() print(len(py_set)) # 0
지금까지 Python 세트에서 기본 CRUD 작업을 수행하는 방법을 배웠습니다.
- 생성: set() 함수를 사용하여 유형 캐스팅 및 초기화
- 읽기: 회원 테스트를 위해 루프 및 in 연산자를 사용하여 집합의 요소에 액세스
- 업데이트: 세트에서 요소 추가, 제거 및 세트 업데이트
- 삭제: 집합에서 모든 요소를 제거하여 집합을 지웁니다.
Python 코드로 설명하는 공통 집합 연산
Python 집합을 사용하면 기본 집합 작업도 수행할 수 있습니다. 우리는 이 섹션에서 그들에 대해 배울 것입니다.
#1. Python의 집합 합집합
집합 이론에서 두 집합의 합집합은 두 집합 중 적어도 하나에 있는 모든 요소의 집합입니다. A와 B라는 두 개의 집합이 있는 경우 합집합에는 A에만 있는 요소, B에만 있는 요소, A와 B 모두에 있는 요소가 포함됩니다.
집합의 합집합을 찾으려면 | 연산자 또는 .union() 구문을 사용하는 메서드: setA.union(setB).
setA = {1,3,5,7,9}
setB = {2,4,6,8,9}
print(setA | setB)
# Output
{1, 2, 3, 4, 5, 6, 7, 8, 9}
setA.union(setB)
# Output
{1, 2, 3, 4, 5, 6, 7, 8, 9}
집합 합집합은 가환 연산입니다. 따라서 AUB는 BU A와 동일합니다. .union() 메서드 호출에서 setA와 setB의 위치를 바꿔서 이를 확인하겠습니다.
setB.union(setA)
# Output
{1, 2, 3, 4, 5, 6, 7, 8, 9}
#2. 파이썬에서 집합의 교집합
또 다른 결합 집합 연산은 두 집합 A와 B의 교차입니다. 교차 집합 연산은 A와 B에 있는 모든 요소를 포함하는 집합을 반환합니다.
교집합을 계산하려면 아래 코드 조각에 설명된 대로 & 연산자 또는 .intersection() 메서드를 사용할 수 있습니다.
print(setA & setB)
# Output
{9}
setA.intersection(setB)
# Output
{9}
이 예에서 요소 9는 setA와 setB 모두에 있습니다. 따라서 교차 세트에는 이 요소만 포함됩니다.
집합 합집합과 마찬가지로 집합 교집합도 가환 연산입니다.
setB.intersection(setA)
# Output
{9}
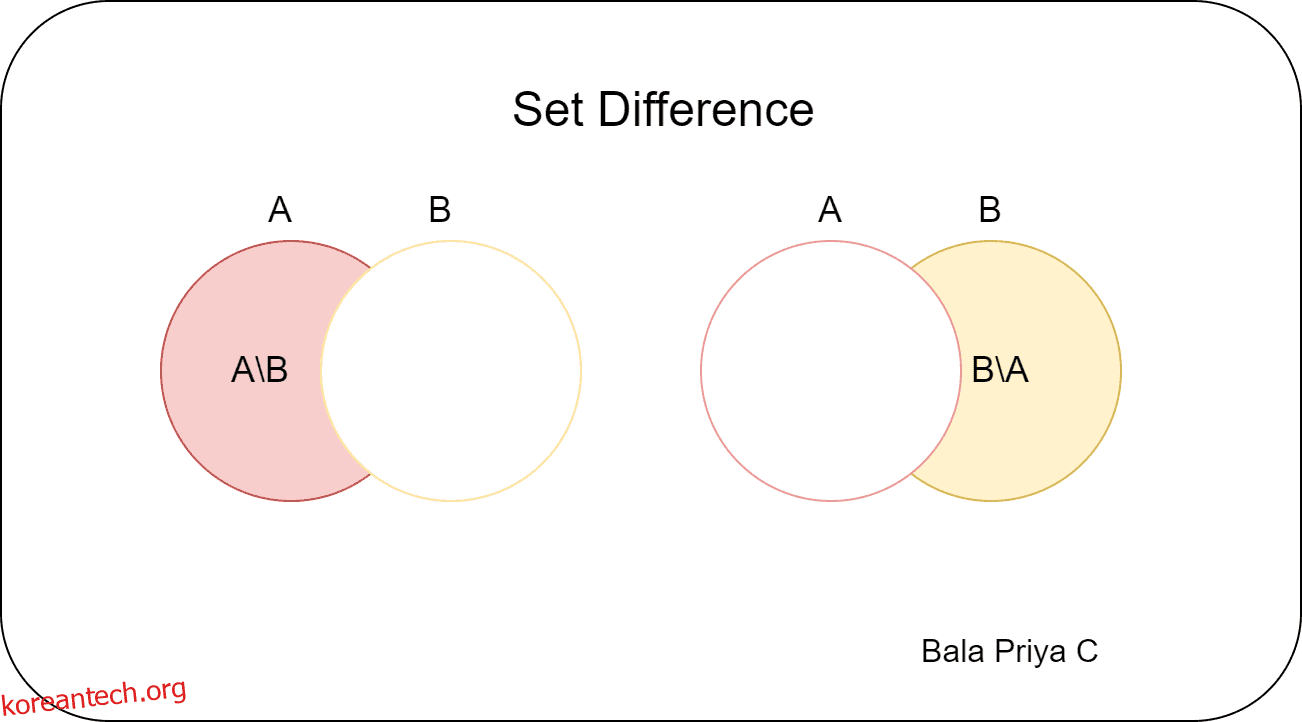
#삼. Python에서 차이 설정
두 집합이 주어졌을 때 합집합과 교집합은 각각 두 집합과 적어도 하나의 집합에 있는 요소를 찾는 데 도움이 됩니다. 반면에 집합 차이는 한 집합에는 있지만 다른 집합에는 없는 요소를 찾는 데 도움이 됩니다.
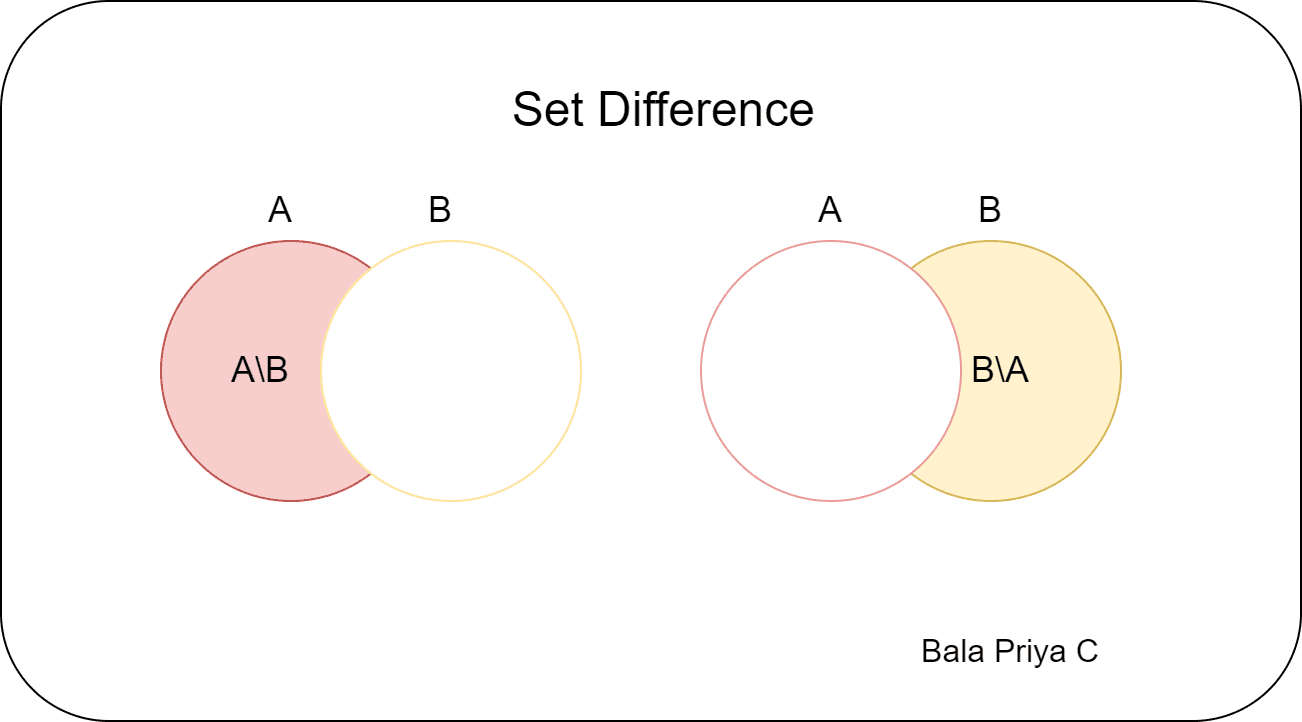
– setA.difference(setB)는 setA에만 있고 setB에는 없는 요소 집합을 제공합니다.
– setB.difference(setA)는 setB에만 있고 setA에는 없는 요소 집합을 제공합니다.
print(setA - setB)
print(setB - setA)
# Output
{1, 3, 5, 7}
{8, 2, 4, 6}
분명히 AB는 BA와 같지 않으므로 집합 차이는 가환 연산이 아닙니다.
setA.difference(setB)
# {1, 3, 5, 7}
setB.difference(setA)
# {2, 4, 6, 8}
#4. Python의 대칭 집합 차이
집합 교차는 두 집합에 있는 요소를 제공하지만 대칭 집합 차이는 정확히 한 집합에 있는 요소 집합을 반환합니다.
다음 예를 고려하십시오.
setA = {1,3,5,7,10,12}
setB = {2,4,6,8,10,12}
대칭 차이 집합을 계산하려면 ^ 연산자 또는 .symmetric_difference() 메서드를 사용할 수 있습니다.
print(setA ^ setB)
# Output
{1, 2, 3, 4, 5, 6, 7, 8}
요소 10과 12는 setA와 setB 모두에 있습니다. 따라서 대칭 차 집합에는 존재하지 않습니다.
setA.symmetric_difference(setB)
# Output
{1, 2, 3, 4, 5, 6, 7, 8}
대칭 집합 차이 연산은 두 집합 중 정확히 하나에 나타나는 모든 요소를 수집하므로 결과 집합은 요소가 수집되는 순서에 관계없이 동일합니다. 따라서 대칭 집합 차이는 가환 연산입니다.
setB.symmetric_difference(setA)
# Output
{1, 2, 3, 4, 5, 6, 7, 8}
#5. Python의 하위 집합과 상위 집합
집합 이론에서 하위 집합과 상위 집합은 두 집합 간의 관계를 이해하는 데 도움이 됩니다.
두 집합 A와 B가 주어졌을 때 집합 B의 모든 요소가 집합 A에도 존재하면 집합 B는 집합 A의 부분집합입니다. 그리고 집합 A는 집합 B의 상위 집합입니다.
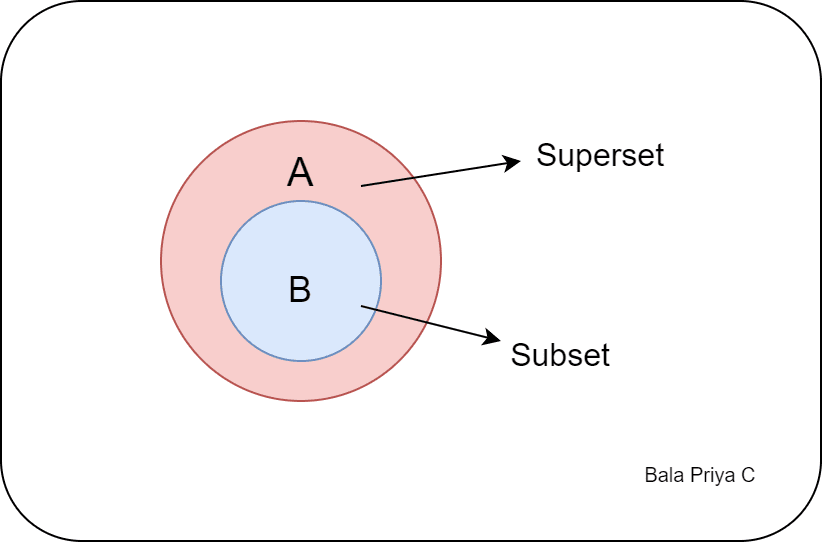
언어 및 언어 확장의 두 가지 예를 고려하십시오.
languages = {'Python', 'JavaScript','C','C++'}
languages_extended = {'Python', 'JavaScript','C','C++','Rust','Go','Scala'}
Python에서는 .issubset() 메서드를 사용하여 주어진 집합이 다른 집합의 하위 집합인지 확인할 수 있습니다.
setA.issubset(setB)는 setA가 setB의 하위 집합이면 True를 반환합니다. 그렇지 않으면 False를 반환합니다.
이 예에서 언어는 languages_extended의 하위 집합입니다.
languages.issubset(languages_extended) # Output True
마찬가지로 .issuperset() 메서드를 사용하여 주어진 집합이 다른 집합의 상위 집합인지 확인할 수 있습니다.
setA.issuperset(setB)는 setA가 setB의 상위 집합이면 True를 반환합니다. 그렇지 않으면 False를 반환합니다.
languages_extended.issuperset(languages) # Output True
Languages_extended는 언어의 상위 집합이므로, 위에서 볼 수 있듯이 languages_extended.issuperset(languages)는 True를 반환합니다.
결론
이 튜토리얼이 파이썬 세트의 작동, CRUD 작업을 위한 세트 메소드 및 일반적인 세트 작업을 이해하는 데 도움이 되었기를 바랍니다. 다음 단계로 Python 프로젝트에서 사용해 볼 수 있습니다.
다른 심층 Python 가이드를 확인할 수 있습니다. 즐거운 배움!